完整目录、平台简介、安装环境及版本:参考《Hive从入门到精通-概览》
五、数据定义
Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:内部表(Table),外部表(External Table),分区(Partition),桶(Bucket),视图为逻辑概念,类似于表。

5.1 内部表
内部表有如下特点:
- Table 将数据保存到Hive 自己的数据仓库目录中:/usr/hive/warehouse/数据库名称.db/表名;
- 每一个Table在Hive中数据仓库目录下都有一个相应的目录存储数据;
- 所有的Table数据都存储在该目录;
- 删除表的时候,元数据和数据都会被删除;
5.1.1 创建内部表
5.1.1.1 默认HDFS位置
新建数据库data_define:
命令:create database data_define;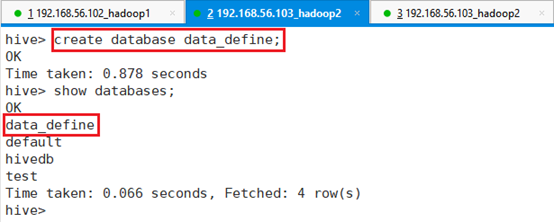
查看新建数据库在HDFS中的目录:
命令:dfs -ls /user/hive/warehouse;
可以看出,新建数据库data_define后,系统会自动在HDFS的/user/hive/warehouse 目录下新建data_define.db目录
切换到该数据库下:
命令:use data_define;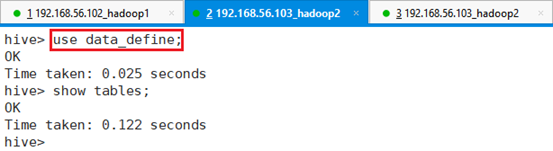
新建表dd001,命令:
hive> create table dd001(
> id int,
> no string,
> name string,
> age int);定位该表在HDFS上的默认位置:
命令:dfs -ls /user/hive/warehouse/data_define.db;
新建表后,系统会自动在数据库data_define的HDFS目录下/user/hive/warehouse/ data_define.db新建表test目录
5.1.1.2 指定HDFS位置
新建数据库是,默认位置为HDFS目录的/user/hive/warehouse下,也可以指定表的HDFS目录。
创建表时,指定HDFS位置,而非目录,命令:
hive> create table dd002(
> id int,
> no string,
> name string,
> age int)location '/hive/db/dd_002';查看目录情况命令:dfs -ls /hive/db;
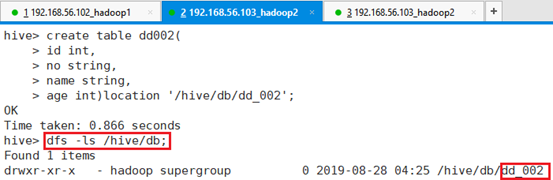
可以看出表dd002被指定放在了/hive/db/dd_002目录下,
查看默认目录/user/hive/warehouse/data_define.db/
确认命令:dfs -ls /user/hive/warehouse/data_define.db;
该目录下并没有表db002信息。
5.1.1.3 导入数据文件
之前创建db001表时,并没有指定字段分隔符,默认情况下字段分隔符为’\t’,这时导入到表db001的数据源必须是’\t’分割开,否则导入不成功。这种缺乏灵活性,毕竟从外部导入数据格式多种多样,Hive在导入时也应该可以灵活控制。
比如之前app-12节点目录/tmp/hive/test.csv数据为’,’分割,希望将这个数据文件导入到表中,这是就不能再用默认分隔符了,需要在建表时指定分隔符。
