完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
七、Hive
本章节,主要包括三部分:
1、Hive是解决什么问题的,架构是什么,通过这部分学习能理解Hive到底是什么。
2、动手操作,搭建Hive集群环境,再以SQL语句的查询为核心内容,展开Hive的实际操作部分。
3、Hive的内部机制以及调优。
7.1 Hive是什么
7.1.1 SQL on OLAP
7.1.1.1 Java
在第三章介绍用java程序写的用MapReduce做WordCount程序,相对复杂。
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for (int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job,
new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}是否可以通过更简单的方法,如利用SQL语句做WordCount,之所以会这么思考是因为SQL语句的普及是非常广泛的,而且SQL语句门槛也是相对较低的,因此SQL语句的开发人员数量比较庞大, 而且以SQL语句作为数据分析的开发语言,相对于其他语言成本较低,这是基于这种情况,我们提出了SQL on OLAP(Online Analytical Processing),即用SQL语句的方式实现数据的查询、数据的分析,特别是大数据的查询和分析。
基于此,对于的SQL语句做WordCount如下:
将每一行切开,然后根据word进行排列,再计算每个word的总量,根据word进行分组。
SELECT word,count(1) AS count FROM (SELECT explode(split(,‘\s') ) AS word FROM docs ) w GROUP BY word ORDER BY word;将上述SQL语句进行分开
读取每行,将行按\t分割出一个个字符:
SELECT explode(split(line,’\s’)) AS word FROM docs;分割出的字符,按字符分组进行累计:
SELECT word,count(1) FROM w GROUP BY word按数字排序:
ORDER BY word操作简单,门槛低,不用写JAVA程序,也不需要调试,直接在命令行下就可以。
7.1.1.2 Python
在第三章介绍用Python程序写的用MapReduce做WordCount程序,相对复杂。
WordCountMapper.py:
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
keys = line.split()
for key in keys:
value = 1
print('{0}\t{1}'.format(key, value) ) #the {} is replaced by 0th,1st items in format listWordCountReducer.py:
#!/usr/bin/env python
# ---------------------------------------------------------------
#This reducer code will input a line of text and
# output <word, total-count>
# ---------------------------------------------------------------
import sys
last_key = None
running_total = 0
# -----------------------------------
# loop count
# --------------------------------
for input_line in sys.stdin:
input_line = input_line.strip()
this_key, value = input_line.split("\t", 1)
value = int(value)
if last_key == this_key:
running_total += value # add value to running total
else:
if last_key:
print( "{0}\t{1}".format(last_key, running_total) )
running_total = value #reset values
last_key = this_key
if last_key == this_key:
print( "{0}\t{1}".format(last_key, running_total))相对于SQL语句来说,也是相对复杂。
所以说用SQL语句作为大数据分析的语言,可以有效、合理而且直观的组织和使用数据模型,以降低数据分析的门槛,这就是Hive能够发展起来的动力。
但是这并不是说其他编程语言的接口就没有价值,它们所解决问题的层次是不一样的,在其他的数据处理框架,如Spark、Flink它们都有对应的SQL语句相关的接口,SQL语句不仅可以在静态数据集用,而且可以进入动态表的流上也可以用SQL语句,这就是SQL语句在大数据分析的动力及原因。
再次强调并不说明其他语言进行大数据处理没有价值或者将会被SQL淘汰,因为他们解决问题的层次不一样,有一些仍然需要Scala、Java或者Python这种表现力更丰富的语言去做处理,SQL语句能够处理的领域是SQL能够表现的场景。
这些框架所使用的语言依然是底层语言来编写,可以这么认为用高级语言编写的数据处理程序效率会更高,而且相应的框架会对原生的比如说Java语言、Scala语言等的支持融合度更好,因为框架本身如用Java、Scala等写的,其支持或者融合度会更好。
7.1.2 Hive Arch
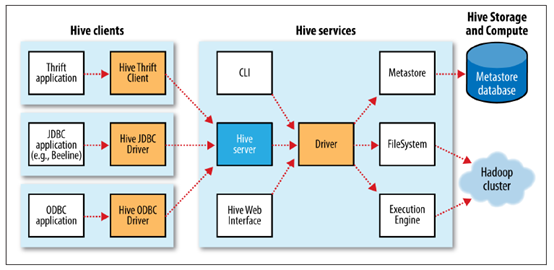
在了解为什么引入Hive之后,再进一步了解Hive的架构。Hive包含了三个部分:Hive Clients(客户端)、Hive的Services(服务端)、Hive的Metastore(元数据存储)。
Hive Clients有三类,Thrift Client、JDBC Driver、ODBC Driver,通过Client连接Hive Server。
Hive Server经过一序列的Driver,将查询驱动数据仓库(文件),Hive 将HDFS里面的一个个文件变成或者抽象成结构化数据,然后用SQL语句查询、分析这些文件内容,Hive Server需要将查询SQL语言转换为一序列的MapReduce或者Tez,以DAG形式提交给集群去执行响应的数据处理程序,即调取HDFS文件做MapReduce操作。除了Hive Server之外,还可以通过Hive Services提供的客户端CLI,这将是接下来将要操作的重要工具,此外还可以通过Web界面的形式操作SQL语句,后续实例主要还是以CLI的形式操作数据库,或者叫大数据仓库,这就是整个体系架构。
Metastore,是因为Hive上存的都是一个个文件,文件里面都是一行行数据或记录,为了执行SQL语句,需要了解数据的格式信息,所谓元数据信息,这就是Metastore需要存储的基本信息,Metastore不存数据,数据存于HDFS中,Metastore存储在关系型数据库里面,如MySQL中。
7.1.3 Hive metastore
基于Metastore(元数据存储)的重要性,本部分详细分析Metastore。
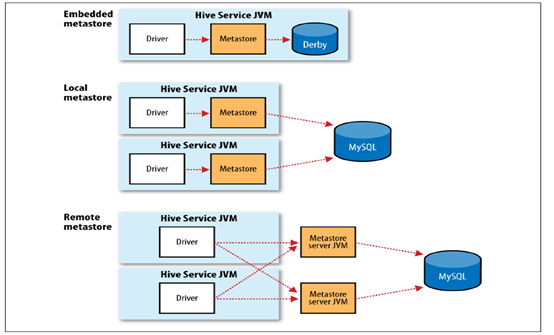
可以有多种Metastore的后端,MySQL是比较常用的,三种部署方式:
- Hive里面提供了内置的Metastore。
- 可以通过本地的Metastore方式,将MySQL部署在Hive Services所在的JVM所在的机器上。
- 支持远程的JVM访问MySQL。
本课程将采用第三种部署方式,即Hive Services和MySQL不在同一台机器上。
通过前面的讲述,Hive是一个计算引擎,唯一接触到数据或者存储数据的地方就是Metastore,而且存储的仅仅是元数据,所有待分析的数据都存在HDFS中,由HDFS保证数据的安全一致性。
如果Hive做HA,仅仅需要保证Hive的Metastore HA、高可用性。通常情况下,可以用MySQL做集群。
本课程并没有用MySQL做HA,用MySQL做HA是IT系统必备的一个能力,所以本课程没有重复MySQL做HA的内容。
7.1.4 vs OLTP databases
本部分深入理解分析Hive和传统的OLTP(On-Line Transaction Processing)数据库区别。
Hive并不存储数据,仅仅存储元数据信息,数据都是以文件形式存储在HDFS中,或者说有一些数据文件直接可以绕过Hive存到HDFS中,更新Metastore可以通过Hive Client端去查询处理。传统的关系型数据库所有的数据信息以及数据的描述信息都在关系型数据库里面,如果数据或描述信息丢了,将很难恢复。但是在Hive里面,如果数据没有丢失,Metastore丢失了,通过数据恢复Metastore相对容易。
读模式和写模式,在传统数据库里面,表的模式是在数据加载时强制确定的,也就是说存储后,数据的模式已经存储,如果在加载时发现数据不符合模式,加载肯定是失败的,因为需要进行一序列数据结构信息的检查,这就是传统关系型数据库。Hive是在查询时进行读时模式的检查,查询时才检查要查询的文件在我们的元数据里面是不是匹配的,文件的结构信息和元数据存储的结构信息是不是匹配的,在写入时,可以绕过Hive写入HDFS,只要结构性信息在查询时和Metastore对应上就行,这是和关系型数据库区别最明显的地方。
Hive是基于HDFS,可以进行大数据量的存储,集群可以扩展的很大,而传统的关系型数据库则很难做到这一点,关系型数据库要进行OLTP的事务的处理。
性能不一样,Hive这种模式数据加载非常快速,不需要检查数据格式信息,直接写入HDFS即可,传统关系型数据库则不一样,写入时必须一条条检查是否满足,但是关系型数据库查询性能非常高,可以进行数据的索引,索引虽然付出了存储空间的代价,但是得到了速度的提升,而Hive或者说大数据使用全部扫描的方式,Hive也可以做索引,但是基本原理还是要进行蛮力扫描整个数据。关系型数据库加载时做了处理,如格式检查,索引,获得了查询的效率的提升,而Hive则相反,Hive不需要加载时的判别解析,且使用蛮力的方式遍历全量数据,性能往往不如关系型数据库,但是Hive可以做到大尺度的数据。
更新、事务以及索引操作,由传统关系型数据库需要做事务处理,对事务性处理是Hive所不能比的。Hive是基于全表扫描,而且Hive不支持更新、删除等操作,也不支持插入,是一次加载,多次使用的静态数据。但是Hive可以和OLTP类数据库结合,如HBase,可以做到更新操作。
本模块限定在一次加载多次使用的模式,即批处理模式,不引入数据更新、事务、索引之类的操作。
7.2 Hive环境安装
了解Hive基本架构后,开始Hive环境的搭建,分为两步,第一步安装MySQL,第二部安装Hive。
将MySQL和Hive同时安装在app-12上,因为app-11已经承担了很多角色,将负载均衡到app-12上,由于使用的是远程的metastore方式,将使用主机名加端口号达到远程metastore模式的效果。
安装命令,便于用户安装:

