完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
5.4 YARN
5.4.1 YARN的产生背景
由于hadoop1.0的良好特性,比如BAT、Facebok、Yahoo等都在各自业务系统特别是大数据处理系统都用了hadoop,但是随着hadoop1.0用的越来越多,原先的hadoop1.0设计存在的一些问题逐渐暴露出来,主要体现在以下几个方面:

5.4.1.1 单点故障SPOF
hadoop1.0的NameNode和JobTracker被设计成单一节点,当提交一个任务时,这个任务需要有一个管理者,JobTracker就是这个任务的管理者,由于单节点的原因,一旦该节点出现故障,对整个系统有致命性影响,严重的制约的hadoop的可扩展性和可靠性。特别是在生产环境中,不能做到高可靠性的话,生产系统很难大规模推广 ,随着业务越来越多,在大数据系统中同时运行任务数也会越来越多,同时对内存的消耗增加等因素,会产生一些任务失败的情况,单节点已经将大规模的应用给堵死了。
如假设hadoop1.0有10个任务,每个任务又划分为1000个task(如Map、Reduce),这些task运行在不同的机器上,这时就有10000个节点,这些节点位于DataNode上,基于数据的本地化运行策略,如果DataNode每隔5分钟定期向JobTracker发送信息,JobTracker处理压力会很大,所以正常情况下hadoop1.0的集群规模只能达到4000台左右。
因为运行在大数据集上,需要很多很多非商用的机器上运行hadoop,这也是设计hadoop的初衷之一,不是在商用机器上,也不是在大型机器上,而是在廉价 的普通机器上构建业务系统,构建数据处理系统,4000台的规模影响了hadoop1.0的可扩展性和稳定性。
5.4.1.2 仅仅支持MR
计算模式比较单一,现实业务中可能存在很多需求,如需要对实时业务进行及时处理的Spark,需要有工作流的无环图等数据处理框架,如何整合这些处理框架。
如果数据在hadoop里面不能将数据搬移到数据所在的节点上,那么该数据框架的应用前景会受到很大的限制,数据是核心,所以说能够集成这些不同模式的数据处理框架是hadoop要解决的一个主要问题。
5.4.1.3 MR Slot
即便能够支持更多的计算框架,而不仅仅是MapReduce这一种框架,那么既有的MapReduce框架模式也不够灵活,因为Map和Reduce绑定的太死,先进行Map,然后进行Reduce,中间有个shuffle,作为整个Map和Reduce的耦合点之一,之前提到过因为Map和Reduce作为一个整体提交给用户使用,但是不是每个业务同时都需要Map和Reduce操作,有时候只需要其中之一。
在hadoop1.0中的TaskTracker将任务分解为MapTask Slot和ReduceTask Slot,slot可以理解为机架里面的插槽,在大数据里面可以理解为分配的一个资源池,从硬件的slot抽象到软件里面,这么演进过来的。如果当前仅存在Map或者Reduce这种任务,那么同时需要分配两个slot,会造成资源浪费,因为只需要单一的Map或者单一的Reduce就行。
5.4.1.4 RM灵活性
hadoop1.0采用静态slot资源分配措施,即在任务提交分析完成之后,slot就已经分配了,而且在节点启动前,为每个节点配置好slot总数,一旦启动后,就不能动态更改,并且Map Slot和Reduce Slot不允许交换,即做了Map就不能做Reduce,做了Reduce就不能做Map。
但是节点的真实运行情况是Map节点运行紧张而Reduce节点运行空闲,只有Map做完之后才能启动Reduce,因为Reduce需要从所有的Map结果去拷贝数据,中间做了个优化,拷贝的线程是逐步增多,刚开始比较少,随着Map运算完成的越来越多,拷贝的线程也随之增加,但是即便这种情况下,还是Map计算紧张,因为Map需要处理整个的数据集,而Reduce是处理Map结束之后的数据集,Map结果数据集相对于Map输入的数据集来说量级不一样,否则的话没有必要做Map,这个就是Map的设计初衷,逐步的降解而不是增多。
针对这些情况,数据科学家以及软件工程师提供了另一个集群管理框架YARN(Yet Another Resource Negotiator)。
5.4.2 YARN架构
5.4.2.1 架构体系
YARN的架构体系,蕴含在如图:

YARN有三个组件:RM(Resource Manager)、NM(Node Manager)、AM(App Master)。RM是整个资源管理器的核心组件,采用了和HDFS一样的主从结构,负责所有资源的监控、分配和管理;AM仅仅负责每个应用程序的调度和协调;NM负责本节点资源的维护,由于所有程序都要跑在一个个节点上,做最底层工作的由NM来完成,因为NM上面会有很多容器Container去跑我们的计算应用。
相对于hadoop1.0,YARN将资源管理和作业控制分开,即RM仅仅作为资源管理,作业控制由AM控制。比如有两个任务,对应两个颜色的Client端,分别提交了一个任务,向RM申请资源,RM根据整个资源状况选定一个NM上分配AM给任务,这个任务同时申请计算资源Container。AM负责整个任务的协调和资源管理,但是RM有整个系统资源的控制权和分配权,每一个AM申请资源需要和RM协商。
比如,RM相当于市,一个个NM相当于每个区,市里面下达的任务需要区里面来执行,其中很多个项目和工作需要向市长申请工作相关资源,资源会下达给某个区,区也需要各个区来协助,一个区不一定能单独完成任务,区成立管理办公室AM,其他区加入这个项目的成员相当于Container,但是所有的管理过程都需要市里面的批准。这样就能够将整个系统进行横向扩展,可以有更多的资源,完成更多的任务,接纳更多的项目。
项目汇报线:RM需要获取各个NM的情况,即各个区NM需要随时向市RM汇报工作,包括资源、CPU、内存等情况,然后市里面通过大屏展示各个区任务、资源的使用情况。同时成立项目办公室AM,其他区的办事员Container需要向办公室AM汇报进度情况。
5.4.2.2 案例
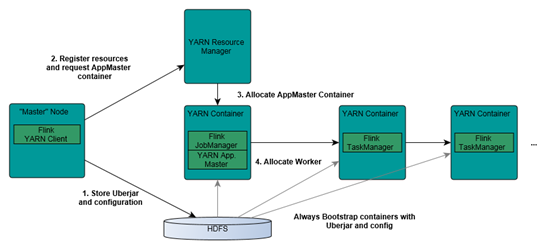
以Flink运行在YARN上为例,展现YARN使用流程,可以将Flink理解为某个计算任务。
首先,需要向Flink计算框架提交任务,在Flink框架里面有个YARN客户端,它了解YARN集群的情况,相当于有个接口。为什么需要向Flink提交任务,因为写的是Flink应用程序,必然向Flink客户端提交任务,才能借助Flink提供的高层次接口简化工作量。
提交任务后,Flink知道需要将其他资源包括Flink API资源打包成UBER.JAR,提交给YARN集群,首先提交给HDFS,HDFS是整个集群所能共享的缓存。
再向RM申请资源,首先申请AM,AM是处理程序的leader,设立项目运行办公室,再由项目申请办公室AM协调申请办事员worker,办事员协调之后,将任务的执行文件UBER.JAR拷贝到本地执行,执行过程中,需要向项目办公室汇报项目情况。
YARN将任务协调交给应用程序本身,或者应用处理框架本身。
5.4.3 YARN基本命令操作
YARN有三大类命令:管理名、客户端命令、守护进程命令。
User Commands:
application or app
applicationattempt
classpath
container
jar
logs
node
queue
version
envvars
Administration Commands:
daemonlog
nodemanager
proxyserver
resourcemanager
rmadmin
schedulerconf
scmadmin
sharedcachemanager
timelineserver
registrydns用ssh登录到app-11节点,并切换到hadoop用户:su – hadoop
启动集群,并检查集群是否正常工作。
