完整目录、平台简介、安装环境及版本:参考《Hive从入门到精通-概览》
六、数据操作
6.1 Load导入
6.1.1 语法格式
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE]
INTO TABLE tablename [PARTITION (partcol1=val1,partcol2=val2 ...)]LOCAL:原始文件在linux本地加上local,如果原始数据文件在hdfs,不用local
OVERWRITE:如果是覆盖数据加上overwrite,如果是追加,不要overwrite
PARTITION:如果是分区表加上partition,不是就不用了。
创建数据库data_oper,用于后续试验:
命令:create database data_oper;
命令:show databases;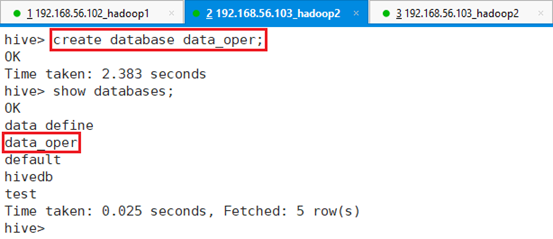
进入数据库data_oper:
命令:use data_oper;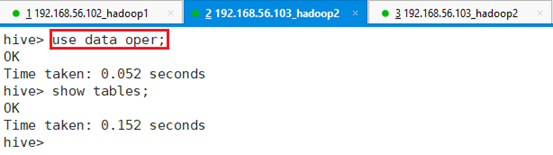
6.1.2 本地导入
6.1.2.1 数据源
用app-12节点 目录/tmp/hive下已有的三个文件:test1.csv、test2.csv、test.csv作为数据源
| /tmp/hive/test.csv | /tmp/hive/test1.csv | /tmp/hive/test2.csv |
| 1,001,name001,11 2,002,name002,12 3,003,name003,11 4,004,name004,12 5,005,name005,11 6,006,name006,13 7,007,name007,11 8,008,name008,12 9,009,name009,14 | 11,001,name001,11 12,002,name002,12 13,003,name003,11 14,004,name004,12 15,005,name005,11 16,006,name006,13 17,007,name007,11 18,008,name008,12 19,009,name009,14 | 21,001,name001,11 22,002,name002,12 23,003,name003,11 24,004,name004,12 25,005,name005,11 26,006,name006,13 27,007,name007,11 28,008,name008,12 29,009,name009,14 |
6.1.2.2 创建表
创建表d001:
hive> create table d001(id int, no string, name string, age int)
> row format delimited fields terminated by ',';查看表结构:desc d001;
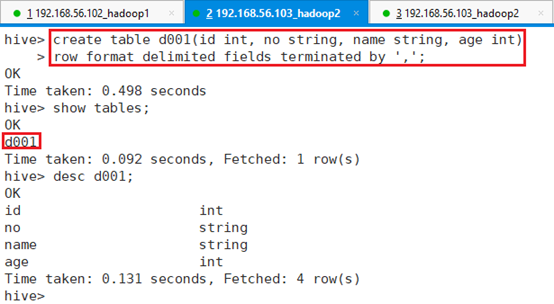
6.1.2.3 导入数据
6.1.2.3.1 导入文件
将/tmp/hive/test.csv文件导入表d001:
命令:load data local inpath '/tmp/hive/test.csv' into table d001;
命令:select * from d001;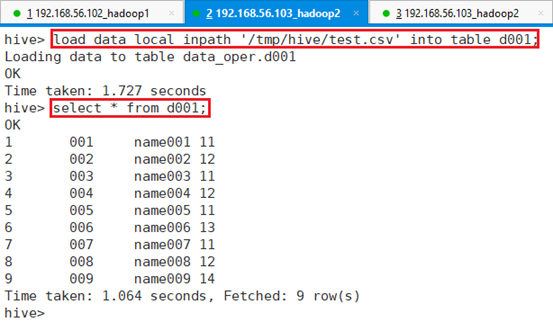
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/d001;
命令:dfs -cat /user/hive/warehouse/data_oper.db/d001/test.csv;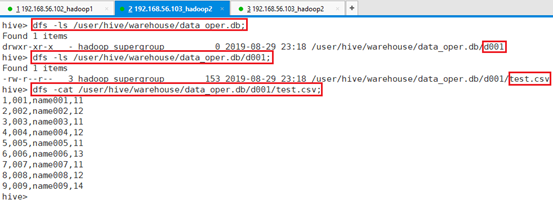
导入数据的同时,将数据文件也按表规则导入到了指定HDFS目录。
6.1.2.3.2 导入目录
将整个目录/tmp/hive/下的文件都导入d001,并覆盖之前的数据:
命令:load data local inpath '/tmp/hive/' overwrite into table d001;
查看表d001数据条目数即具体内容:
select count(*) from d001;
select * from d001;
三个文件数据是27条,总数显示是30条,是因为目录里面有个test.sql文件,把这个也作为元数据导入到表中了,只是导入后,三行都是NULL。
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/d001;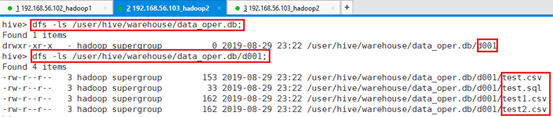
本地/tmp/hive目录四个文件都被导入进了HDFS指定文件夹。
6.1.3 HDFS导入
6.1.3.1 数据源
在HDFS的/hive目录下创建data目录
命令:dfs -mkdir /hive/data;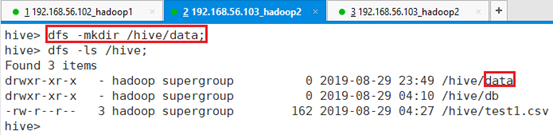
将app-12节点/tmp/hive目录下的三个文件test.csv、test1.csv、test2.csv上传到HDFS目录/hive/data:
命令:dfs -put /tmp/hive/test.csv /hive/data;
命令:dfs -put /tmp/hive/test1.csv /hive/data;
命令:dfs -put /tmp/hive/test2.csv /hive/data;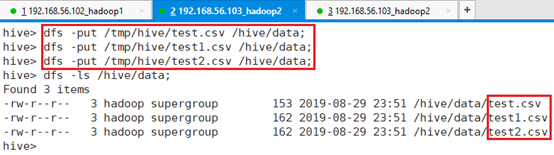
| /tmp/hive/test.csv | /tmp/hive/test1.csv | /tmp/hive/test2.csv |