#!/bin/sh
mount -t iso9660 /dev/cdrom /mnt
# 安装mysql
yum remove -y *mariadb*
yum remove -y *mysql-community*
yum localinstall -y $LOCAL_DIR/mysql-community-common-5.7.18-1.el7.x86_64.rpm
yum localinstall -y $LOCAL_DIR/mysql-community-libs-5.7.18-1.el7.x86_64.rpm
yum localinstall -y $LOCAL_DIR/mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm
yum localinstall -y $LOCAL_DIR/mysql-community-client-5.7.18-1.el7.x86_64.rpm
yum localinstall -y $LOCAL_DIR/mysql-community-devel-5.7.18-1.el7.x86_64.rpm
yum localinstall -y $LOCAL_DIR/mysql-community-server-5.7.18-1.el7.x86_64.rpm
systemctl start mysqld.service
grep "A temporary password is generated for" /var/log/mysqld.log
# ALTER_MYSQL_PASSWD_EXP_CMD
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Yhf_1018';
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'Yhf_1018' with grant option;
FLUSH privileges;
quit;
#安装Hive
mkdir -p /hadoop/Hive
tar -xf -C
upload hive-site.xml hive-log4j2.properties
#Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
# at [row,col,system-id]: [3210,96,"file:/hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml"]
sed -i -E '3210d' /hadoop/Hive/apache-hive-3.1.1-bin/conf/hive-site.xml
#zookeeper
#metastore
#tmpdir
mkdir /hadoop/Hive/apache-hive-3.1.1-bin/{tmp,log}
export HIVE_HOME=/hadoop/Hive/apache-hive-3.1.1-bin
export PATH=${HIVE_HOME}/bin:$PATH
drop database if exists hive
create database hive
upload mysql-connector-java-5.1.46.jar ./lib/
cd /hadoop/Hive/apache-hive-3.1.1-bin/bin && ./schematool -dbType mysql -initSchema
cd /hadoop/Hive/apache-hive-3.1.1-bin/bin && nohup ./hive --service metastore > /hadoop/Hive/apache-hive-3.1.1-bin/log/metastore.log 2>&1 &接下来,按照安装脚本一步步安装
7.2.1 安装Mysql
启动三台虚拟机。
7.2.1.1 上传文件
ssh连接到app-12,切换到hadoop用户,同时切换到/hadoop目录。