5.4.3.1 yarn node
打印节点信息:yarn node -all –list
包括状态、地址、id、container数
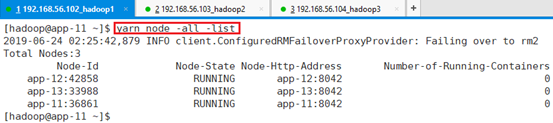
有些节点上会有container,作为计算用,某些节点上会有AM,计算的协调者。
5.4.3.2 yarn rmadmin
所有RM状态,RM做了HA,有两个状态:yarn rmadmin -getAllServiceState
只有一个是active,一个是standby。

还可以查看单独某个RM的状态
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2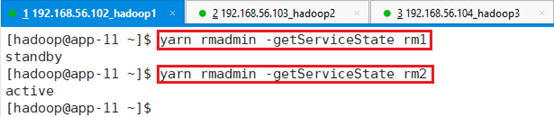
5.4.3.3 yarn app
和AM交互,可以将app打上标签以及type,可以对app分类,也可以终止app,销毁app,杀死app等。
查看列表:yarn app -list
显示任务的id、名称、状态、类型、提交人、队列情况、URL访问等。
目前未提交任务,所以app list为空。
5.4.3.4 yarn envvars
查看yarn的环境变量:yarn envvars
在运行出现问题是,可以通过此命令核实环境变量。
5.4.3.5 yarn jar
运行jar程序,后续案例详细讲述:yarn jar

5.4.3.6 yarn version
查看版本信息:yarn version
5.4.3.7 yarn classpath
查看路径信息:yarn classpath
5.4.3.8 yarn top
动态展现yarn执行的情况:yarn top
CPU、内存、任务的完成情况等打印出来
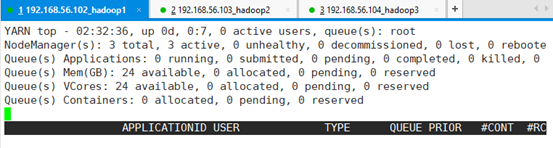
CTRL+C退出
5.4.4 RM HA配置
YARN集群的核心部件就是RM,是整个系统的大脑,因此需要对RM做HA,确保整个集群的高可用。
5.4.4.1 配置文件
打开初始安装配置文件中的yarn-site.xml文件。

<configuration>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序 -->
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandle</value>
</property>
<!-- Node label是将相似特点的节点进行分组的一种途径,application可以指定在哪里运行 -->
<property>
<name>yarn.node-labels.fs-store.root-dir</name>
<value>/hadoop/Hadoop/hadoop-3.1.2/tmp/hadoop-yarn-${user}/node-labels/</value>
</property>
<property>
<name>yarn.node-attribute.fs-store.root-dir</name>
<value>/hadoop/Hadoop/hadoop-3.1.2/tmp/hadoop-yarn-${user}/node-attribute/</value>
</property>
<!-- 当应用程序运行结束后,日志被转移到的HDFS目录 -->
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/hadoop/Hadoop/hadoop-3.1.2/tmp/logs</value>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.active-dir</name>
<value>/hadoop/Hadoop/hadoop-3.1.2/tmp/entity-file-history/active</value>
</property>
<property>
<name>yarn.timeline-service.entity-group-fs-store.done-dir</name>
<value>/hadoop/Hadoop/hadoop-3.1.2/tmp/entity-file-history/done/</value>
</property>
<!-- 启用HA高可用性 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定resourcemanager的名字 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmCluster</value>
</property>
<!-- 使用了2个resourcemanager,分别指定Resourcemanager的地址 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 指定zookeeper集群机器 -->
<property>
<name>hadoop.zk.address</name>
<value>app-11:2181,app-12:2181,app-13:2181</value>
</property>
<!-- Container 超过了虚拟内存的使用限制 虚拟内存的检查false掉-->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 指定rm1的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>app-11</value>
</property>
<!-- 指定RM的Web端访问地址。 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>app-11:8088</value>
</property>
<!-- 指定rm2的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>app-12</value>
</property>
<!-- 指定RM的Web端访问地址。 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>app-12:8088</value>
</property>
</configuration>前面都是目录相关的配置,不详细讲述,主要讲述HA相关的配置。
- 启用HA
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>- 整个集群命名,有个class-id
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmCluster</value>
</property>- 配置RM的ids,即做哪些RM做RM集群,可以定义多个,此处定义两个。
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>- RM的HA是通过zookeeper协调组件做HA,需要zookeeper地址
<property>
<name>hadoop.zk.address</name>
<value>app-11:2181,app-12:2181,app-13:2181</value>
</property>- 用的是虚拟机,禁止虚拟内存的检验
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>- rm1地址
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>app-11</value>
</property>- rm1的web访问地址
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>app-11:8088</value>