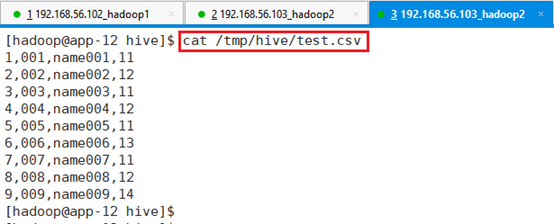
建表db003,用’,’作为分隔符,用/tmp/hive/test.csv文件作为表db003的数据源文件,命令:
hive> create table dd003(
> id int,
> no string,
> name string,
> age int)
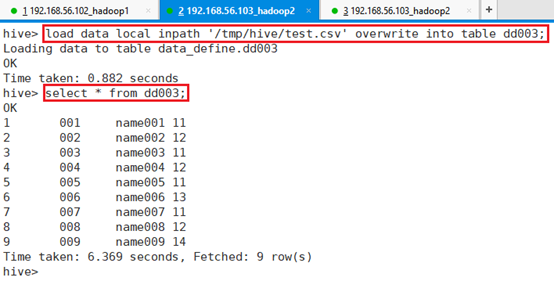
> row format delimited fields terminated by ',';导入/tmp/hive/test.csv文件到表dd003
命令:load data local inpath '/tmp/hive/test.csv' overwrite into table dd003;查看导入结果命令:select * from dd003;
5.1.2 修改表结构
5.1.2.1 增加列
格式:
一次增加一个列(默认添加为最后一列)
ALTER TABLE table_name ADD COLUMNS (new_col INT);
可以一次增加多个列
ALTER TABLE table_name ADD COLUMNS (c1 INT,c2 STRING);
添加一列并增加列字段注释
ALTER TABLE table_name ADD COLUMNS (new_col INT COMMENT 'a comment');比如针对表dd001,增加性别字段,字段类型为boolean
命令:alter table dd001 add columns(sex boolean);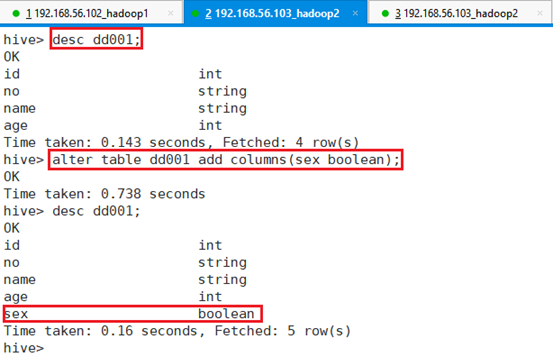
5.1.2.2 修改列名
功能:允许用户更改列的名称、数据类型、注释、位置或它们的任意组合,但必须先存在该字段才能修改名字及指定位置,格式:
ALTER TABLE table_name CHANGE
[CLOUMN] col_old_name col_new_name column_type
[CONMMENT col_conmment]
[FIRST|AFTER column_name]
[CASCADE|RESTRICT];修改字段名,将性别字段sex修改为gender
命令:alter table dd001 change sex gender boolean;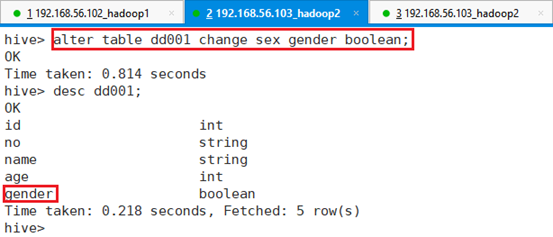
5.1.2.3 修改列类型
修改字段类型,将年龄字段类型由int修改为float
命令:alter table dd001 change age age float;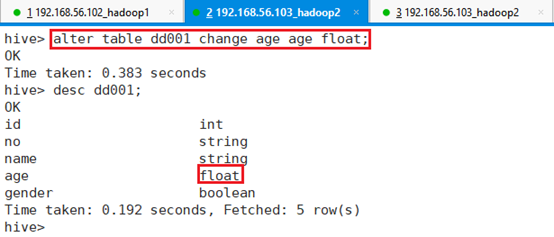
5.1.2.4 列替换
表字段替换:
alter table dd001 replace columns(age float, height double);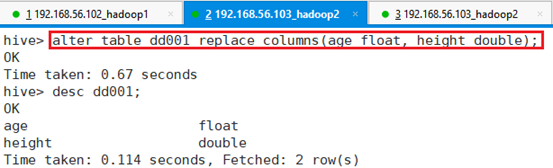
5.1.2.5 修改表名
更改表的名字,将表dd001修改为dd001_1
命令:alter table dd001 rename to dd001_1;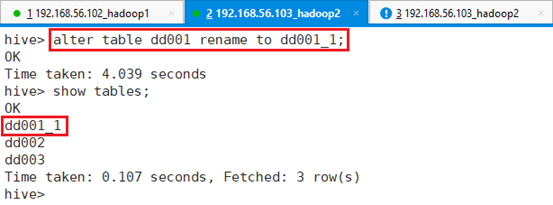
5.1.3 删除内部表
删除表之前先查看数据库data_define在HDFS目录