在/tmp目录下创建mysql目录:mkdir mysql
上传文件到/tmp/mysql目录:
7.2.1.2 安装
安装需要在root用户下进行,切换回root目录:exit
切换到/tmp/mysql目录下:
卸载所有的关于MySQL的安装版本文件:yum remove -y *mariadb*
卸载所有和MySQL社区相关的版本:yum remove -y *mysql-community*
- 使用yum安装,注意顺序:
yum install -y mysql-community-common-5.7.18-1.el7.x86_64.rpm
yum install -y mysql-community-libs-5.7.18-1.el7.x86_64.rpm
yum install -y mysql-community-libs-compat-5.7.18-1.el7.x86_64.rpm
yum install -y mysql-community-client-5.7.18-1.el7.x86_64.rpm
yum install -y mysql-community-devel-5.7.18-1.el7.x86_64.rpm
yum install -y mysql-community-server-5.7.18-1.el7.x86_64.rpm
启动MySQL:systemctl start mysqld.service
同时确认MySQL进程启动: ps -ef | grep mysqld

7.2.1.3 配置
目前的密码是随机生成的,位于:/var/log/mysqld.log
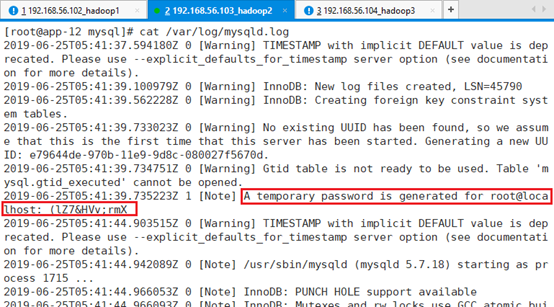
用默认的root密码登录:mysql -uroot –p
注:此处默认密码为红线标注的:(lZ7&HVv;rmX
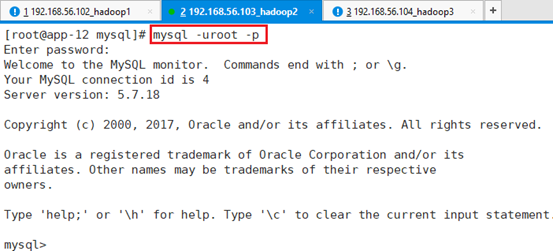
将密码修改为:Yhf_1018
ALTER USER 'root'@'localhost' IDENTIFIED BY 'Yhf_1018';赋权限
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'Yhf_1018' with grant option;刷新并退出
FLUSH privileges;
quit;
重新用新密码登录,确认是否成功
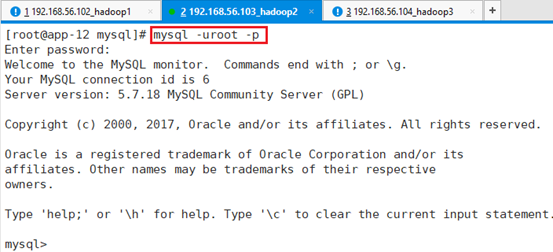
7.2.2 安装Hive
7.2.2.1 上传文件
ssh连接到app-12,切换到hadoop用户,同时切换到/hadoop目录。
在/hadoop目录下创建Hive安装的根目录:mkdir Hive
上传安装文件至/hadoop/Hive目录下