</property>- rm2地址
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>app-12</value>
</property> - rm2的web访问地址
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>app-12:8088</value>
</property> 5.4.4.2 HA主备互换
- 检查主备状态:
yarn rmadmin -getAllServiceState
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2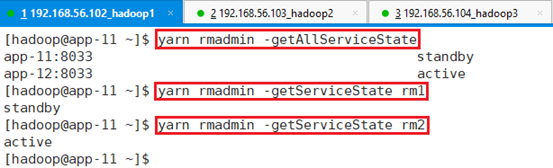
- 将主rm2切换成备:
yarn rmadmin -transitionToStandby rm2 -forcemanual
- 将rm1切换成active状态:
yarn rmadmin -transitionToActive --forceactive --forcemanual rm1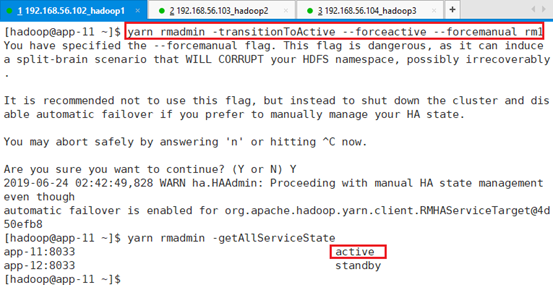
5.4.5 调度器配置
多用户多任务环境下,怎么保证有限资源和业务约束下的有序调度和执行任务,这是YARN资源调度器的主要工作,实现协调者。
从架构层考虑,为了实现可插拔式的资源调度器,YARN需要有一个资源调度器的通用接口,可以根据通用接口实现自己的资源调度器,这种接口是一个事件处理器,由外部事件触发,比如添加或者删除一个计算节点、添加或者删除一个应用以、应用程序的超时回收或者节点进行更新等。将资源调度所面临的重要事件抽象出来,这样实现的资源调度器就可以在这个基础上进行编写我们对应的处理程序。
本部分重点讲述YARN自带的两个调度器:
5.4.5.1 容量调度器(Capacity Scheduler)
由Yahoo贡献的,是一个可插拔的调度器,允许多个用户安全共享大型集群,而且能够在分配的容量限制下为应用成分配资源。容量调度器提供队列,为了支持更细粒度的资源调度,将容量队列抽象成层级结构,从而确保在一个组织内部各个应用程序之间共享资源。
5.4.5.1.1 capacity-scheduler.xml
打开资源文件下面的capacity-scheduler.xml
<configuration>
<property>
<name>yarn.scheduler.capacity.maximum-applications</name>
<value>10000</value>
<description>
最多可同时处于等待和运行状态的应用程序数目
</description>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.5</value>
<description>
集群中可用于运行application master的资源比例上限,这通常用于限制并发运行的应用程序数目.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value>
<description>
ResourceCalculator用于比较调度程序资源的,默认的即是DefaultResourceCalculator,默认只关注内存和CPU资源
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
root队列的所有子队列,该实例中只有一个
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.capacity</name>
<value>100</value>
<description>
default队列的资源容量
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.user-limit-factor</name>
<value>1</value>
<description>
每个用户可使用的资源限制
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-capacity</name>
<value>100</value>
<description>
Default队列可使用的资源上限.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.state</name>
<value>RUNNING</value>
<description>
Default队列的状态,可以是RUNNING或者STOPPED.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_submit_applications</name>
<value>*</value>
<description>
限制哪些用户可向default队列中提交应用程序."*"表示任意用户
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_administer_queue</name>
<value>*</value>
<description>
限制哪些用户可管理default队列中的应用程序,“*”表示任意用户
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.acl_application_max_priority</name>
<value>*</value>
<description>
指定哪个用户可以提交具有配置任务优先级的应用
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.maximum-application-lifetime
</name>
<value>-1</value>
<description>
以秒为单位提交给队列的应用程序的最大生命周期. 任何小于或等于零的值将被视为禁用.
对于此队列中的所有应用程序,这将是一个困难的时间限制. 如果配置了正值,那么提交到该队列的任何应用程序将在超过配置的生命周期后被终止.
用户还可以在应用程序提交上下文中指定每个应用程序的寿 但是,如果超过队列最大生命周期,则用户生存期将被覆盖. 这是时间点配置.
注意:配置太低会导致应用程序更快被中断. 该功能仅适用于叶队列
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.default.default-application-lifetime
</name>
<value>-1</value>
<description>
以秒为单位提交给队列的应用程序的默认生存期. 任何小于或等于零的值将被视为禁用.
如果用户没有提交具有生命周期值的应用程序,则将取这个值. 这是时间点配置.
注意:默认的生命周期不能超过最大生存期. 该功能仅适用于叶队列.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.node-locality-delay</name>
<value>40</value>
<description>
调度器尝试调度一个rack-local container之前,
最多跳过的调度机会,通常而言,该值被设置成集群中机架数目,默认情况下为-1,表示不启用该功能.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.rack-locality-additional-delay</name>
<value>-1</value>
<description>
在节点本地延迟时间之外的另外的错过的调度机会的次数,在此之后,CapacityScheduler尝试调度非切换容器而不是机架本地容器.