| 1,001,name001,11 2,002,name002,12 3,003,name003,11 4,004,name004,12 5,005,name005,11 6,006,name006,13 7,007,name007,11 8,008,name008,12 9,009,name009,14 | 11,001,name001,11 12,002,name002,12 13,003,name003,11 14,004,name004,12 15,005,name005,11 16,006,name006,13 17,007,name007,11 18,008,name008,12 19,009,name009,14 | 21,001,name001,11 22,002,name002,12 23,003,name003,11 24,004,name004,12 25,005,name005,11 26,006,name006,13 27,007,name007,11 28,008,name008,12 29,009,name009,14 |
6.1.3.2 创建表
创建表d002:
hive> create table d002(id int, no string, name string, age int)
> row format delimited fields terminated by ',';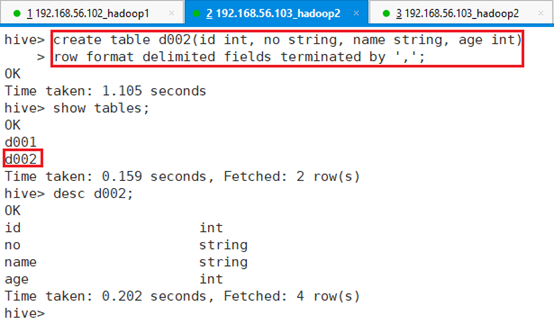
6.1.3.3 导入数据
6.1.3.3.1 导入文件
将HDFS上的文件/hive/data/test.csv导入到表d002:
命令:load data inpath '/hive/data/test.csv'overwrite into table d002;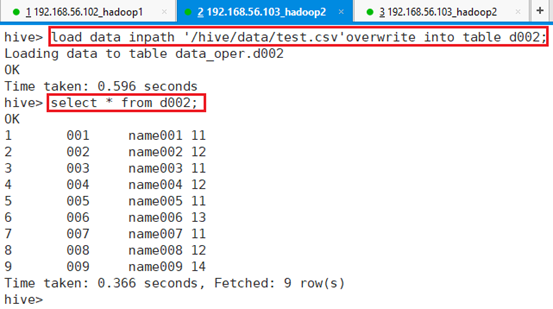
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/d002;
命令:dfs -cat /user/hive/warehouse/data_oper.db/d002/test.csv;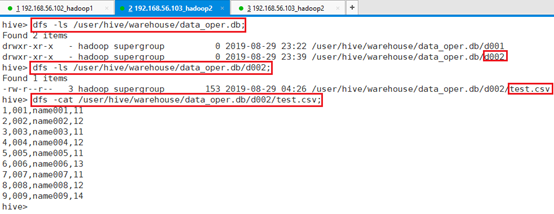
查看HDFS目录/hive/data,该目录下源文件test.csv已经被删除
命令:dfs -ls /hive/data;
便于后续试验,重新将test.csv上传到/hive/data目录
命令:dfs -put /tmp/hive/test.csv /hive/data;6.1.3.3.2 导入目录
将整个目录/hive/下的文件导入表d002,并覆盖之前的数据。
命令:load data inpath '/hive/data' overwrite into table d002;
查看表d002数据条目数即具体内容
select count(*) from d002;
select * from d002;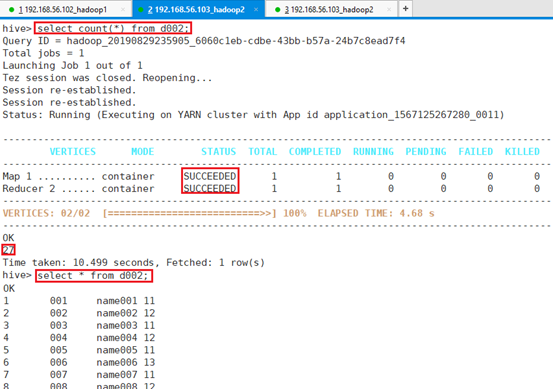
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/d002;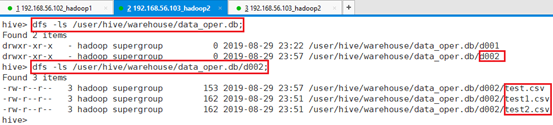
HDFS目录 /hive/data整个data目录都被导入到了默认数据库HDFS目录。

6.1.4 导入分区
6.1.4.1 准备数据
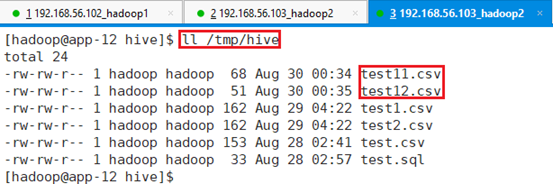
在app-12节点准备数据文件test11.csv和test12.csv,上传/tmp/hive目录
字段:序号,学号,项目和年龄。
| /tmp/hive/test11.csv | /tmp/hive/test12.csv |
| 1,001,name001,11 3,003,name003,11 5,005,name005,11 7,007,name007,11 | 2,002,name002,12 4,004,name004,12 8,008,name008,12 |
6.1.4.2 创建分区
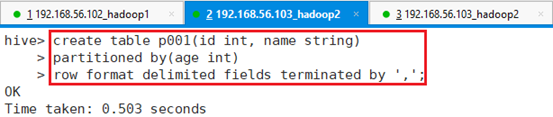
新建分区表p001:
hive> create table p001 (id int, name string)
> partitioned by (age int)
> row format delimited fields terminated by ',';注:新分区表的字段数量可以和源表不一样,取需要的字段即可。
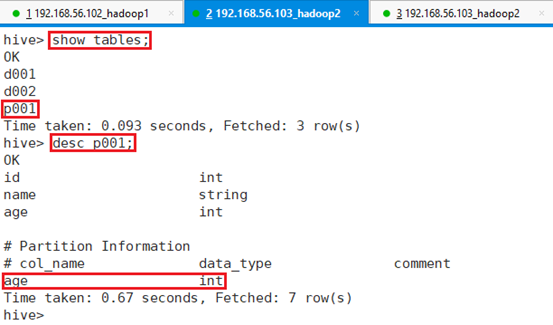
查看建表p001情况:desc p001;
6.1.4.3 导入数据
将/tmp/hive/test11.csv数据导入到年龄为11岁的分区表中。
hive> load data local inpath '/tmp/hive/test11.csv'
> into table p001 partition (age=11);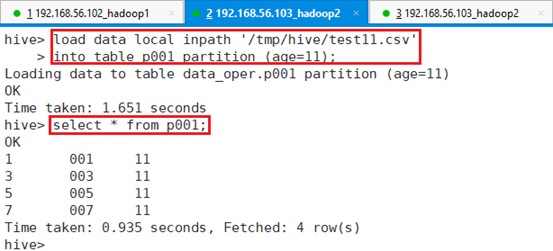
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/p001;
命令:dfs -ls /user/hive/warehouse/data_oper.db/p001/age=11;
命令:dfs -cat /user/hive/warehouse/data_oper.db/p001/age=11/test11.csv;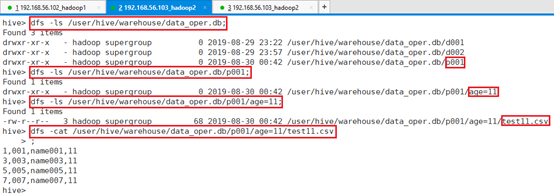
通过执行结果可以看到,数据文件已经成功导入到HDFS对应的表目录文件中。
接着将/tmp/hive/test12.csv数据导入到年龄为12岁的分区表中。
hive> load data local inpath '/tmp/hive/test12.csv'
> into table p001 partition (age=12);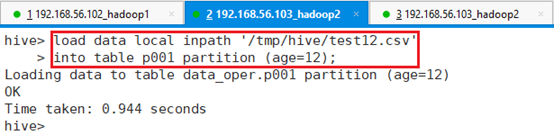