解压缩到本地:tar -xf apache-hive-3.1.1-bin.tar.gz
7.2.2.2 配置文件
主要涉及两个配置文件

7.2.2.2.1 hive-site.xml
通过模板文件hive-default.xml.template对比,修改如下:
指定Hive的DDL/DML作业计算结果本地存储目录
<property>
<name>hive.exec.local.scratchdir</name>
<value>/hadoop/Hive/apache-hive-3.1.1-bin/tmp</value>
<description>Local scratch space for Hive jobs</description>
</property>用于向远程文件系统添加资源的本地临时目录
<property>
<name>hive.downloaded.resources.dir</name>
<value>/hadoop/Hive/apache-hive-3.1.1-bin/tmp/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>修改metastore的url,指向的是运行metastore服务的主机,这是hive客户端配置,metastore服务不需要配置,在app-12上
<property>
<name>hive.metastore.uris</name>
<value>thrift://app-12:9083</value>
<description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
</property>MySQL连接密码,以及连接字符串
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>Yhf_1018</value>
<description>password to use against metastore database</description>
</property> <property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://app-12:3306/hive?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>创建一序列schema,关闭掉校验。
由于第一次启动metastore服务时,mysql作为数据源的hive数据库内没有生成任何表和数据,所以会出现返回的版本号为空的情况。我们可以暂时在hive.metastore.schema.verification里设置成false,在第一次启动自动生成了数据后,那么就可以将这个配置值再改回true,往后也相关无事了。
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in is compatible with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manually migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>MySQL的Driver及用户名
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property> <property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>Username to use against metastore database</description>
</property>查询log
<property>
<name>hive.querylog.location</name>
<value>/hadoop/Hive/apache-hive-3.1.1-bin/tmp</value>
<description>Location of Hive run time structured log file</description>
</property>开启锁机制
<property>
<name>hive.support.concurrency</name>
<value>true</value>
<description>
Whether Hive supports concurrency control or not.
A ZooKeeper instance must be up and running when using zookeeper Hive lock manager
</description>
</property>配置zookeeper的三台机器,分布式协调,端口号用默认的
<property>
<name>hive.zookeeper.quorum</name>
<value>app-11,app-12,app-13</value>
<description>
List of ZooKeeper servers to talk to. This is needed for:
1. Read/write locks - when hive.lock.manager is set to
org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager,
2. When HiveServer2 supports service discovery via Zookeeper.
3. For delegation token storage if zookeeper store is used, if
hive.cluster.delegation.token.store.zookeeper.connectString is not set
4. LLAP daemon registry service
5. Leader selection for privilege synchronizer
</description>
</property> <property>
<name>hive.server2.logging.operation.log.location</name>
<value>/hadoop/Hive/apache-hive-3.1.1-bin/tmp/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</description>
</property>将Hive的执行引擎从MR切换到tez
<property>
<name>hive.execution.engine</name>
<value>tez</value>
<description>
Expects one of [mr, tez, spark].
Chooses execution engine. Options are: mr (Map reduce, default), tez, spark. While MR
remains the default engine for historical reasons, it is itself a historical engine
and is deprecated in Hive 2 line. It may be removed without further warning.
</description>
</property>7.2.2.2.2 hive-log4j2.properties
status = INFO
name = HiveLog4j2
packages = org.apache.hadoop.hive.ql.log
# list of properties
property.hive.log.level = INFO
property.hive.root.logger = DRFA
property.hive.log.dir = /hadoop/Hive/apache-hive-3.1.1-bin/tmp
property.hive.log.file = hive.log
property.hive.perflogger.log.level = INFO
# list of all appenders
appenders = console, DRFA
# console appender
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{ISO8601} %5p [%t] %c{2}: %m%n
# daily rolling file appender
appender.DRFA.type = RollingRandomAccessFile
appender.DRFA.name = DRFA
appender.DRFA.fileName = ${sys:hive.log.dir}/${sys:hive.log.file}
# Use %pid in the filePattern to append <process-id>@<host-name> to the filename if you want separate log files for different CLI session
appender.DRFA.filePattern = ${sys:hive.log.dir}/${sys:hive.log.file}.%d{yyyy-MM-dd}
appender.DRFA.layout.type = PatternLayout
appender.DRFA.layout.pattern = %d{ISO8601} %5p [%t] %c{2}: %m%n
appender.DRFA.policies.type = Policies
appender.DRFA.policies.time.type = TimeBasedTriggeringPolicy
appender.DRFA.policies.time.interval = 1
appender.DRFA.policies.time.modulate = true
appender.DRFA.strategy.type = DefaultRolloverStrategy
appender.DRFA.strategy.max = 30
# list of all loggers
loggers = NIOServerCnxn, ClientCnxnSocketNIO, DataNucleus, Datastore, JPOX, PerfLogger, AmazonAws, ApacheHttp
logger.NIOServerCnxn.name = org.apache.zookeeper.server.NIOServerCnxn
logger.NIOServerCnxn.level = WARN
logger.ClientCnxnSocketNIO.name = org.apache.zookeeper.ClientCnxnSocketNIO
logger.ClientCnxnSocketNIO.level = WARN
logger.DataNucleus.name = DataNucleus
logger.DataNucleus.level = ERROR
logger.Datastore.name = Datastore
logger.Datastore.level = ERROR
logger.JPOX.name = JPOX
logger.JPOX.level = ERROR
logger.AmazonAws.name=com.amazonaws
logger.AmazonAws.level = INFO
logger.ApacheHttp.name=org.apache.http
logger.ApacheHttp.level = INFO
logger.PerfLogger.name = org.apache.hadoop.hive.ql.log.PerfLogger
logger.PerfLogger.level = ${sys:hive.perflogger.log.level}
# root logger
rootLogger.level = ${sys:hive.log.level}
rootLogger.appenderRefs = root
rootLogger.appenderRef.root.ref = ${sys:hive.root.logger}和模板文件hive-log4j2.properties.template对比,更改如下
只修了LOG的目录
property.hive.log.dir = /hadoop/Hive/apache-hive-3.1.1-bin/tmp7.2.2.2.3 上传
- 将两个配置文件上传到:/hadoop/Hive/apache-hive-3.1.1-bin/conf/
7.2.2.2.4 tmp和log目录
在/hadoop/Hive/apache-hive-3.1.1-bin 目录下创建tmp和log目录:
mkdir {tmp,log}
7.2.2.3 环境变量
添加环境变量:vi ~/.bashrc
export HIVE_HOME=/hadoop/Hive/apache-hive-3.1.1-bin
export PATH=${HIVE_HOME}/bin:$PATH
让环境变量生效:source ~/.bashrc
7.2.2.4 创建metastore
切换到root,做MySQL相关操作:exit
登录:mysql -uroot -p
创建metastore数据库:
删除现有:drop database if exists hive;
创建数据库:create database hive;
显示数据库:show databases;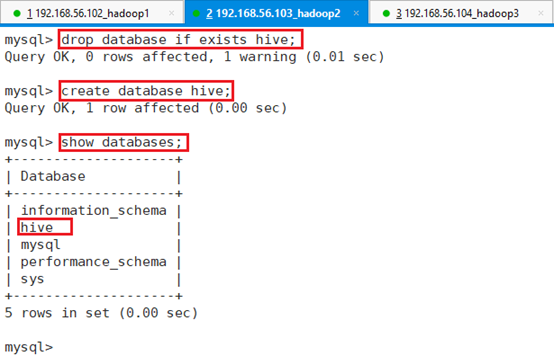
quit退出
7.2.2.5 初始化并启动
切回到hadoop用户
初始化前,需要将MySQL连接的驱动mysql-connector-java-5.1.46.jar上传到/hadoop/Hive/apache-hive-3.1.1-bin/lib下。