例如:在node-locality-delay = 40和rack-locality-delay = 20的情况下,
调度器将在40次错过机会之后尝试机架本地分配,在40 + 20 = 60之后错过机会.
设置此参数时,应考虑到群集的大小.
我们使用-1作为默认值,禁用此功能. 在这种情况下,根据资源请求中指定的容器和唯一位置的数量以及集群的大小,
计算分配关闭交换容器的错失机会的数量.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings</name>
<value></value>
<description>
将用于将作业分配给队列的映射列表.
这个列表的映射语法: [u|g]:[name]:[queue_name][,next mapping]*
通常这个列表将被用来映射用户到队列.
例如, u:%user:%user 映射所有用户以与用户相同的名字排队.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.queue-mappings-override.enable</name>
<value>false</value>
<description>
如果存在队列映射,它是否会覆盖用户指定的值? 管理员可以使用此项将作业放入与用户指定的队列不同的队列中.
默认值是false.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.per-node-heartbeat.maximum-offswitch-assignments</name>
<value>1</value>
<description>
控制节点心跳期间允许的OFF_SWITCH分配的数量.
增加此值可以提高OFF_SWITCH容器的调度速率. 较低的值可减少特定节点上应用程序的“聚集”. 默认值是1.
合法值是1-MAX_INT. 这个配置是可刷新的.
</description>
</property>
<property>
<name>yarn.scheduler.capacity.application.fail-fast</name>
<value>false</value>
<description>
Whether RM should fail during recovery if previous applications'
queue is no longer valid.
</description>
</property>
</configuration>5.4.5.1.2 查看状态
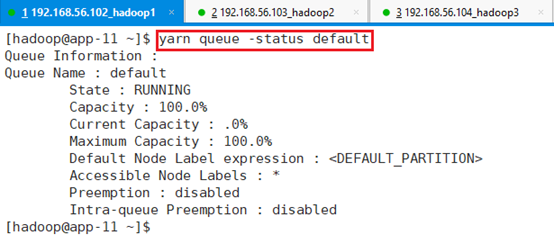
查看default队列状态:yarn queue -status default
包括状态、容量、当前容量、最大容量等信息。
5.4.5.2 公平调度器(Fair Scheduler)
容量调度器里面,将整个资源分配为队列,队列有资源的上限,比如整个集群只有一个任务,但是队列定义的上限是60%,这时就只能达到60%的资源利用率。而公平调度器则相反,将整个的集群资源分配给这个应用程序,当提交其他应用程序时,已经释放的资源就会分配给新的应用程序,因此每个应用程序最后都能粗略的获得等量资源,所以叫公平调度器。
5.4.6 YARN应用编程实战
找到实践文件:

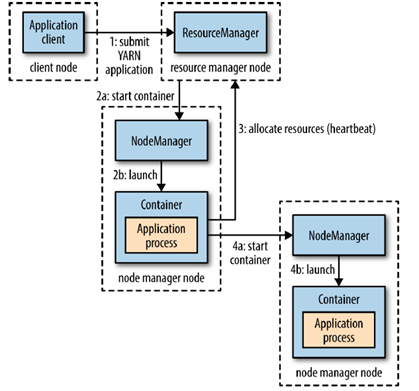
总体流程如图,客户端Client.java向RM(Resource Manager)提交申请资源,运行ApplicationMaster.java,AM(ApplicationMaster)向RM以及NM(NodeManager)申请资源Container。
本例子申请了10个Container去运行JavaPi程序,每个Container都运行JavaPi程序,10个Container之间并没有关联,但是在其他框架里面Container是相互协作完成任务,本例子只是做演示YARN应用程序的编写例子。
5.4.6.1 Client:Client.java
package org.apache.hadoop.yarn.examples;
import java.io.File;
import java.io.IOException;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import org.apache.commons.io.FilenameUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.util.ClassUtil;
import org.apache.hadoop.yarn.api.ApplicationConstants;
import org.apache.hadoop.yarn.api.ApplicationConstants.Environment;
import org.apache.hadoop.yarn.api.protocolrecords.GetNewApplicationResponse;
import org.apache.hadoop.yarn.api.records.ApplicationId;
import org.apache.hadoop.yarn.api.records.ApplicationReport;
import org.apache.hadoop.yarn.api.records.ApplicationSubmissionContext;
import org.apache.hadoop.yarn.api.records.ContainerLaunchContext;
import org.apache.hadoop.yarn.api.records.LocalResource;
import org.apache.hadoop.yarn.api.records.LocalResourceType;
import org.apache.hadoop.yarn.api.records.LocalResourceVisibility;
import org.apache.hadoop.yarn.api.records.Priority;
import org.apache.hadoop.yarn.api.records.Resource;
import org.apache.hadoop.yarn.client.api.YarnClient;
import org.apache.hadoop.yarn.client.api.YarnClientApplication;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
import org.apache.hadoop.yarn.exceptions.YarnException;
import org.apache.hadoop.yarn.util.ConverterUtils;
import org.apache.log4j.Logger;
/**
* Hello world!