查看导入内容:select * from p001;
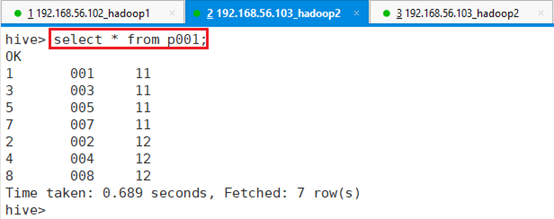
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;
命令:dfs -ls /user/hive/warehouse/data_oper.db/p001;
命令:dfs -ls /user/hive/warehouse/data_oper.db/p001/age=12;
命令:dfs -cat /user/hive/warehouse/data_oper.db/p001/age=12/test12.csv;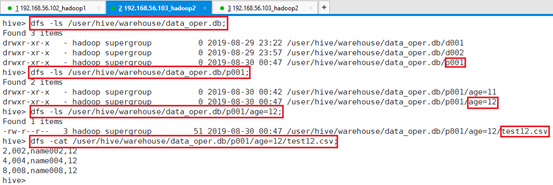
通过执行结果可以看到,数据文件已经成功导入到HDFS对应的表目录文件中。
6.1.5 复杂类型导入
- ‘ROW FORMAT DELIMITED FIELDS TERMINATED BY’ :字段与字段之间的分隔符
- ”COLLECTION ITEMS TERMINATED BY’ :一个字段各个item的分隔符
- ‘MAP KEYS TERMINATED BY’ :key value分隔符
6.1.5.1 array
在app-12节点/tmp/hive目录下新建资源文件:test_array.csv
| /tmp/hive/test_array.csv |
| 1,001:name001:11 2,002:name002 3,003 4, 5,005:name005:11 |
创建表d003,字段之间用’,’分割,array数组元素之间用’:’分割,命令:
hive> create table d003(name string, arr array<string>)
> ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':';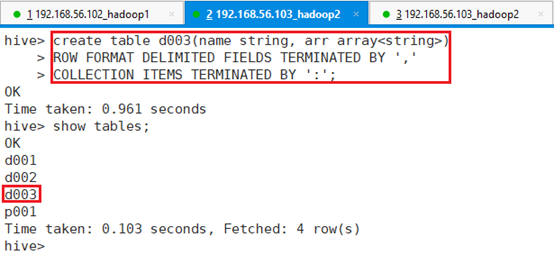
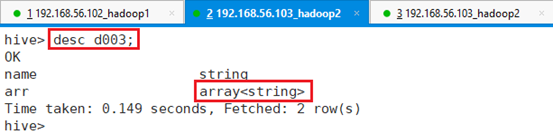
查看建表结果:desc d003;
将文件/tmp/hive/test_array.csv导入表d003
命令:load data local inpath '/tmp/hive/test_array.csv' into table d003;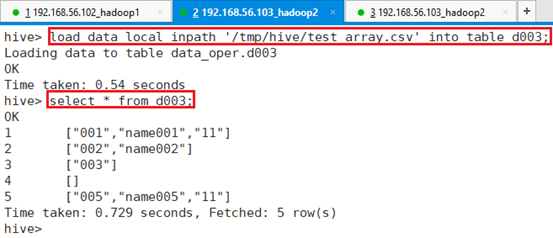
可以看到,数据以array格式导入表d003。
6.1.5.2 map
在app-12节点/tmp/hive目录下新建资源文件:test_map.csv
| /tmp/data/ test_map.csv |
| 1,no-001:name-name001 2,no-002 3, 4,no-004: 5,no-005:name- 6,no-:name-name006 7,no:name-name007 8,no-008:name 9,no-009:name-name009 |
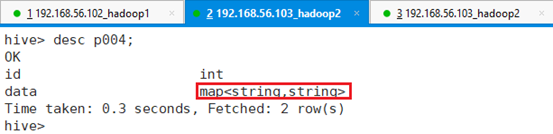
创建表p004,字段之间用’,’分割,数组元素之间用’:’分割,key和value之间用’-‘分隔,命令:
hive> create table t104(name string, arr map<string, int>)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ','
> COLLECTION ITEMS TERMINATED BY ':'
> MAP KEYS TERMINATED BY '-';
查看建表结果:desc p004;
将文件/tmp/hive/test_map.csv导入表p004
命令:load data local inpath '/tmp/hive/test_map.csv' into table p004;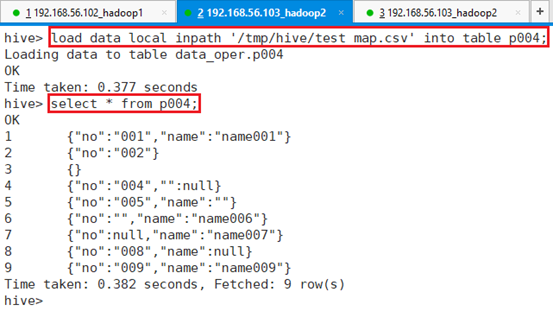
可以看到,数据以map格式导入表p004。
6.1.5.3 struct
在app-12节点/tmp/hive目录下新建资源文件:test_struct.csv
| /tmp/data/ test_struct.csv |
| 1,001:name001:11 2,002:name002: 3,003:name003 4,004: 5,005 6, 7 8,008:name008:12 9,009:name009:14 |
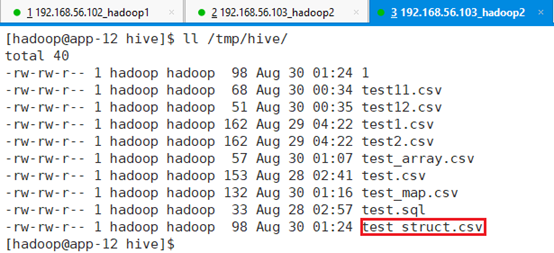
创建表t105,字段之间用’,’分割,结构体字段间用’:’,命令:
hive> create table p005(id int, data struct<no:string, name:string, age:int>)
> row format delimited fields terminated by ','
> collection items terminated by ':';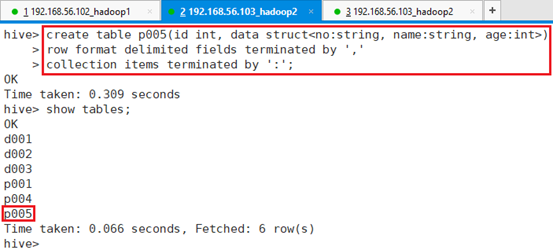
查看建表结果:desc t105;
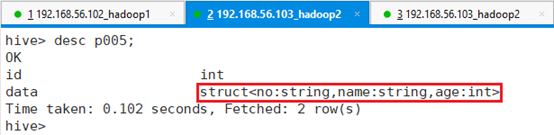
将文件/tmp/data/ test_struct.csv导入表p005
命令:load data local inpath '/tmp/hive/test_struct.csv' into table p005;
可以看到,数据以struct格式导入表p005。
6.2 表互相导入数据
6.2.1 通过查询插入数据
创建表d004,分隔符用默认\t:
命令:create table d004(id int, no string, age int);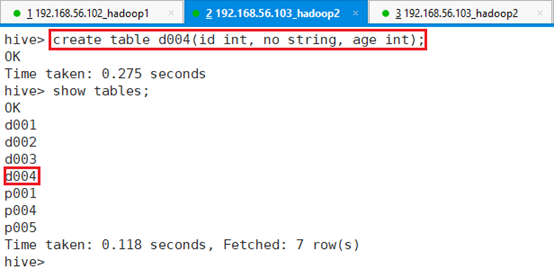
将表p001中年龄为11的id,name,age字段插入到表d004中