开始初始化Hive的metastore。
在bin目录下:./schematool -dbType mysql -initSchema
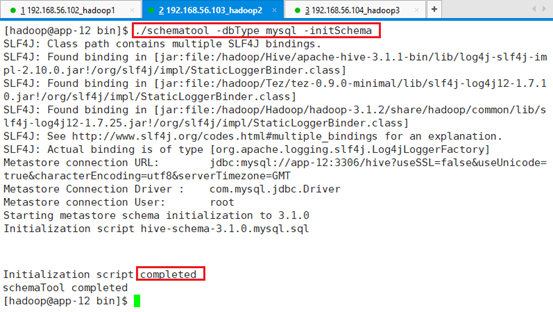
启动Hive Service
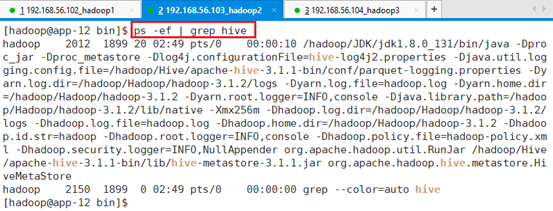
需要将Hive放到后台服务,使用nohup启动metastore服务,并将所有的打印输出到log下
nohup ./hive --service metastore > /hadoop/Hive/apache-hive-3.1.1-bin/log/metastore.log 2>&1 &
查看进程:ps -ef | grep hive
7.2.2.6 CLI
已经启动了,进入命令行:./hive
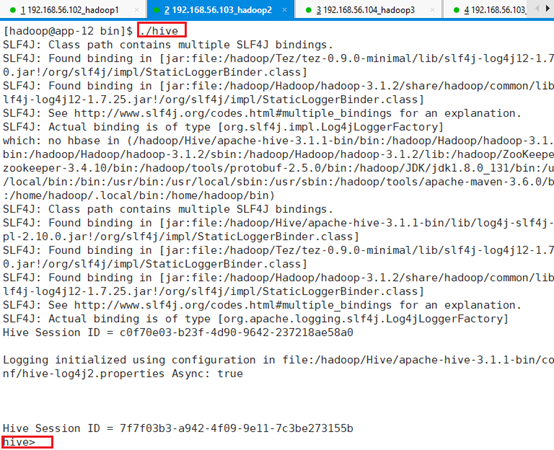
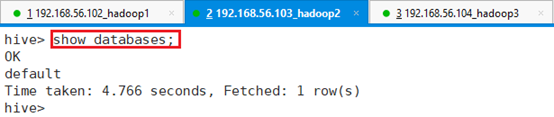
查看数据库:show databases;
目前还没有创建,所以显示空。
CTRL+C退出
7.2.2.7 清理
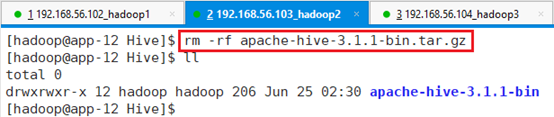
删除安装文件:rm -rf apache-hive-3.1.1-bin.tar.gz
7.2.2.8 启停
将config.conf、startAll.sh和stopAll.sh上传到/hadoop目录
赋予可执行权限:chmod a+x startAll.sh stopAll.sh
修改config.conf文件,将MYSQL和HIVE配置启用:vi config.conf
7.2.2.8.1 停止
在app-11节点切换到haoop用户,进入/hadoop目录,执行命令:./stopAll.sh
查看进程:jps



7.2.2.8.2 启动
用ssh连接到app-11节点,切换到hadoop用户,同时切换到/hadoop目录
执行命令:./startAll.sh
查看进程:jps
查看hive:./hive
7.3 基本命令行操作
这部分主要面向三个问题:
- Hive命令行基本操作与配置;
- 如何运行Hive脚本;
- 如何通过Hive命令行操作hadoop的HDFS,解决另一个疑问就是Hive的配置中并没有提到和Hadoop相关的配置,为什么Hive能够启动HDFS。
ssh连接到app-12节点,切换到haoop用户
7.3.1 基本命令
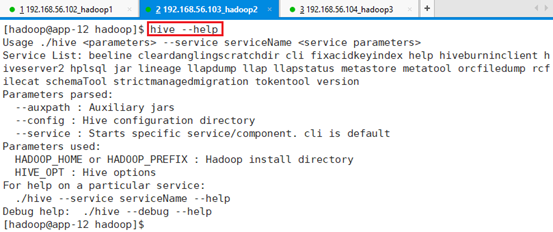
7.3.1.1 hive –help
查看hive支持哪些命令,
Hive中有HADOOP_HOME参数的设置,传递了HADOOP安装信息,因为环境变量里面已经有了HADOOP_HOME的配置,所以说Hive在配置的时候看起来没有配置任何和HADOOP相关的配置,但是Hive仍然能够正常启动的原因,因为Hive是架构在HDFS上的。
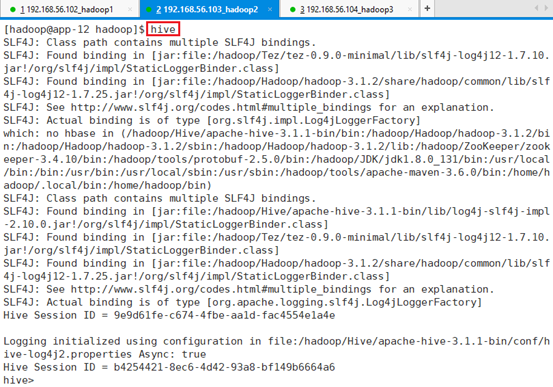
7.3.1.2 hive
启动客户端,目前功能比较弱,也不支持自动补偿功能,需要做一些设置。
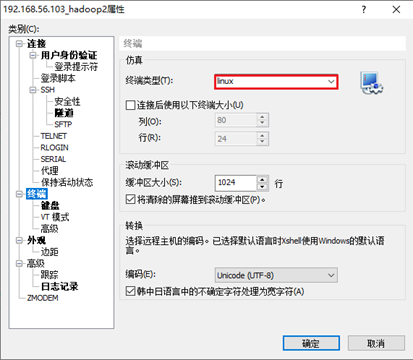
将SSH终端类型这是为linux:
使用Ctrl+C退出后,再次使用命令进入命令行环境:hive –service cli
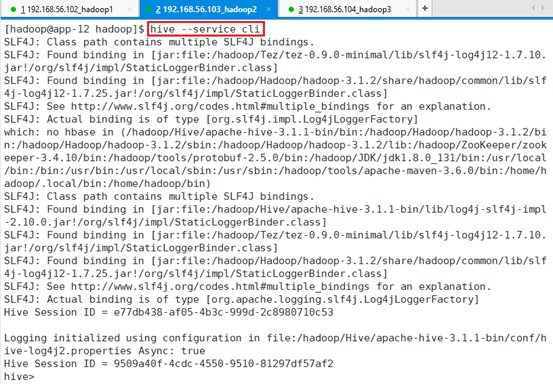
这是就可以实现tab自动补填了