*
*/
public class Client {
static private Logger logger = Logger.getLogger("yarnClient");
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
if (UserGroupInformation.isSecurityEnabled()) {
throw new Exception("SecurityEnabled , not support");
}
// 1. create and start a yarnClient
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();
// 2. create an application
YarnClientApplication app = yarnClient.createApplication();
app.getApplicationSubmissionContext()
.setKeepContainersAcrossApplicationAttempts(false);
app.getApplicationSubmissionContext().setApplicationName(
"yarnClient.ApplicationMaster");
// 3. Set the app's resource usage, 100*10MB, 1vCPU
Resource capability = Resource.newInstance(100, 1);
app.getApplicationSubmissionContext().setResource(capability);
// 4. Set the app's localResource env and command by
// ContainerLaunchContext
ContainerLaunchContext amContainer = createAMContainerLanunchContext(
conf, app.getApplicationSubmissionContext().getApplicationId());
app.getApplicationSubmissionContext().setAMContainerSpec(amContainer);
// 5. submit to queue default
app.getApplicationSubmissionContext().setPriority(
Priority.newInstance(0));
app.getApplicationSubmissionContext().setQueue("default");
ApplicationId appId = yarnClient.submitApplication(app
.getApplicationSubmissionContext());
monitorApplicationReport(yarnClient, appId);
}
private static ContainerLaunchContext createAMContainerLanunchContext(
Configuration conf, ApplicationId appId) throws IOException {
//Add this jar file to hdfs
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
FileSystem fs = FileSystem.get(conf);
String thisJar = ClassUtil.findContainingJar(Client.class);
String thisJarBaseName = FilenameUtils.getName(thisJar);
logger.info("thisJar is " + thisJar);
addToLocalResources(fs, thisJar, thisJarBaseName, appId.toString(),
localResources);
//Set CLASSPATH environment
Map<String, String> env = new HashMap<String, String>();
StringBuilder classPathEnv = new StringBuilder(
Environment.CLASSPATH.$$());
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append("./*");
for (String c : conf
.getStrings(
YarnConfiguration.YARN_APPLICATION_CLASSPATH,
YarnConfiguration.DEFAULT_YARN_CROSS_PLATFORM_APPLICATION_CLASSPATH)) {
classPathEnv.append(ApplicationConstants.CLASS_PATH_SEPARATOR);
classPathEnv.append(c.trim());
}
if (conf.getBoolean(YarnConfiguration.IS_MINI_YARN_CLUSTER, false)) {
classPathEnv.append(':');
classPathEnv.append(System.getProperty("java.class.path"));
}
env.put(Environment.CLASSPATH.name(), classPathEnv.toString());
env.put("appId", appId.toString());
//Build the execute command
List<String> commands = new LinkedList<String>();
StringBuilder command = new StringBuilder();
command.append(Environment.JAVA_HOME.$$()).append("/bin/java ");
command.append("-Dlog4j.configuration=container-log4j.properties ");
command.append("-Dyarn.app.container.log.dir=" +
ApplicationConstants.LOG_DIR_EXPANSION_VAR + " ");
command.append("-Dyarn.app.container.log.filesize=0 ");
command.append("-Dhadoop.root.logger=INFO,CLA ");
command.append("org.apache.hadoop.yarn.examples.ApplicationMaster ");
command.append("1>>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout ");
command.append("2>>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr ");
commands.add(command.toString());
ContainerLaunchContext amContainer = ContainerLaunchContext
.newInstance(localResources, env, commands, null, null, null);
return amContainer;
}
private static void addToLocalResources(FileSystem fs, String fileSrcPath,
String fileDstPath, String appId,
Map<String, LocalResource> localResources)
throws IllegalArgumentException, IOException {
String suffix = "mytest" + "/" + appId + "/" + fileDstPath;
Path dst = new Path(fs.getHomeDirectory(), suffix);
logger.info("hdfs copyFromLocalFile " + fileSrcPath + " =>" + dst);
fs.copyFromLocalFile(new Path(fileSrcPath), dst);
FileStatus scFileStatus = fs.getFileStatus(dst);
LocalResource scRsrc = LocalResource.newInstance(
ConverterUtils.getYarnUrlFromPath(dst), LocalResourceType.FILE,
LocalResourceVisibility.APPLICATION, scFileStatus.getLen(),
scFileStatus.getModificationTime());
localResources.put(fileDstPath, scRsrc);
}
private static void monitorApplicationReport(YarnClient yarnClient, ApplicationId appId) throws YarnException, IOException {
while (true) {
try {
Thread.sleep(5 * 1000);
} catch (InterruptedException e) {
}
ApplicationReport report = yarnClient.getApplicationReport(appId);
logger.info("Got application report " + ", clientToAMToken="
+ report.getClientToAMToken() + ", appDiagnostics="