命令:insert overwrite table d004 select id,name,age from p001 where age=11;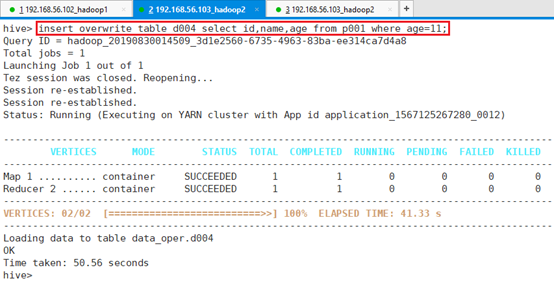
查询表d004,确认数据是否导入成功
select * from d004;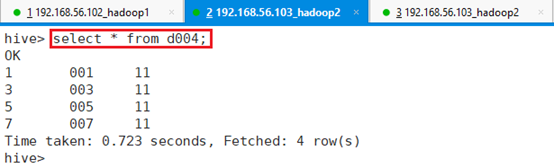
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db/d004;
命令:dfs -cat /user/hive/warehouse/data_oper.db/d004/000000_0;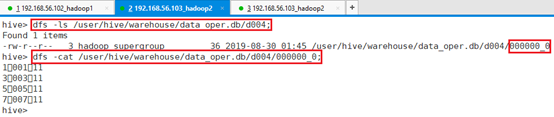
默认\t分隔符进行分割的源文件。
6.2.2 创建表并加载数据
利用p001表的数据创建表d005:
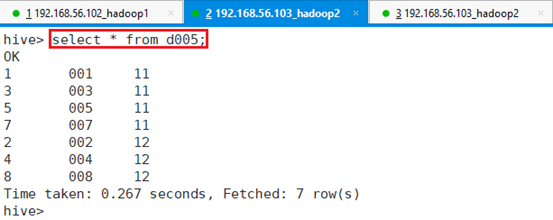
命令:create table d005 as select * from p001;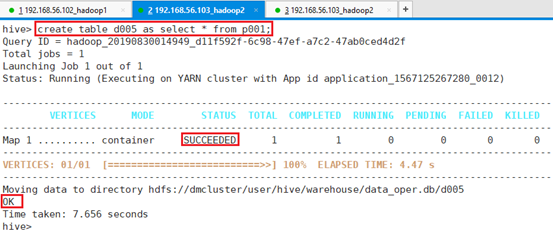
查看表d005的数据:select * from d005;
查看t004表对应的数据文件:

HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db/d005;
命令:dfs -cat /user/hive/warehouse/data_oper.db/d005/000000_0;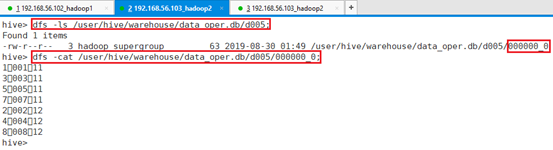
之前用的是默认分隔符,接下来指定分隔符创建表d006,从p001表导入数据到d006表,并指定d006表数据文件分隔符。
hive> create table d006
> row format delimited fields terminated by ','
> as select * from p001;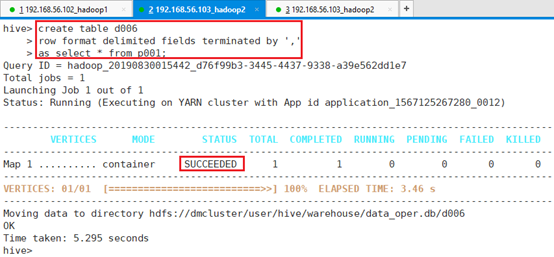
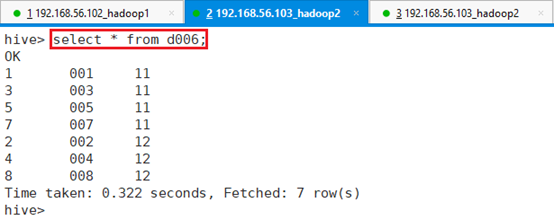
查看d006表数据:select * from d006;
查看d006的HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db/d006;
命令:dfs -cat /user/hive/warehouse/data_oper.db/d006/000000_0;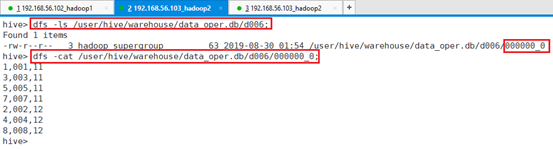
可以看出,数据文件是按创建时的指定分隔符,逗号进行数据分隔的。
6.3 Sqoop导入导出
Sqoop是Apache的一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
6.3.1 Sqoop安装
6.3.1.1 下载
登录网站:http://sqoop.apache.org/,点击‘nearby mirror’
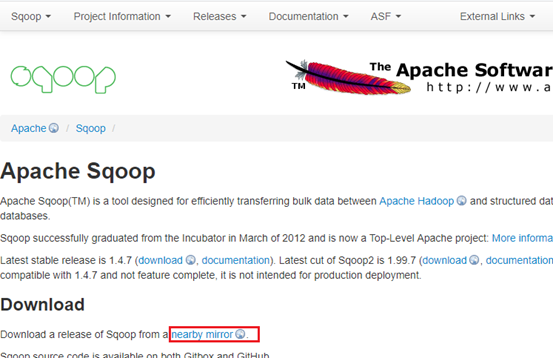
选择‘https://www-eu.apache.org/dist/sqoop/’
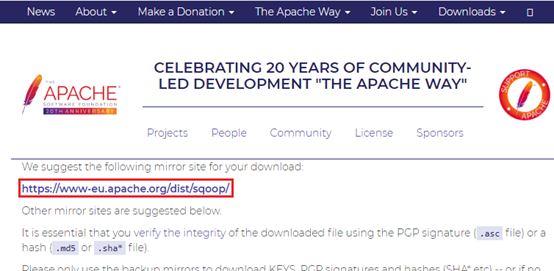
选择‘1.4.7/’

下载版本:sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
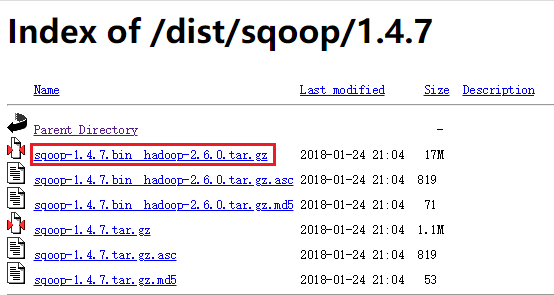
6.3.1.2 安装
在app-12节点,切换到hadoop用户并创建目录/hadoop/Sqoop
命令:mkdir /hadoop/Sqoop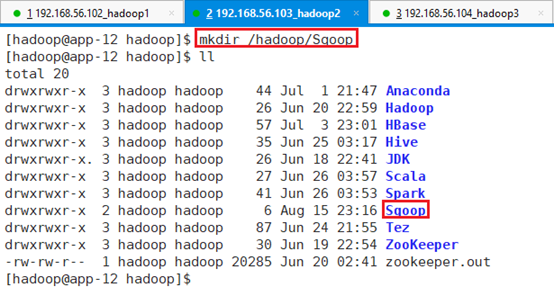
将安装文件上传到/hadoop/Sqoop目录:

解压缩sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz文件到/Hadoop/Sqoop目录
命令:tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz
6.3.1.2.1 环境变量
添加环境变量:vi ~/.bashrc
export SQOOP_HOME=/hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0
export PATH=${SQOOP_HOME}/bin:$PATH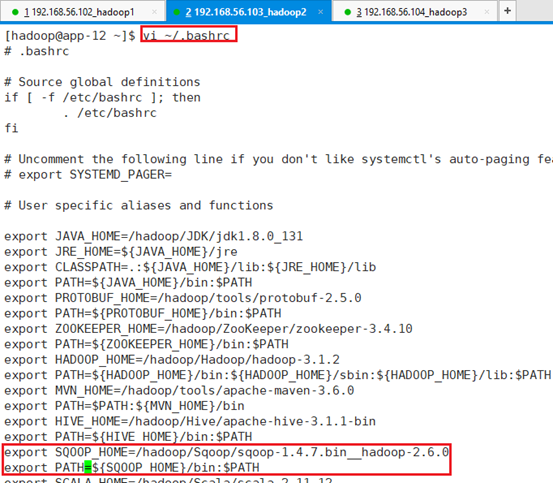
保存并生效:source ~/.bashrc
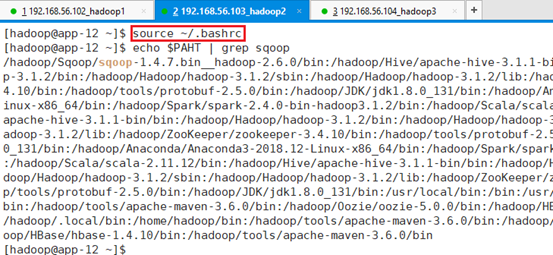
查看生效情况:
命令:echo $PATH | grep sqoop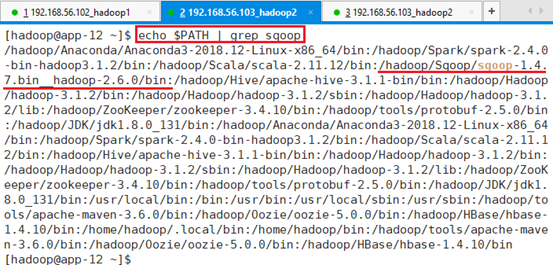
6.3.1.2.2 配置文件
进入Sqoop配置文件目录
命令:cd /hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf
将sqoop-env-template.sh复制一份,并取名为sqoop-env.sh
命令:cp sqoop-env-template.sh sqoop-env.sh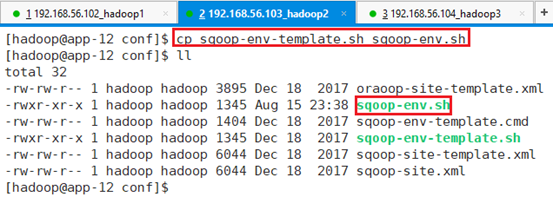
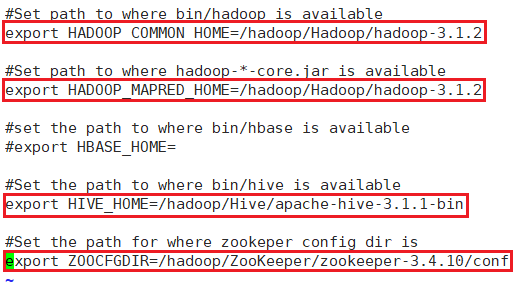
编辑文件:vi sqoop-env.sh
/hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/conf sqoop-env.sh
export HADOOP_COMMON_HOME=/hadoop/Hadoop/hadoop-3.1.2