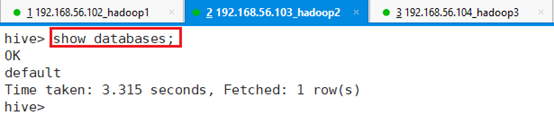
7.3.1.3 show databases
显示数据库:show databases;
7.3.1.4 quit
退出命令行

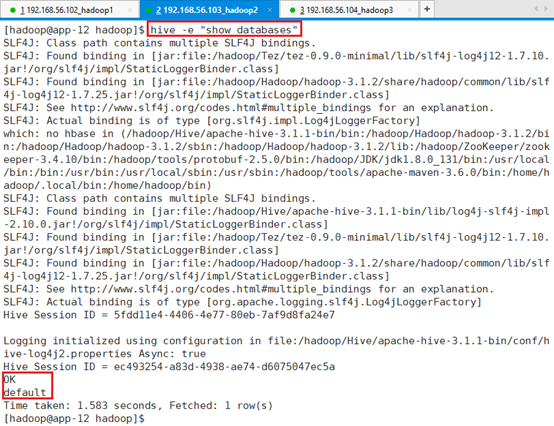
7.3.1.5 hive -e
一次使用的命令:hive -e “show databases”
查询完后直接回到命令行环境,而不是hive的命令行环境。
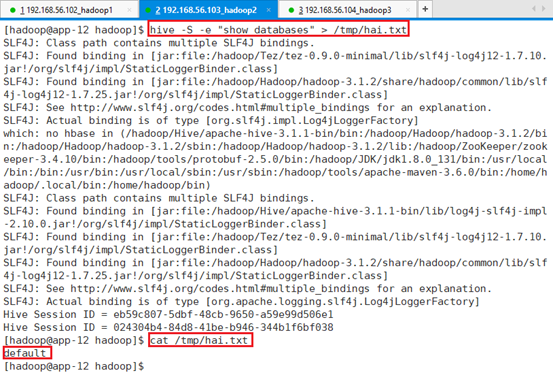
静默输出:hive -S -e “show databases” > /tmp/hai.txt
7.3.2 操作HDFS
进入命令行:hive –service cli
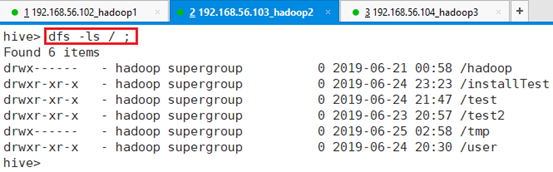
7.3.2.1 dfs -ls
显示目录信息:dfs -ls / ;
用的是hive环境执行HDFS命令,而不是用hadoop执行,所以前面不需要hdfs。
7.3.2.2 模式启动失败
只修改本终端的环境变量实验,而不是修改整个的。
去除环境变量HADOOP_HOME:unset HADOOP_HOME

从PATH中去除HADOOP相关环境路径
export PATH=/hadoop/Hive/apache-hive-3.1.1-bin/bin:/hadoop/JDK/jdk1.8.0_131/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hadoop/.local/bin:/home/hadoop/bin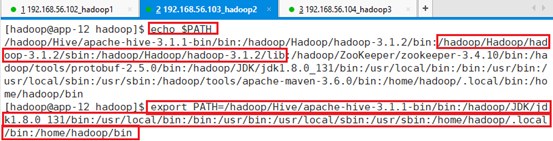
启动命令端:hive –service cli