+ report.getDiagnostics() + ", appMasterHost="
+ report.getHost() + ", appQueue=" + report.getQueue()
+ ", appMasterRpcPort=" + report.getRpcPort()
+ ", appStartTime=" + report.getStartTime()
+ ", yarnAppState="
+ report.getYarnApplicationState().toString()
+ ", distributedFinalState="
+ report.getFinalApplicationStatus().toString()
+ ", appTrackingUrl=" + report.getTrackingUrl()
+ ", appUser=" + report.getUser());
}
}
}1、创建并启动YarnClient端:
YarnClient yarnClient = YarnClient.createYarnClient();
yarnClient.init(conf);
yarnClient.start();2、由于提交的是APP,APP里面包括AM以及Container,先创建APP,得到APP的上下文Context。客户端向RM提交请求,RM首先要创建AMContainer,然后由AMContainer去创建其他的Container,再由AM协调整个的任务,但是AM加创建Container之间形成主从应用。设置应用程序名为”yarnClient.ApplicationMaster”,注意在YARN里面,不允许提交相同名字的应用程序
YarnClientApplication app = yarnClient.createApplication();
app.getApplicationSubmissionContext().setKeepContainersAcrossApplicationAttempts(false);
app.getApplicationSubmissionContext().setApplicationName("yarnClient.ApplicationMaster");3、设置AM资源申请量,比如此处100*10MB,1CPU
Resource capability = Resource.newInstance(100, 1);
app.getApplicationSubmissionContext().setResource(capability);4、设置APP的环境变量以及命令
ContainerLaunchContext amContainer = createAMContainerLanunchContext( conf, app.getApplicationSubmissionContext().getApplicationId());
app.getApplicationSubmissionContext().setAMContainerSpec(amContainer);其中createAMContainerLanunchContext内容如下:
- 将三个程序打包成一个Jar,即资源文件,并将JAR上传多HDFS中,这样多个Container,都能够在HDFS中下载JAR文件,相当于共享缓存。
- 设置CLASSPATH环境变量,并传到AMContainer环境变量中。在提交任务的环境里面,有很多环境变量,但是提交任务给AMContainer时,Container并没有这么多环境变量,没有继承下来环境变量。需要传递给AM。
- 将AppID传递给AM。
- 向Container传递命令,在容器启动时,要执行的命令,用StringBuilder处理,包括ApplicationMaster.java中的Main函数,并设置一序列变量,以及运行该程序时以追加的方式打印日志。
这是就可以启动整个容易了,控制权交给了AM
5、一直监控appId,根据任务执行情况决定什么时候结束打印。
5.4.6.2 ApplicationMaster:ApplicationMaster.java
package org.apache.hadoop.yarn.examples;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.security.PrivilegedExceptionAction;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.TreeMap;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.atomic.AtomicInteger;
import org.apache.commons.io.FilenameUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.net.NetUtils;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.hadoop.util.ClassUtil;
import org.apache.hadoop.yarn.api.ApplicationConstants;
import org.apache.hadoop.yarn.api.ApplicationConstants.Environment;
import org.apache.hadoop.yarn.api.protocolrecords.RegisterApplicationMasterResponse;
import org.apache.hadoop.yarn.api.records.ApplicationAttemptId;
import org.apache.hadoop.yarn.api.records.Container;
import org.apache.hadoop.yarn.api.records.ContainerId;
import org.apache.hadoop.yarn.api.records.ContainerLaunchContext;
import org.apache.hadoop.yarn.api.records.ContainerStatus;
import org.apache.hadoop.yarn.api.records.FinalApplicationStatus;
import org.apache.hadoop.yarn.api.records.LocalResource;
import org.apache.hadoop.yarn.api.records.LocalResourceType;
import org.apache.hadoop.yarn.api.records.LocalResourceVisibility;
import org.apache.hadoop.yarn.api.records.NodeReport;
import org.apache.hadoop.yarn.api.records.Priority;
import org.apache.hadoop.yarn.api.records.Resource;
import org.apache.hadoop.yarn.api.records.timeline.TimelineEntity;
import org.apache.hadoop.yarn.api.records.timeline.TimelineEvent;
import org.apache.hadoop.yarn.api.records.timeline.TimelinePutResponse;
import org.apache.hadoop.yarn.client.api.AMRMClient.ContainerRequest;
import org.apache.hadoop.yarn.client.api.TimelineClient;
import org.apache.hadoop.yarn.client.api.async.AMRMClientAsync;
import org.apache.hadoop.yarn.client.api.async.NMClientAsync;
import org.apache.hadoop.yarn.client.api.async.impl.NMClientAsyncImpl;
import org.apache.hadoop.yarn.conf.YarnConfiguration;
import org.apache.hadoop.yarn.exceptions.YarnException;
import org.apache.hadoop.yarn.util.ConverterUtils;
public class ApplicationMaster {
private final AtomicInteger sleepSeconds = new AtomicInteger(0);
private class LaunchContainerTask implements Runnable {
Container container;
public LaunchContainerTask(Container container) {
this.container = container;
}
private void addToLocalResources(FileSystem fs, String fileSrcPath,
String fileDstPath, String appId,
Map<String, LocalResource> localResources)
throws IllegalArgumentException, IOException {
String suffix = "mytest" + "/" + appId + "/" + fileDstPath;
Path dst = new Path(fs.getHomeDirectory(), suffix);
FileStatus scFileStatus = fs.getFileStatus(dst);
LocalResource scRsrc = LocalResource.newInstance(