#Set path to where hadoop-*-core.jar is available
export HADOOP_MAPRED_HOME=/hadoop/Hadoop/hadoop-3.1.2
#set the path to where bin/hbase is available
#export HBASE_HOME=
#Set the path to where bin/hive is available
export HIVE_HOME=/hadoop/Hive/apache-hive-3.1.1-bin
#Set the path for where zookeper config dir is
export ZOOCFGDIR=/hadoop/ZooKeeper/zookeeper-3.4.10/conf
将MySQL的驱动包mysql-connector-java-5.1.46.jar上传到/hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib下

查看bin目录下提供的命令,常用的命令就是sqoop。
6.3.1.2.3 测试
测试:sqoop help
6.3.2 Sqoop导入导出
Sqoop可以在HDFS/Hive和关系型数据库之间进行数据的导入导出,其中主要使用了import和export这两个工具。这两个工具非常强大,提供了很多选项帮助我们完成数据的迁移和同步。比如,下面两个潜在的需求:
业务数据存放在关系数据库中,如果数据量达到一定规模后需要对其进行分析或同统计,单纯使用关系数据库可能会成为瓶颈,这时可以将数据从业务数据库数据导入(import)到Hadoop平台进行离线分析。
对大规模的数据在Hadoop平台上进行分析以后,可能需要将结果同步到关系数据库中作为业务的辅助数据,这时候需要将Hadoop平台分析后的数据导出(export)到关系数据库。
import和export工具有些通用的选项,如下表所示:
| 选项 | 含义说明 |
| –connect <jdbc-uri> | 指定JDBC连接字符串 |
| –connection-manager <class-name> | 指定要使用的连接管理器类 |
| –driver <class-name> | 指定要使用的JDBC驱动类 |
| –hadoop-mapred-home <dir> | 指定$HADOOP_MAPRED_HOME路径 |
| –help | 打印用法帮助信息 |
| –password-file | 设置用于存放认证的密码信息文件的路径 |
| -P | 从控制台读取输入的密码 |
| –password <password> | 设置认证密码 |
| –username <username> | 设置认证用户名 |
| –verbose | 打印详细的运行信息 |
| –connection-param-file <filename> | 可选,指定存储数据库连接参数的属性文件 |
用SSH连接到app-12节点,切换到hadoop用户,并切换到sqoop的bin目录:/hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/bin
查看MYSQL数据库test数据库下表:
命令:./sqoop list-tables --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018
MYSQL数据库地址:192.168.56.103
MYSQL数据库端口:3306
MYSQL数据库名称:test
MYSQL数据库用户名:root
MYSQL数据库密码:Yhf_1018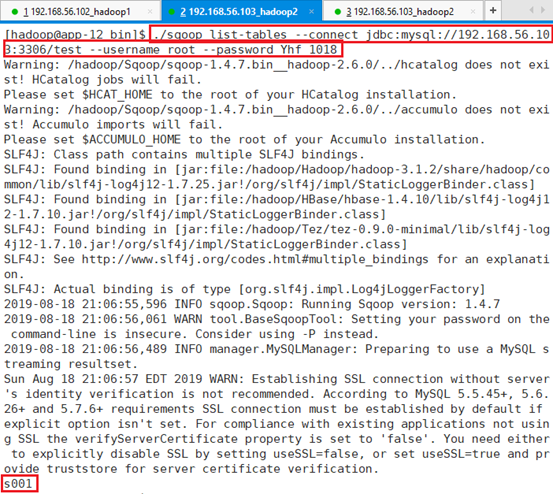
6.3.2.1 准备数据库
需要从数据库导入数据,本地直接从app-12节点的MYSQL数据库试验,
6.3.2.1.1 建数据库
用root用户登录app-12节点的MYSQL数据库,并输入数据库密码,
命令:mysql -uroot -p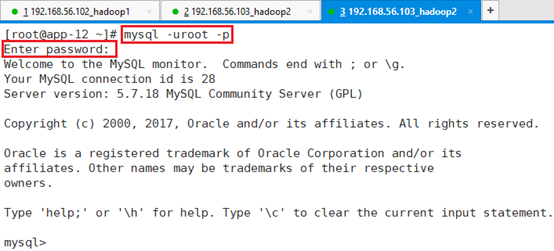
查看MySQL已有数据库:
命令:show databases;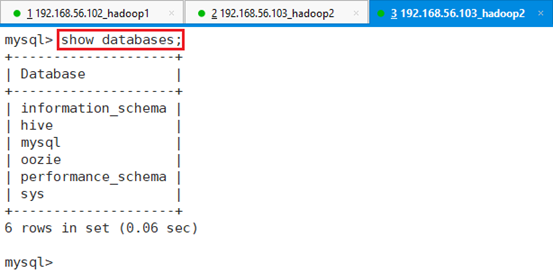
新建数据库test:
命令:create database test;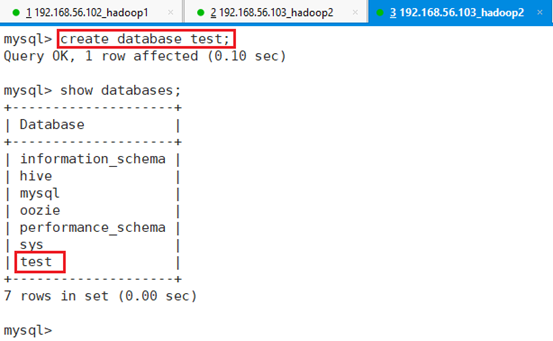
6.3.2.1.2 建表
进入数据库test:
命令:use test;
查看该数据库下表:
命令:show tables;
可以看到,由于新建的数据库,该数据库名下还没有相应的表。
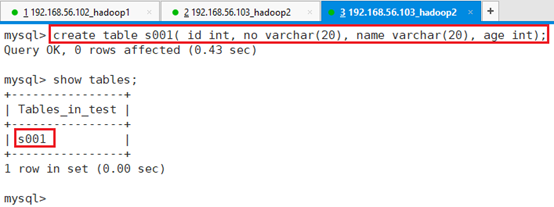
创建表s001:
命令:create table s001( id int, no varchar(20), name varchar(20), age int);通过查看可以看出该表已经被成功创建。
6.3.2.1.3 插入测试数据
插入数据:
insert into s001 values(1,'001','name001', 1);
insert into s001 values(2,'002','name002', 2);
insert into s001 values(3,'003','name003', 3);
insert into s001 values(4,'004','name004', 4);
insert into s001 values(5,'005','name005', 5);
insert into s001 values(6,'006','name006', 6);
insert into s001 values(7,'007','name007', 7);
insert into s001 values(8,'008','name008', 8);