提示表明依赖的两个条件:
- 需要有HADOOP_HOME;
- 需设置HADOOP PATH;
7.4 HiveQL数据定义
Hive查询语言(HiveQL Hive Query Language)
重启新的终端,连接到app-12,并切换到hadoop用户。
进入命令行:hive –service cli
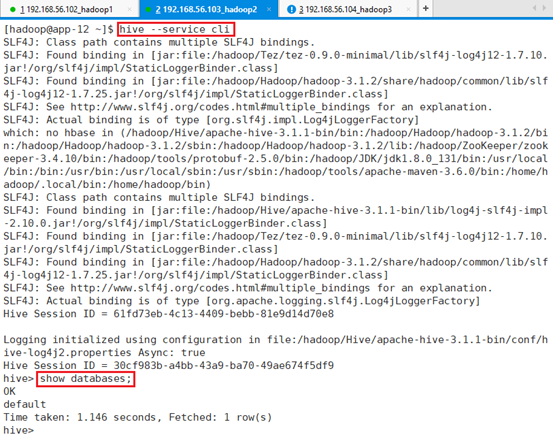
7.4.1 创建数据库
创建数据库:create database if not exists test;
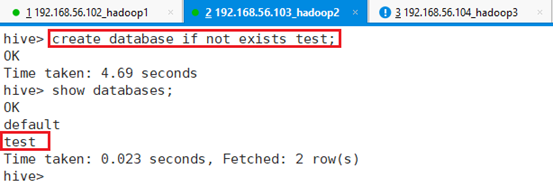
7.4.2 创建表
进入数据库test:use test;

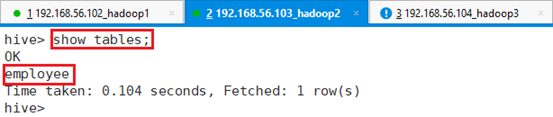
查看该库下是否存在表:show tables;

创建表:行用|符号隔开:
hive> CREATE TABLE IF NOT EXISTS `EMPLOYEE`(
> `ID` bigint,
> `NAME` string,
> CONSTRAINT `SYS_PK_BUCKETING_COLS` PRIMARY KEY (`ID`) DISABLE
> )
> ROW FORMAT DELIMITED FIELDS TERMINATED BY '\|';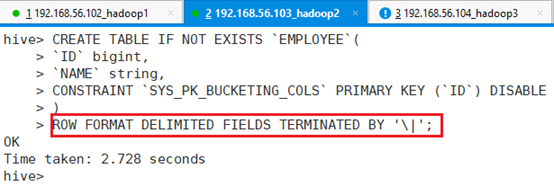
再查看表是否存在:show tables;
7.4.3 导入数据
加载数据到table中,测试数据,左边ID号,右边NAME,中间用|分开

16|john
17|robert
18|andrew
19|katty
21|tom
22|tim
23|james
24|paul
27|edward
29|alan
31|kerry
34|terri另起一个ssh连接到app-12,切换到hadoop用户
在/tmp目录下新建hive目录:mkdir hive
并将文件employee.dat上传到该目录下:

回到HIVE命令,加载数据并导入表中
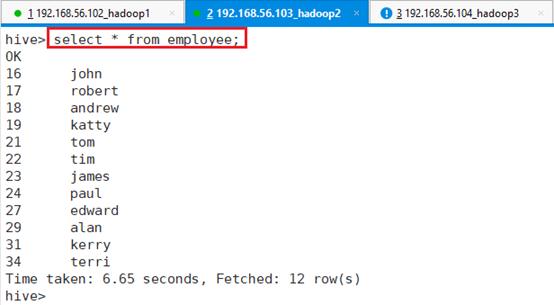
LOAD DATA LOCAL INPATH '/tmp/hive/employee.dat' OVERWRITE INTO TABLE EMPLOYEE;
表数据查询:select * from employee;
7.4.4 HDFS关系
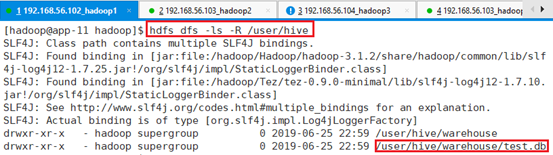
创建完数据库和表之后,HDFS发生的变化,由于Hive是计算框架,数据存在HDFS中,配置文件里面设置的默认数据库存储仓库存储位置是Hive。Hive内部表都属于缺省库default,在HDFS的目录为/user/hive/warehouse/。
hdfs dfs -ls /user/hive/warehouse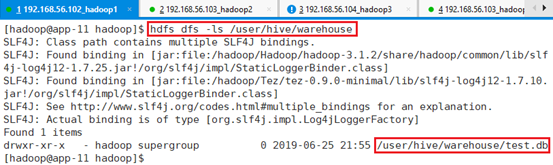
进入数据文件目录,存在表格文件夹
hdfs dfs -ls /user/hive/warehouse/test.db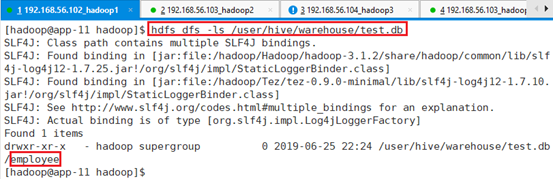
进入表文件夹:
hdfs dfs -ls /user/hive/warehouse/test.db/employee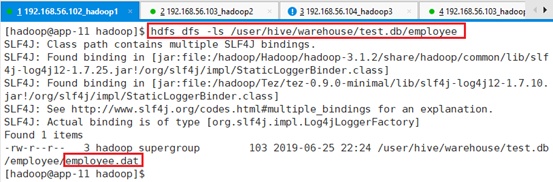
打开文件查看导入的数据集,和之前LOAD进去的一样:
hdfs dfs -cat /user/hive/warehouse/test.db/employee/employee.dat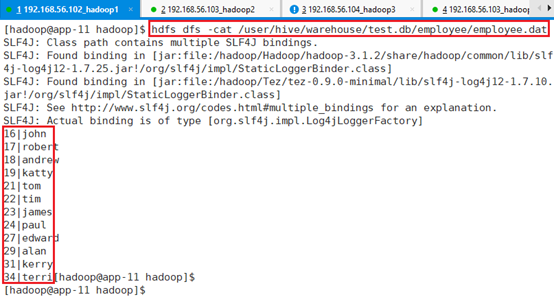
所以说Hive的机制就是将HDFS上的数据进行MapReduce,进行数据处理,仅仅是一个计算框架,而且以HDFS上的文件或者目录来管理数据结构。
7.4.5 MySQL关系
检查metastore发生了哪些变化
使用Navicat for MySQL连接app-12节点的MySQL