ConverterUtils.getYarnUrlFromPath(dst), LocalResourceType.FILE,
LocalResourceVisibility.APPLICATION, scFileStatus.getLen(),
scFileStatus.getModificationTime());
localResources.put(fileDstPath, scRsrc);
}
public void run() {
Map<String, String> env = new HashMap<String, String>();
env.put(Environment.CLASSPATH.name(), System.getenv(Environment.CLASSPATH.name()));
Map<String, LocalResource> localResources = new HashMap<String, LocalResource>();
String thisJar = ClassUtil.findContainingJar(ApplicationMaster.class);
String thisJarBaseName = FilenameUtils.getName(thisJar);
String appId = System.getenv("appId");
Configuration conf = new Configuration();
FileSystem fs;
try {
fs = FileSystem.get(conf);
addToLocalResources(fs, thisJar, thisJarBaseName, appId.toString(),
localResources);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
List<String> commands = new LinkedList<String>();
//commands.add("sleep " + sleepSeconds.addAndGet(1));
StringBuilder command = new StringBuilder();
command.append(Environment.JAVA_HOME.$$()).append("/bin/java ");
command.append("-Dlog4j.configuration=container-log4j.properties ");
command.append("-Dyarn.app.container.log.dir=" +
ApplicationConstants.LOG_DIR_EXPANSION_VAR + " ");
command.append("-Dyarn.app.container.log.filesize=0 ");
command.append("-Dhadoop.root.logger=INFO,CLA ");
command.append("org.apache.hadoop.yarn.examples.JavaPi ");
command.append("1>>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout ");
command.append("2>>" + ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr ");
commands.add(command.toString());
ContainerLaunchContext ctx = ContainerLaunchContext.newInstance(
localResources, env, commands, null, null, null);
amNMClient.startContainerAsync(container, ctx);
LOG.info("Container start... ");
}
}
private class RMCallbackHandler implements AMRMClientAsync.CallbackHandler {
public void onContainersCompleted(List<ContainerStatus> statuses) {
for (ContainerStatus status : statuses) {
LOG.info("Container Completed: " + status.getContainerId().toString()
+ " exitStatus="+ status.getExitStatus());
if (status.getExitStatus() != 0) {
// restart
}
ContainerId id = status.getContainerId();
runningContainers.remove(id);
numCompletedConatiners.addAndGet(1);
}
}
public void onContainersAllocated(List<Container> containers) {
for (Container c : containers) {
LOG.info("Container Allocated"
+ ", id=" + c.getId()
+ ", containerNode=" + c.getNodeId());
exeService.submit(new LaunchContainerTask(c));
runningContainers.put(c.getId(), c);
}
}
public void onShutdownRequest() {
}
public void onNodesUpdated(List<NodeReport> updatedNodes) {
}
public float getProgress() {
float progress = 0;
return progress;
}
public void onError(Throwable e) {
amRMClient.stop();
}
}
private class NMCallbackHandler implements NMClientAsync.CallbackHandler {
public void onContainerStarted(ContainerId containerId,
Map<String, ByteBuffer> allServiceResponse) {
LOG.info("Container Stared " + containerId.toString());
}
public void onContainerStatusReceived(ContainerId containerId,
ContainerStatus containerStatus) {
}
public void onContainerStopped(ContainerId containerId) {
// TODO Auto-generated method stub
}
public void onStartContainerError(ContainerId containerId, Throwable t) {
// TODO Auto-generated method stub
}
public void onGetContainerStatusError(ContainerId containerId,
Throwable t) {
// TODO Auto-generated method stub
}
public void onStopContainerError(ContainerId containerId, Throwable t) {
// TODO Auto-generated method stub
}
}
@SuppressWarnings("rawtypes")
AMRMClientAsync amRMClient = null;
NMClientAsyncImpl amNMClient = null;
AtomicInteger numTotalContainers = new AtomicInteger(10);
AtomicInteger numCompletedConatiners = new AtomicInteger(0);
ExecutorService exeService = Executors.newCachedThreadPool();
Map<ContainerId, Container> runningContainers = new ConcurrentHashMap<ContainerId, Container>();
private static final Log LOG = LogFactory.getLog(ApplicationMaster.class);
@SuppressWarnings("unchecked")
void run() throws YarnException, IOException {
logInformation();
Configuration conf = new Configuration();
// 1. create amRMClient
amRMClient = AMRMClientAsync.createAMRMClientAsync(
1000, new RMCallbackHandler());
amRMClient.init(conf);
amRMClient.start();
// 2. Create nmClientAsync
amNMClient = new NMClientAsyncImpl(new NMCallbackHandler());
amNMClient.init(conf);
amNMClient.start();
// 3. register with RM and this will heartbeating to RM
RegisterApplicationMasterResponse response = amRMClient
.registerApplicationMaster(NetUtils.getHostname(), -1, "");
// 4. Request containers