命令:dfs -ls /user/hive/warehouse/data_define.db;

表dd002被创建在了指定位置/hive/db/dd_002,不在默认目录。
命令:dfs -ls /hive/db;
删除表dd001_1和dd002:
命令:drop table dd001_1;
命令:drop table dd002;
再查看HDFS目录:
命令:dfs -ls /hive/db;
命令:dfs -ls /user/hive/warehouse/data_define.db;
通过前面操作可以看到,删除内部表时,相应的HDFS目录文件也会随之删除。
5.2 外部表
External Table 外部表需要指定数据读取的目录,而内部表创建的时候存放数据到默认路径,内部表将数据和元数据全部删除,外部表只删除元数据,数据文件不会删除。外部表和内部表在元数据的组织上是相同的,也可以创建分区。外部表加载数据和创建表同时完成,并不会移动到数据仓库目录中。
外部表和内部表的应用场景:
- 如果hdfs中已经存在数据文件,推荐使用外部表(使用较多)
- 如果表先创建,之后向表中插入数据,推荐使用内部表
其实外部表在日常开发中我们用的最多,比如原始日志文件或同时被多个部门同时操作的数据集,需要使用外部表,而且如果不小心将meta data删除了,HDFS上的数据还在,可以恢复,增加了数据的安全性。
和内部表的元数据在组织上是相同的,都是存储咋MYSQL上。
5.2.1 数据文件
在app-12节点的/tmp/hive目录下新建文件test1.csv和test2.csv,test.csv之前已经有了,新建两个文件内容如下。
方式,可以在本地编辑好之后通过FTP上传,也可以直接用命令行拷贝后再编辑。
| test.csv | test1.csv | test2.csv |
| 1,001,name001,11 2,002,name002,12 3,003,name003,11 4,004,name004,12 5,005,name005,11 6,006,name006,13 7,007,name007,11 8,008,name008,12 9,009,name009,14 | 11,001,name001,11 12,002,name002,12 13,003,name003,11 14,004,name004,12 15,005,name005,11 16,006,name006,13 17,007,name007,11 18,008,name008,12 19,009,name009,14 | 21,001,name001,11 22,002,name002,12 23,003,name003,11 24,004,name004,12 25,005,name005,11 26,006,name006,13 27,007,name007,11 28,008,name008,12 29,009,name009,14 |
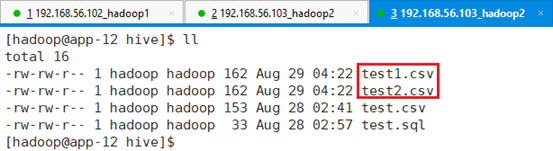
将/tmp目录三个数据文件test.csv、test1.csv和test2.csv拷贝到HDFS的/hive目录:
命令:hdfs dfs -copyFromLocal /tmp/hive/test.csv /hive
命令:hdfs dfs -copyFromLocal /tmp/hive/test1.csv /hive