insert into s001 values(9,'009','name009', 9);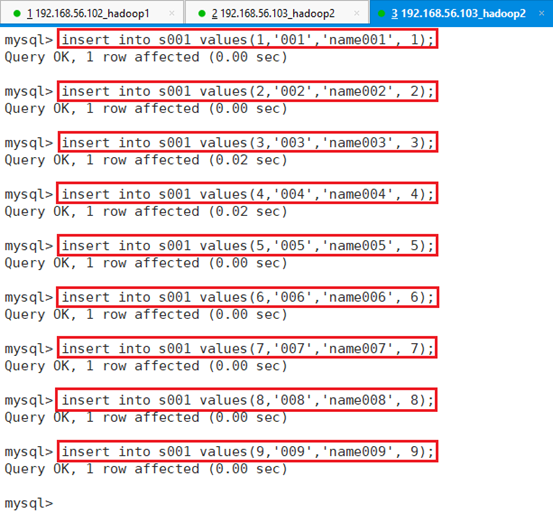
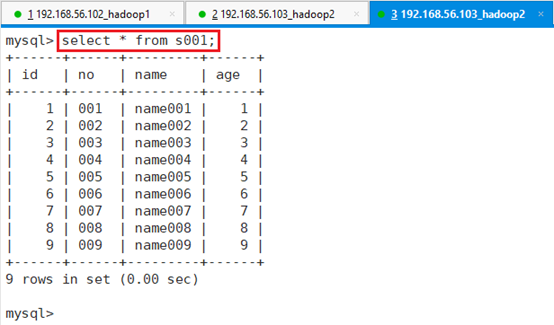
查看插入的数据:select * from s001;
接下来操作如何将这张表信息导入到HDFS或者HIVE数据仓库中。
6.3.2.2 导入数据
import工具,是将HDFS平台外部的结构化存储系统中的数据导入到Hadoop平台,便于后续分析。
import工具的基本选项及其含义,如下表所示:
| 选项 | 含义说明 |
| –append | 将数据追加到HDFS上一个已存在的数据集上 |
| –as-avrodatafile | 将数据导入到Avro数据文件 |
| –as-sequencefile | 将数据导入到SequenceFile |
| –as-textfile | 将数据导入到普通文本文件(默认) |
| –boundary-query <statement> | 边界查询,用于创建分片(InputSplit) |
| –columns <col,col,col…> | 从表中导出指定的一组列的数据 |
| –delete-target-dir | 如果指定目录存在,则先删除掉 |
| –direct | 使用直接导入模式(优化导入速度) |
| –direct-split-size <n> | 分割输入stream的字节大小(在直接导入模式下) |
| –fetch-size <n> | 从数据库中批量读取记录数 |
| –inline-lob-limit <n> | 设置内联的LOB对象的大小 |
| -m,–num-mappers <n> | 使用n个map任务并行导入数据 |
| -e,–query <statement> | 导入的查询语句 |
| –split-by <column-name> | 指定按照哪个列去分割数据 |
| –table <table-name> | 导入的源表表名 |
| –target-dir <dir> | 导入HDFS的目标路径 |
| –warehouse-dir <dir> | HDFS存放表的根路径 |
| –where <where clause> | 指定导出时所使用的查询条件 |
| -z,–compress | 启用压缩 |
| –compression-codec <c> | 指定Hadoop的codec方式(默认gzip) |
| –null-string <null-string> | 果指定列为字符串类型,使用指定字符串替换值为null的该类列的值 |
| –null-non-string <null-string> | 如果指定列为非字符串类型,使用指定字符串替换值为null的该类列的值 |
6.3.2.2.1 导入到HDFS
将MYSQL数据库test的表s001中的列no, name ,age导出到HDFS目录’/tmp/s001
hadoop用户在sqoop的bin目录下执行命令:
./sqoop import --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018 --table s001 --columns 'no, name ,age' -m 1 --target-dir '/tmp/s001'
--import:导出
jdbc:mysql://192.168.56.103:3306/test:指定URL的test数据库
--username root:用户名
--password Yhf_1018:密码
--table s001:test数据库下的s001表
--columns 'no, name ,age':导出表s001的指定列
-m 1:1个MR任务
--target-dir '/tmp/s001':导出到HDFS的/tmp/s001目录执行该命令之前,先需要确保HDFS目录/tmp/s001目录不存在,否则会报错
命令查看:hdfs dfs -ls /tmp
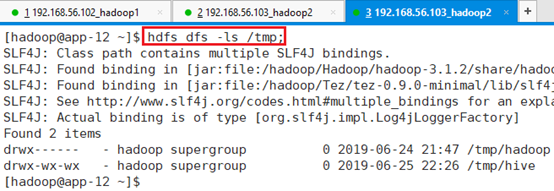
执行命令sqoop导出命令,通过执行过程,可以看出会涉及map和reduce操作。


查看HDFS目录:
命令:hdfs dfs -ls /tmp/s001
查看导出数据:
命令:hdfs dfs -cat /tmp/s001/part-m-00000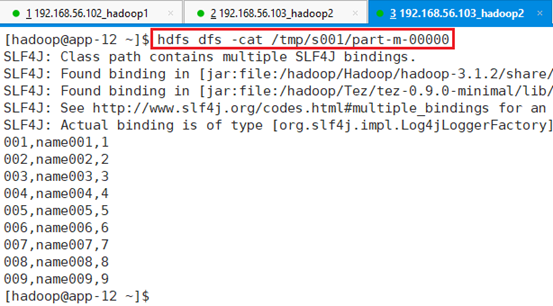
从数据中可以看出,将MYSQL数据库将MYSQL数据库test的表s001中的列no, name ,age导出到HDFS目录文件/tmp/s001//part-m-00000中
6.3.2.2.2 导入到HIVE
拷贝Hive包hive-exec-3.1.1.jar到Sqoop包下
cp /hadoop/Hive/apache-hive-3.1.1-bin/lib/hive-exec-3.1.1.jar /hadoop/Sqoop/sqoop-1.4.7.bin__hadoop-2.6.0/lib/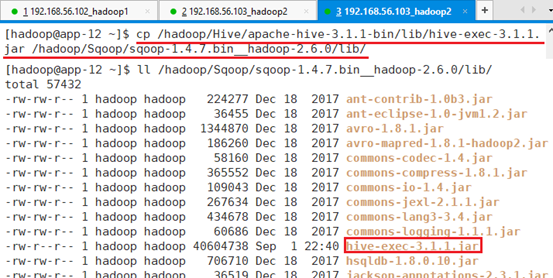
将Hive包添加到HADOOP路径中
export HADOOP_CLASSPATH=${ HADOOP_CLASSPATH } :$HIVE_HOME/lib/*
导入成功后,会自动在hive中创建表并保存数据。
执行命令前确保/user/hadoop/表名,目录不存在:hdfs dfs -ls /user/hadoop
因为SQOOP导入MYSQL数据到HIVE数据仓库中时,会先在HDFS目录/user/hadoop中建临时目录保存数据,在将数据导入到HIVE数据仓库中,然后删除临时目录。所以执行改名了前,如果该目录存在,临时目录就无法建立,提示出错。
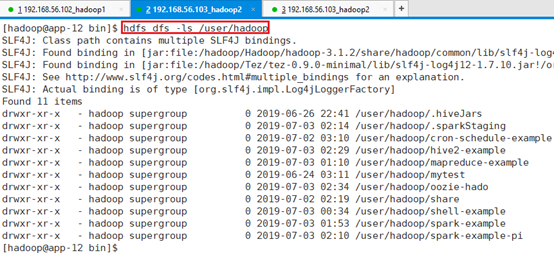
执行命令:
./sqoop import --hive-import --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018 --table s001 --columns 'no, name ,age' -m 1 --fields-terminated-by "," --hive-overwrite --hive-database data_oper --hive-table s001
--hive-import:导出到HIVE数据仓库
jdbc:mysql://192.168.56.103:3306/test:指定URL的test数据库
--username root:用户名
--password Yhf_1018:密码
--table s001:test数据库下的s001表
--columns 'no, name ,age':导出表s001的指定列
-m 1:1个MR任务
--fields-terminated-by ",":导出到数据仓库中的数据用","分割开,默认为\t
--hive-overwrite:用覆盖的方式导入,默认是插入的方式
hive-database data_oper:导出到HIVE数据仓库中的数据库data_oper
--hive-table s001:导出后的表命名为s001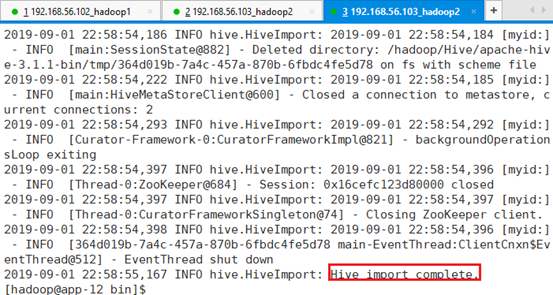
查看数据库db002的HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;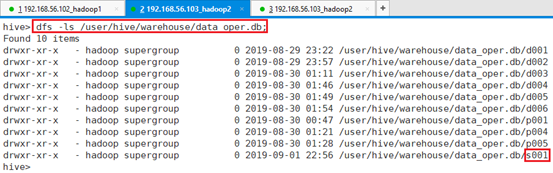
可以看到存在表s001目录
继续查看表001目录:
命令:hdfs dfs -ls /user/hive/warehouse/data_oper.db/s001;
查看表文件数据:
命令:dfs -cat /user/hive/warehouse/data_oper.db/s001/part-m-00000;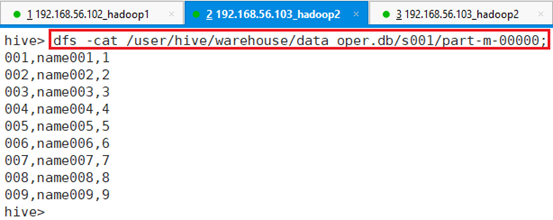
可以看出,是按要求”,”分割,指定列的数据。
查看表情况:show tables;
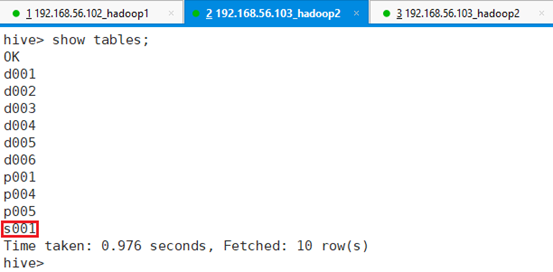
接着查看表s001数据:select * from s001;
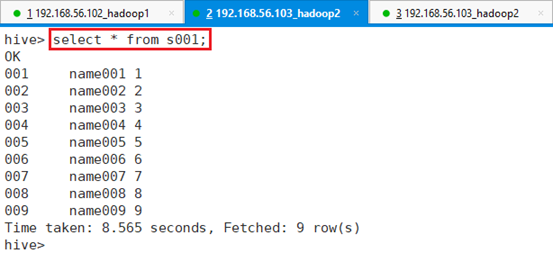
至此,数据导入到HIVE成功。
6.3.2.2.2.1 Where查询
还可以按查询条件where查询后,导入数据,比如只导入年龄为2的数据。
./sqoop import --hive-import --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018 --table s001 --columns 'no, name ,age' -m 1 --fields-terminated-by "," --hive-overwrite --hive-database data_oper --hive-table s002 --where 'age=2'
--hive-import:导出到HIVE数据仓库
jdbc:mysql://192.168.56.103:3306/test:指定URL的test数据库
--username root:用户名
--password Yhf_1018:密码
--table s001:test数据库下的s001表
--columns 'no, name ,age':导出表s001的指定列
-m 1:1个MR任务
--fields-terminated-by ",":导出到数据仓库中的数据用","分割开,默认为\t
--hive-overwrite:用覆盖的方式导入,默认是插入的方式
hive-database data_oper:导出到HIVE数据仓库中的数据库data_oper
--hive-table s002:导出后的表命名为s002
--where 'age=2':导出年龄为2的数据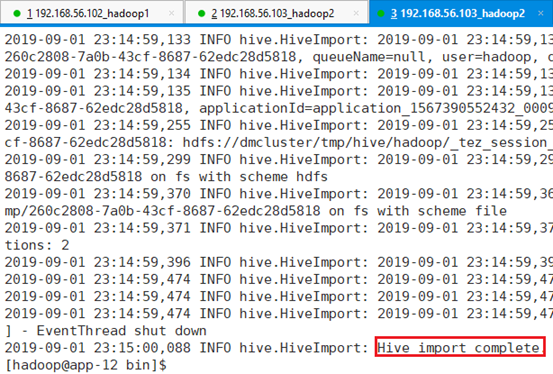
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;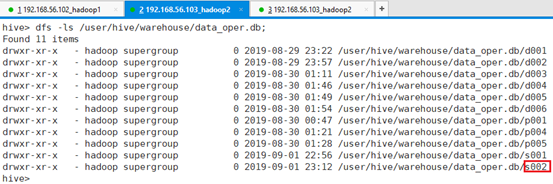
命令:dfs -ls /user/hive/warehouse/data_oper.db/s002;
查看HDFS文件:
命令:dfs -cat /user/hive/warehouse/data_oper.db/s002/part-m-00000;
可以看出满足条件的只有一条数据
HIVE查看表情况:
命令:show tables;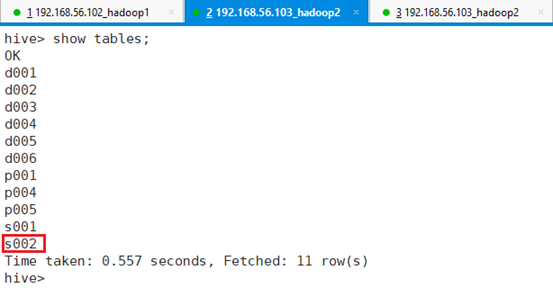
命令:select * from s002;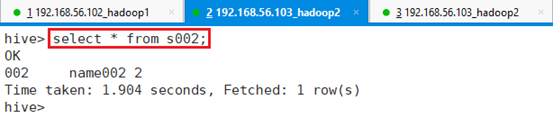
可以看出表s002只有一条满足记录的数据
6.3.2.2.2.2 Select查询
通过select导出指定条件数据
./sqoop import --hive-import --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018 -m 1 --fields-terminated-by "," --hive-overwrite --hive-database data_oper --hive-table s003 --query 'select * from s001 where age<5 and $CONDITIONS' --target-dir '/tmp/s003'
--hive-import:导出到HIVE数据仓库
jdbc:mysql://192.168.56.103:3306/test:指定URL的test数据库
--username root:用户名
--password Yhf_1018:密码