response.getContainersFromPreviousAttempts();
int numContainers = 10;
for (int i = 0; i < numTotalContainers.get(); i++) {
ContainerRequest containerAsk = new ContainerRequest(
//100*10M + 1vcpu
Resource.newInstance(100, 1), null, null,
Priority.newInstance(0));
amRMClient.addContainerRequest(containerAsk);
}
}
void waitComplete() throws YarnException, IOException{
while(numTotalContainers.get() != numCompletedConatiners.get()){
try{
Thread.sleep(1000);
LOG.info("waitComplete" +
", numTotalContainers=" + numTotalContainers.get() +
", numCompletedConatiners=" + numCompletedConatiners.get());
} catch (InterruptedException ex){}
}
LOG.info("ShutDown exeService Start");
exeService.shutdown();
LOG.info("ShutDown exeService Complete");
amNMClient.stop();
LOG.info("amNMClient stop Complete");
amRMClient.unregisterApplicationMaster(FinalApplicationStatus.SUCCEEDED, "dummy Message", null);
LOG.info("unregisterApplicationMaster Complete");
amRMClient.stop();
LOG.info("amRMClient stop Complete");
}
void logInformation() {
System.out.println("This is System.out.println");
System.err.println("This is System.err.println");
System.out.println(ApplicationConstants.LOG_DIR_EXPANSION_VAR);
String containerIdStr = System
.getenv(ApplicationConstants.Environment.CONTAINER_ID.name());
LOG.info("containerIdStr " + containerIdStr);
ContainerId containerId = ConverterUtils.toContainerId(containerIdStr);
ApplicationAttemptId appAttemptId = containerId
.getApplicationAttemptId();
LOG.info("appAttemptId " + appAttemptId.toString());
}
public static void main(String[] args) throws Exception {
ApplicationMaster am = new ApplicationMaster();
am.run();
am.waitComplete();
}
}- main函数
public static void main(String[] args) throws Exception {- 创建AM
ApplicationMaster am = new ApplicationMaster();- 调用run方式执行
am.run();- 等待完成,并做一些清理工作,比如线程池的关闭
am.waitComplete();
}运行函数:
void run() throws YarnException, IOException- 创建AMRMClient端,即AM要想RM申请资源的客户端,并启动,该客户端可以申请到并运行工作的Container。
- 创建和NM交互的客户端AMNMClient,并启动,该客户端可以申请到并运行工作的Container。
- 注册和RM的心跳信息。
- 申请10个Container,采用事件的驱动方式,以回调的方式反馈给AM。当Container申请成功后,在回调函数里面创建线程池,将任务TASK放在线程池里面管理,将JAR包、命令信息传递给Container。由于JAR包已经上传给了HDFS,就没必要重复上传了。
- 运行JAR包里面的JavaPi程序,将输出以追加的形式输出。
- Client和AM可以通过任务控制台即网页版看见,但是JavaPi是Container无法打印到控制台上,所以需要LOG的形式打印出来。
- 由AMNMClient启动Container,向NM启动Container,因为已经向RM申请好了资源。
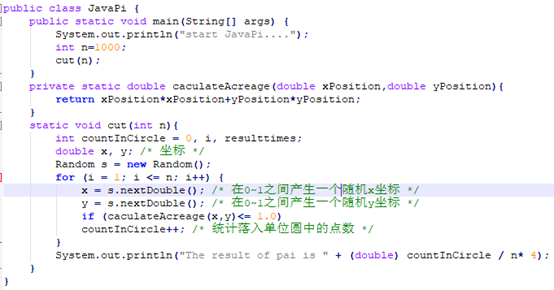
5.4.6.3 Container:JavaPi.java
package org.apache.hadoop.yarn.examples;
import java.util.Random;
public class JavaPi {
public static void main(String[] args) {
System.out.println("start JavaPi....");
int n=1000;
cut(n);
}
private static double caculateAcreage(double xPosition,double yPosition){
return xPosition*xPosition+yPosition*yPosition;
}
static void cut(int n){
int countInCircle = 0, i, resulttimes;
double x, y; /* 坐标 */
Random s = new Random();
for (i = 1; i <= n; i++) {
x = s.nextDouble(); /* 在0~1之间产生一个随机x坐标 */
y = s.nextDouble(); /* 在0~1之间产生一个随机y坐标 */
if (caculateAcreage(x,y)<= 1.0)
countInCircle++; /* 统计落入单位圆中的点数 */
}
System.out.println("The result of pai is " + (double) countInCircle / n* 4); /* 计算出π的值 */
}
}5.4.6.4 编译
用ssh登录到app-11节点,并切换到hadoop用户:su – hadoop
启动集群,并检查集群是否正常工作。
切换到/tmp目录下,创建yarn目录:mkdir yarn
为了保证路径的结构,将文件进行压缩并保留路径:
上传到/tmp/yarn目录
解压缩:tar -xf org.tar
在hadoop集群环境中编译该程序,首先确保该路径在环境变量中。
export HADOOP_CLASSPATH=${JAVA_HOME}/lib/tools.jar
再进行编译
hadoop com.sun.tools.javac.Main org/apache/hadoop/yarn/examples/*.java
查看编译结果:
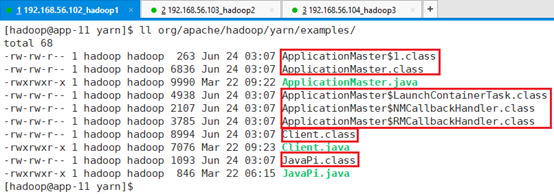
将class文件打包:
jar cf app.jar org/apache/hadoop/yarn/examples/*.class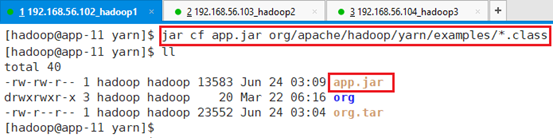
5.4.6.5 运行
用hadoop提交,并运行Client.java中的Client类
hadoop jar app.jar org.apache.hadoop.yarn.examples.Client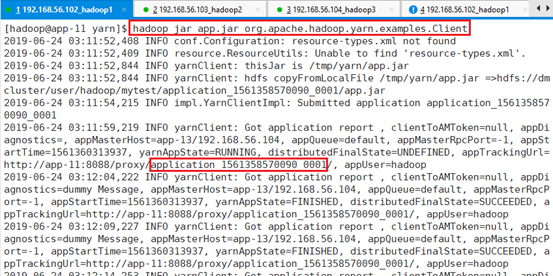
同时为了监控,再启动一个ssh连接app-11,切换到hadoop用户,用yarn top命令监控。
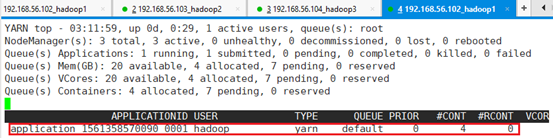
注意:运行页面会一直打印,需要用CTRL+C截止,因为Client文件中用的是while(true)监控
查看日志打印:
有所与执行Container的任务信息:
app-11中有2个:
cd /hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/application_1561358570090_0001/
app-12中有3个:
cd /hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/application_1561358570090_0001/
app-13中有6个:
cd /hadoop/Hadoop/hadoop-3.1.2/logs/userlogs/application_1561358570090_0001/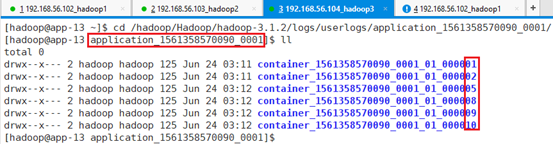
运行了10个任务,显示有11个,其中第一个为打印。
查看输入:
cd container_1557362565463_0001_01_000001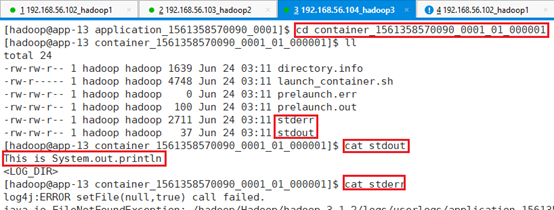
cd container_1557362565463_0001_01_000002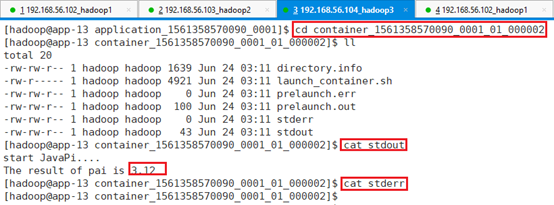
刚好he文件JavaPi.java对应:
关闭集群
这个稍微复杂点,做完这个例子,对整个YARN提交过程有整体了解,有助于后续学习,以及后续出现问题是,能及时找出故障原因,如路径、资源这两个地方出现问题最多,特别是对于初学者,在集群上提交时,容易出现问题。