命令:hdfs dfs -copyFromLocal /tmp/hive/test2.csv /hive或者:
命令:hdfs dfs -put /tmp/hive/test.csv /hive
命令:hdfs dfs -put /tmp/hive/test1.csv /hive
命令:hdfs dfs -put /tmp/hive/test2.csv /hive查看拷贝结果:hdfs dfs -ls /hive
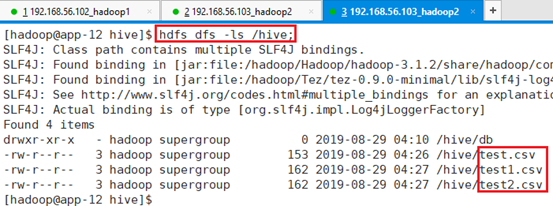
5.2.2 创建外部表
创建外部表:dd004,数据指向HDFS的/hive目录,文件格式用逗号进行字段分割。
hive> create external table dd004(
> id int, no string, name string, age int)
> row format delimited fields terminated by ','
> location '/hive';查看表dd004数据数量:
命令:select count(*) from dd004;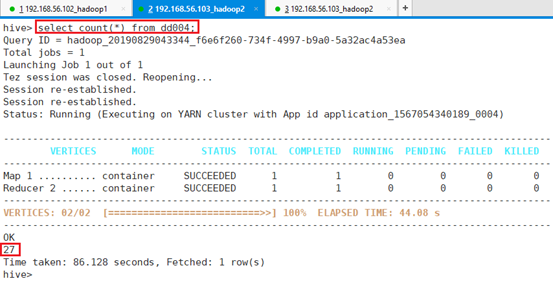
三个文件均导入了dd004表,共27条记录。
从HDFS上删除文件test2.csv,在三个节点的任何一个节点执行命令即可。
命令:hdfs dfs -rm /hive/test2.csv
命令:hdfs dfs -ls /hive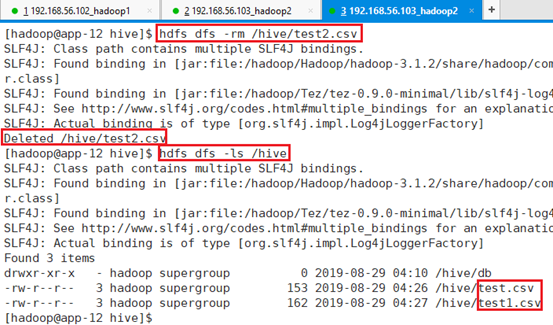
再查询表dd004条目项数:
命令:select count(*) from dd004;
可以看出表项数减少了,因为test2.csv文件没了。
5.2.3 删除外部表
删除外部表dd004:
命令:drop table dd004;
再查看对应的HDFS文件:hdfs dfs -ls /hive
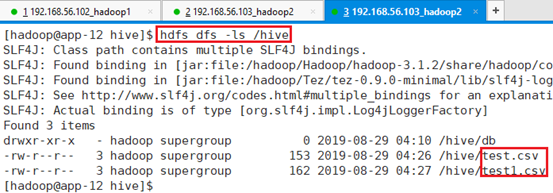
可以看出,表删除后,文件还在,并没有删除。
5.3 分区表
分区表通常分为静态分区表和动态分区表,前者需要导入数据时静态指定分区,后者可以直接根据导入数据进行分区。分区的好处是可以让数据按照区域进行分类,避免了查询时的全表扫描。
在Hive表中,表中的一个分区对应表下面的一个目录,即所有的分区数据都存储在对应的目录下
Hive查询需要全表扫描速度慢,废资源。通过建立分区表,将资源按查询分类。比如将表中年龄为15岁的分一个区,当查询年龄为12岁人员信息时,只需要在指定分区中进行查找即可,无需单独扫描全表,提高查询效率。
创建按年龄进行分区的分区表
5.3.1 创建分区表
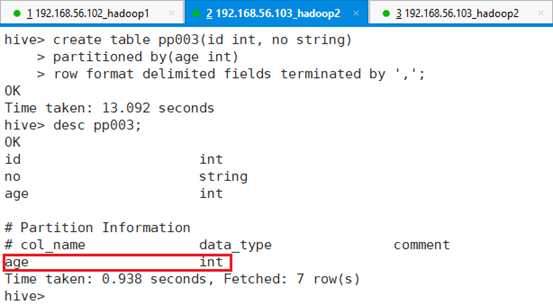
新建分区表pp003,该表以年龄为分区,字段为id和学号,不需要姓名:
hive> create table pp003(id int, no string)
> partitioned by(age int)
> row format delimited fields terminated by ',';注:新分区表的字段数量可以和源表不一样,取需要的字段即可。
将表dd003中满足条件的数据导入分区表pp003:
hive> insert into table p_t003 partition(age=12)
