完整目录、平台简介、安装环境及版本:参考《Hive从入门到精通-概览》
九、调优
Hive会将HQL查询语言转换为MapReduce任务,大多数情况下,用户只需要专注手头的事情而不需要了解Hive内部是如何工作的。不过学习Hive背后的理论知识以及底层的一些细节会更有利于用户高效的使用Hive。
9.1 Explain
HiveQL是一种声明式语言,用户提交声明式的查询,而Hive会将其转换成MapReduce job。
使用EXPLAIN可以帮助我们学习Hive是如何将查询转换成MapReduce任务的。在查询语句前面加上explain关键字,可以看到查询计划和其它一些信息。但是这个查询本身是不会执行的。
一个Hive任务会包含一个或者多个stage(阶段),不同的stage会存在依赖关系。越复杂的查询会引入越多的stage,同样耗时也会越多。
一个stage可以是一个MapReduce任务,也可以是一个抽象阶段,或者一个合并阶段,还可以是一个limit阶段,以及Hive需要的其它某个任务的一个阶段。默认情况下,Hive会一次只执行一个stage,不过也可以并行执行。
Stage-1包含了大部分处理过程,而且还会触发一个MapReduce job。
map阶段–Map Operator Tree:TableScan以这个表作为输入,然后会产生一个字段amt_case的输出。Group By Operator会应用到sum(amt_case),然后产生一个输出字段_col0(临时字段)。
reduce阶段–Reduce Operator Tree:相同的Group By Operator,对_col0字段进行sum操作。File Output Operator说明输出结果是文本格式,是基于字符串的输出格式:HiveIgnoreKeyTextOutputFormat
Stage-0一般对应HQL的limit操作。
查询学生最高成绩,最低成绩,平均成绩:
命令:select max(score), min(score), avg(score) from stu_course;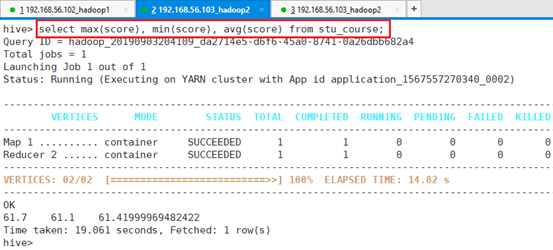
使用explain查看执行过程:
命令:explain select max(score), min(score), avg(score) from stu_course;
Stage-1包含了大部分处理过程,而且还会触发一个MapReduce job。
map阶段–Map Operator Tree:TableScan以表data_query@stu_course作为输入,扫描整个表,然后会产生一个字段[“score”]的输出。Group By Operator会应用到[“max(VALUE._col0)”,”min(VALUE._col1)”,”sum(VALUE._col2)”,”count(VALUE._col3)”],然后产生一个输出字段[“_col0″,”_col1″,”_col2″,”_col3”] (临时字段)。
reduce阶段–Reduce Operator Tree:相同的Group By Operator,对[“_col0″,”_col1″,”_col2″,”_col3”]字段进行[“max(VALUE._col0)”,”min(VALUE._col1)”,”sum(VALUE._col2)”,”count(VALUE._col3)”]操作。File Output Operator说明输出结果是文本格式,是基于字符串的输出格式:HiveIgnoreKeyTextOutputFormat
Limit:-1是因为Job没有Limit语句,因此stage-0阶段是一个没有任何操作的阶段。
9.1.1 Explain extended
可以看到更多更详细的输出信息。
命令:explain extended select max(score), min(score), avg(score) from stu_course;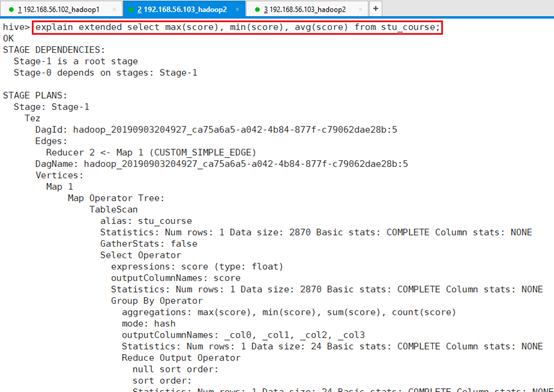
9.2 limit
很多情况下limit命令还需要执行整个查询语句,然后才返回部分结果,这种情况是非常浪费的,Hive可以通过配置进行控制。
将hive.limit.optimize.enable配置为true,同时限制搜索深度。
/hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml
<property>