--table s001:test数据库下的s001表
--columns 'no, name ,age':导出表s001的指定列
-m 1:1个MR任务
--fields-terminated-by ",":导出到数据仓库中的数据用","分割开,默认为\t
--hive-overwrite:用覆盖的方式导入,默认是插入的方式
hive-database data_oper:导出到HIVE数据仓库中的数据库data_oper
--hive-table s003:导出到表s003;
--query 'select * from s001 where age<5 and $CONDITIONS':查询条件,此处$CONDITIONS必须有,而且有了select后,--table s001这个指定表功能就不需要了, --columns 'no, name ,age'也不需要了,select里面就已经指定了;
--target-dir '/tmp/s003':需要设定HDFS临时目录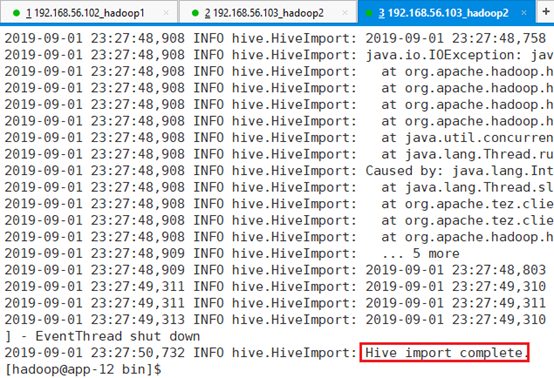
查看HDFS目录:
命令:dfs -ls /user/hive/warehouse/data_oper.db;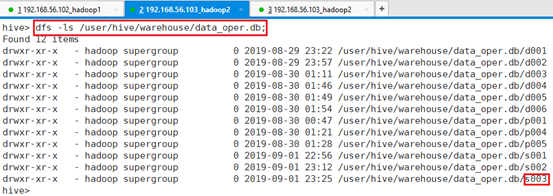
命令:dfs -ls /user/hive/warehouse/data_oper.db/s003;
查看HDFS文件:
命令:dfs -cat /user/hive/warehouse/data_oper.db/s003/part-m-00000;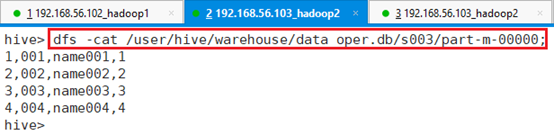
文件中保存的就是满足select查询语句的数据,而且使用指定分隔符分割的。
HIVE查看表情况:
命令:show tables;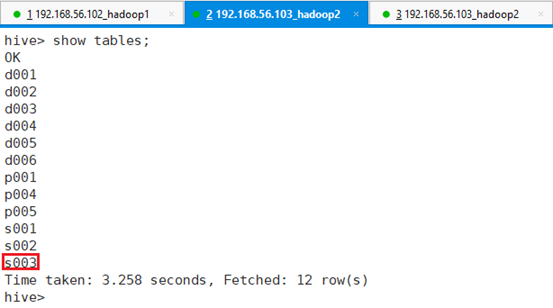
命令:select * from s003;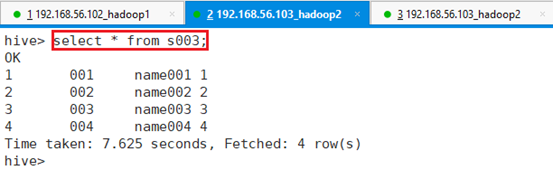
可以看出表s003也一样
6.3.2.3 导出数据
Export参数
| 选项 | 含义说明 |
| –columns <col,col,col…>: | 要导出到表格的列 |
| –direct: | 使用直接导出快速路径。 |
| –export-dir <dir>: | 用于导出的HDFS源路径。 |
| -m,–num-mappers <n>: | 使用n个mapper任务并行导出。 |
| –table <table-name>: | 要填充的表。 |
| –call <stored-proc-name>: | 存储过程调用。 |
| –update-key <col-name>: | 锚点列用于更新。如果有多个列,请使用以逗号分隔的列列表。 |
| –update-mode <mode>: | 指定在数据库中使用不匹配的键找到新行时如何执行更新。mode包含的updateonly默认值(默认)和allowinsert。 |
| –input-null-string <null-string>: | 字符串列被解释为空的字符串。 |
| –input-null-non-string <null-string>: | 要对非字符串列解释为空的字符串。 |
| –staging-table <staging-table-name>: | 数据在插入目标表之前将在其中展开的表格。 |
| –clear-staging-table: | 表示可以删除登台表中的任何数据。 |
| –batch: | 使用批处理模式执行基础语句。 |
6.3.2.3.1 建表
root账号登录app-12节点,再利用MYSQL的root账号和密码登录MYSQL数据库
命令:mysql -uroot -p
进入数据库test,并创建表s002
命令:use test;
命令:create table s002( id int, no varchar(20), name varchar(20), age int);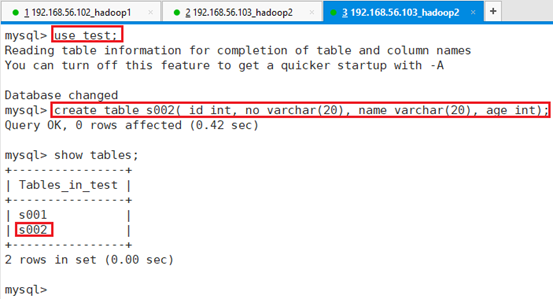
导出的数据类类型需要和表一致。
6.3.2.3.2 准备数据
将HIVE数据库data_oper下的表d002数据导出到MYSQL数据库test下的表s002.
HIVE数据库data_oper下的表d002数据如下:
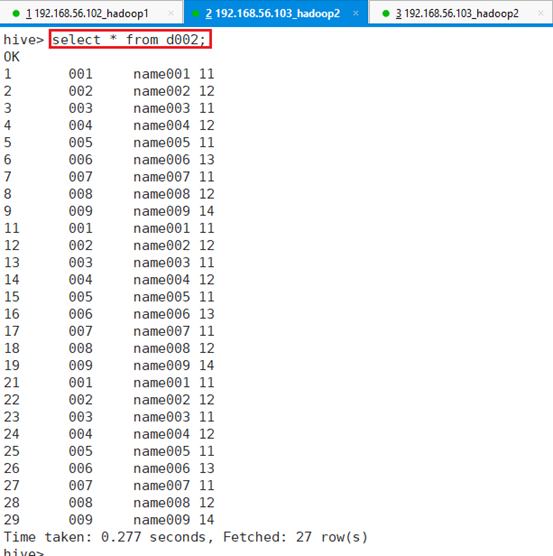
查看d002对应的HDFS目录,导出时需要用到
命令:dfs -ls /user/hive/warehouse/data_oper.db/d002;
6.3.2.3.3 导出
导出命令:
./sqoop export --connect jdbc:mysql://192.168.56.103:3306/test --username root --password Yhf_1018 -m 1 --fields-terminated-by "," -table s002 --export-dir '/user/hive/warehouse/data_oper.db/d002'
-- export:导出到MYSQL数据库
jdbc:mysql://192.168.56.103:3306/test:指定URL的test数据库
--username root:用户名
--password Yhf_1018:密码
-table s002:MYSQL数据库下的s002表
-export-dir '/user/hive/warehouse/data_oper.db/d002':HIVE表d002所在HDFS目录执行完成后,用root用户登录app-12节点的MYSQL数据库,并输入数据库密码,进入数据库test,查看MSQL数据表
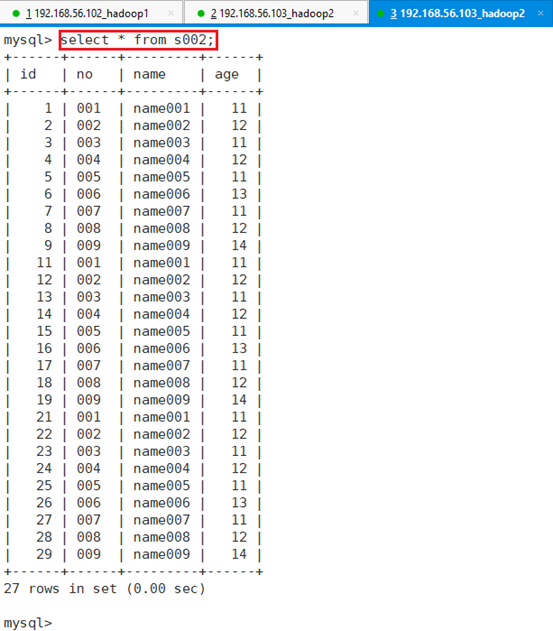
可以看出数据已经成功导入到MYSQL数据的表s002。