> select id, name from t003 where age=12;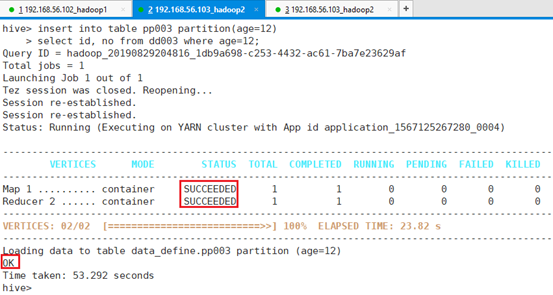
查看新的分区表及表中数据:
命令:select * from pp003;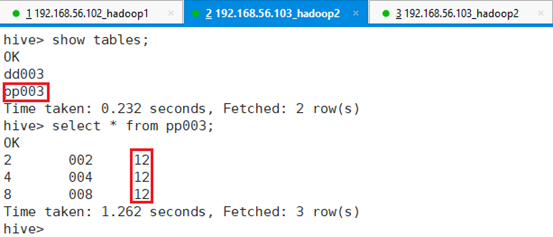
通过查询可以看出,将年龄为12岁的id和学号导入进了新的分区表。
查看对应HDFS文件:
命令:hive> dfs -ls /user/hive/warehouse/data_define.db;
命令:dfs -ls /user/hive/warehouse/data_define.db/pp003;
命令:dfs -ls /user/hive/warehouse/data_define.db/pp003/age=12;
命令:dfs -cat /user/hive/warehouse/data_define.db/pp003/age=12/000000_0;
可以看出有一个以表命名的目录/user/hive/warehouse/ data_define.db /pp003,在该目录下有一个符合条件要求的目录/user/hive/warehouse/data_define.db/pp003/age=12,该目录下的存的是分区数据文件/user/hive/warehouse/data_define.db/pp003/age=12/000000_0,文件中的数据即为新插入的数据。
5.3.2 效率对比
通过explain语句对比;
查询源数据表命令:explain select * from dd003 where age=12;
查询分区表命令:explain select * from pp003 where age=12;
通过对比发现,分区表操作步骤比没分区操作步骤少。效率有了提升。
5.3.3 删除分区表
删除分区表pp003:
命令:drop table pp003;
命令:dfs -ls /user/hive/warehouse/data_define.db;
通过查看HDFS目录文件可以看出,删除分区表后,分区表目录以及分区表中的数据文件都会被删除。
5.4 桶表
将同一个目录下的一个文件拆分成多个文件,每个文件包含一部分数据,方便获取值,提高检索效率
实现方式:
- 获取表的某一个列或者部分列,获取hashcode,按照hashcode值/buckets的个数,来决定每条数据放置到哪一个文件中。
- 桶中的数据可以根据一个或多个列另外进行排序。由于这样对每个桶的连接变成了高效的归并排序(merge-sort), 因此可以进一步提升map端连接的效率。
- 桶表的元数据也会在mysql中保存。
5.4.1 创建桶表
按id哈希创建三个桶表tt003,字段为id,学号和年龄:
hive> create table tt003(id int, no string, age int)
> clustered by(id) into 3 buckets
> row format delimited fields terminated by ','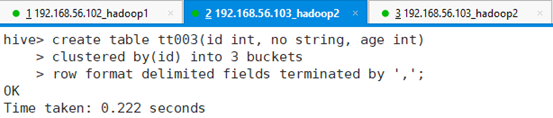
查看表tt003结构:
命令:desc tt003;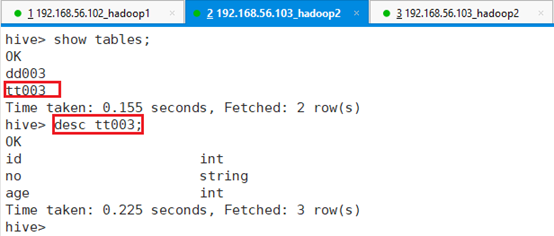
5.4.2 导入数据
将数据从表dd003中导入桶表tt003中,命令:
hive> insert overwrite table tt003
> select id, no, age from dd003;
查询桶表数据:
命令:select count(*) from tt003;
命令:select * from tt003;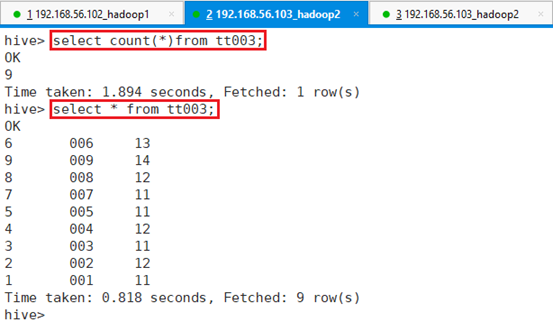
查看HDFS中的数据文件:
命令:dfs -ls /user/hive/warehouse/data_define.db/tt003;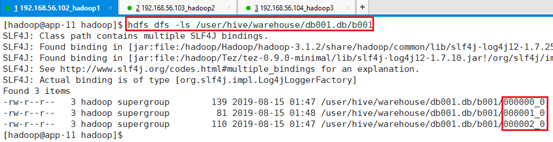
可以看出,按照三个桶的原则进行了哈希划分。注意此处有可能会是两个文件,毕竟哈希的时候数据少的情况下,可能有一个桶没有分到数据。
查看文件000000_0数据:
命令:dfs -cat /user/hive/warehouse/data_define.db/tt003/000000_0;
查看文件000001_0数据:
命令:dfs -cat /user/hive/warehouse/data_define.db/tt003/000001_0;
查看文件000002_0数据:
命令:dfs -cat /user/hive/warehouse/data_define.db/tt003/000002_0;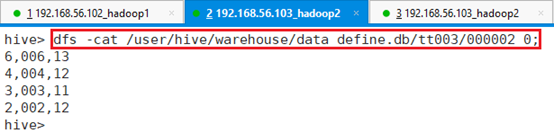
三个文件刚好9条数据,和dd003数据数目一样。
5.4.3 删除桶表
删除桶表tt003:
命令:drop table tt003;
查看HDFS文件目录:
命令:dfs -ls /user/hive/warehouse/data_define.db;
可以看出,数据文件也随之删除。
5.5 视图
视图是一张虚表,是一个逻辑概念,可以跨越多张实表。可以将多张表中的字段组合在一起形成一个视图,但是视图不存数据,通过视图查询出来的数据都来自实表。操作视图的方式和操作实表的方式一样。视图常用来简化复杂查询,Hive中的视图不支持物化视图。
5.5.1 创建视图
格式:create view 视图名 as select 数据来源一张或者多张表。
命令:create view vv001 as select id, name from dd003;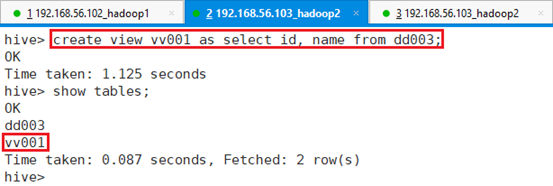
查看视图结构vv001:
命令:desc vv001;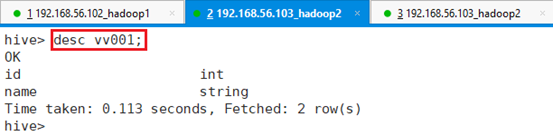
5.5.2 使用视图
查看视图vv001数据:
命令:select * from vv001;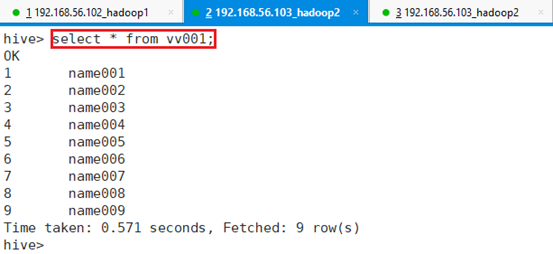
HDFS中,视图在HDFS中是不会生成对应目录的,因为视图本身是虚表,没有真实数据存在:
命令:dfs -ls /user/hive/warehouse/data_define.db;
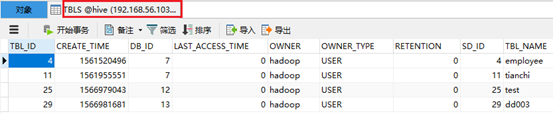
视图虽然是虚表,但是这个表还是存在的,查看MYSQL数据库hive中的表TBLS,所以在MYSQL中会有记录。
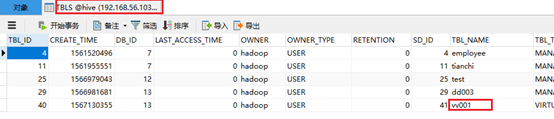
5.5.3 删除视图
删除视图vv001:
命令:drop view vv001;
删除视图后,MYSQL中的相应记录也会被删除