<name>hive.limit.optimize.enable</name>
<value>false</value>
<description>Whether to enable to optimization to trying a smaller subset of data for simple LIMIT first.</description>
</property><property>
<name>hive.limit.optimize.limit.file</name>
<value>10</value>
<description>When trying a smaller subset of data for simple LIMIT, maximum number of files we can sample.</description>
</property><name>hive.limit.row.max.size</name>
<value>100000</value>
<description>When trying a smaller subset of data for simple LIMIT, how much size we need to guarantee each row to have at least.</description>
</property>查询语句加上limit:
命令:select max(score), min(score), avg(score) from stu_course limit 1;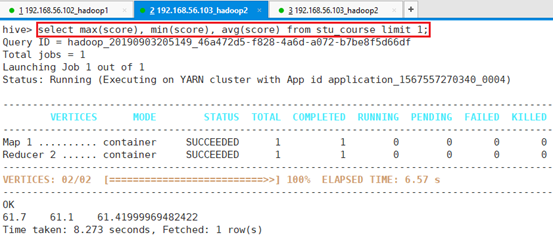
使用explain查看:
命令:explain select max(score), min(score), avg(score) from stu_course limit 1;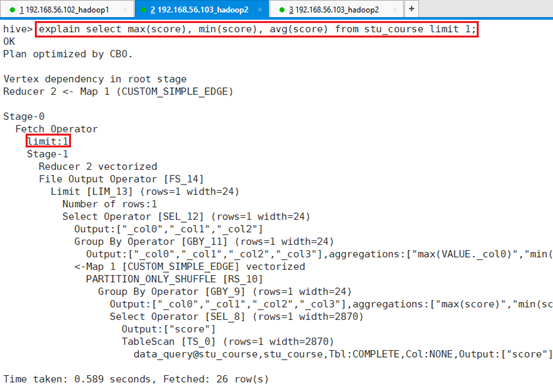
9.3 join优化
由于Hive对每条记录进行连接操作时,会尝试将其他表缓存起来,然后扫描最后那个表进行计算,即假定最后那个表时最大的那个表,因此在连续查询时,表的大小从做到右一次增加。
如果使用过程中没有将最大表放在最后面,还可以通过标记将某个表强行指定为最后表。
式:SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON(c.key = b.key1)a表被视为大表,则首先会对表b和c进行JOIN,然后再将得到的结果与表a进行JOIN。
比如查询学生学号,姓名,学校和成绩,需要用到三个表stu_basic 、stu_course和stu_school
hive> select stu_basic.no, name, school, score
> from stu_basic join stu_course on(stu_basic.no=stu_course.no)
> join stu_school on(stu_basic.no=stu_school.no);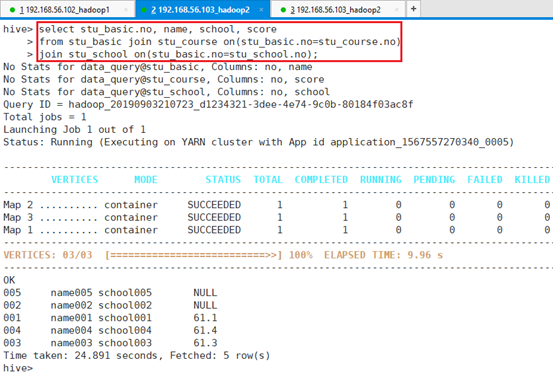
其中stu_basic为最大表,强行将该表stu_basic指定为最后表
hive> select /*+STREAMTABLE(stu_basic)*/ stu_basic.no, name, school, score
> from stu_basic join stu_course on(stu_basic.no=stu_course.no)
> join stu_school on(stu_basic.no=stu_school.no);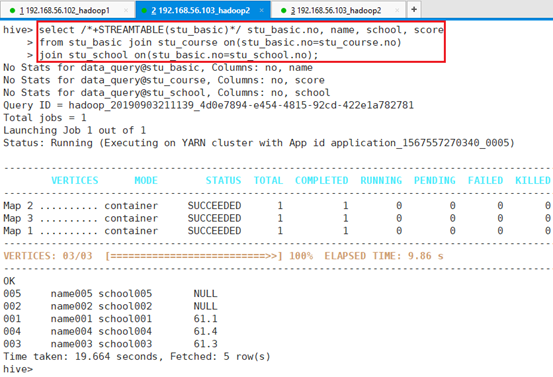
9.4 并行执行
默认情况下,Hive一次只会执行一个阶段,有时候某些Job包含的多个阶段不是相互依赖的,可以并发执行,从而缩短正式时间,提高效率。通过设置配置文件中hive.exec.parallel为true即可。
/hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml
<property>
<name>hive.exec.parallel</name>
<value>false</value>
<description>Whether to execute jobs in parallel</description>
</property>还存在很多其他的调优方式,就不一一介绍了。