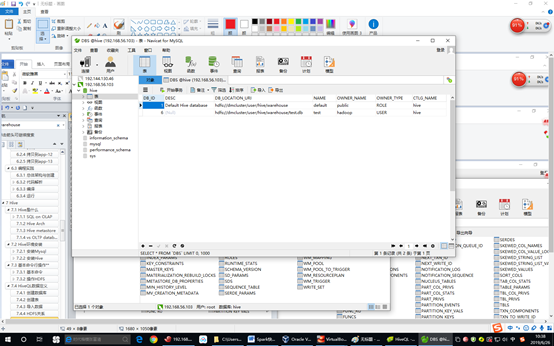
连接成功后,在MySQL数据库上有一个之前已经创建的hive数据库:
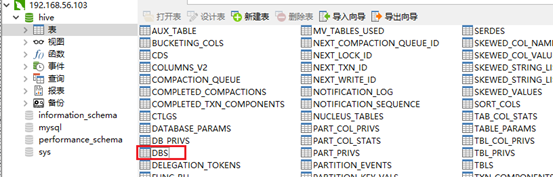
找到DBS表:
双击进入表
记录了名字以及对应的文件/目录地址,创建的用户名,这就是Hive里面的DB在metastore中体现的一行。
再找到表格所在地:找到TBLS,
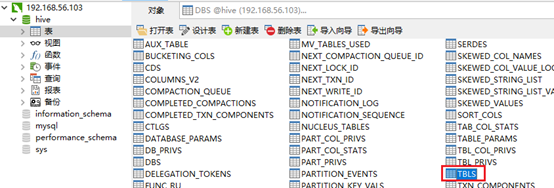
双击打开,里面记录了表名

里面还记录了表的权限,数据库权限,由于没有配置,所以都没有记录。
关系总结:
- 在MySQL上创建metastore数据库,数据库名:hive;
- 在Hive上创建数据库,比如test;
- 在Hive数据库test上根据需要导入的数据格式创建表,比如employee;
- 创建的数据库test和表employee默认位于HDFS:/user/hive/warehouse;
- 在MySQL的数据库hive表DBS中,自动记录了Hive上的数据库test和表employee在HDFS中的位置;
- 在MySQL的数据库hive表TBLS中,自动记录了Hive上表employee的属性信息,包括创建时间,创建人,表名等;
7.4.6 外部表/内部表
外部表和刚才创建的表的区别,外部表创建的数据文件不受Hive的管控,相对于外部表来说,内部表受Hive的管控。当DROP内部表之后,对应的数据存储文件也会DROP掉,而外部表则相反,外部表DROP之后,表的元数据即存在metastores里面的数据或者MySQL里面的数据会被删掉,但是文件数据并没有权限删除。
7.4.6.1 内部表
将数据备份到另一个位置:
hdfs dfs -cp /user/hive/warehouse/test.db/employee/employee.dat /installTest/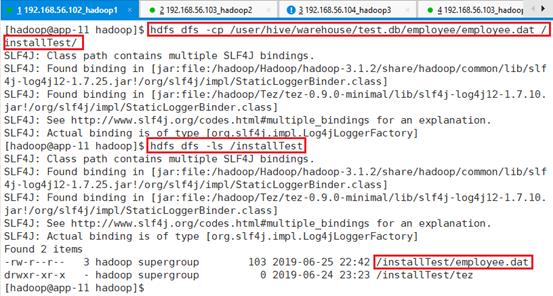
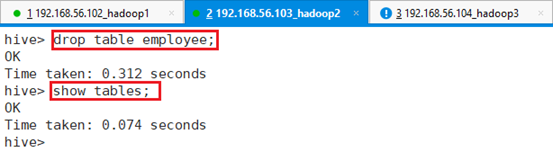
回到app-12,在hive命令行下删除表:drop table employee;
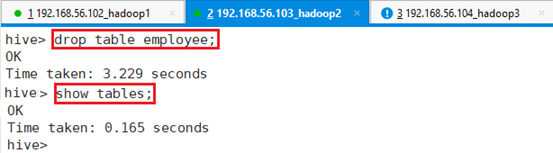
再查看HDFS文件上的数据文件是否存在
hdfs dfs -ls /user/hive/warehouse/test.db/,显示数据文件已经删除。
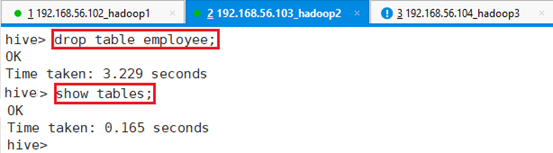
查看MySQL表,显示表信息为空

删除数据库test:drop database test;
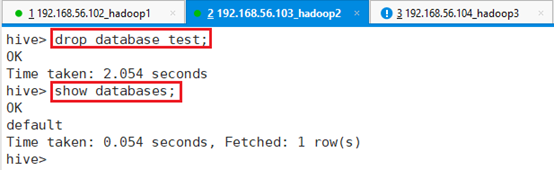
在查看HDFS文件:hdfs dfs -ls /user/hive/warehouse/
数据块已经删除。
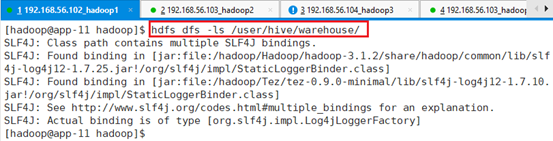
查看MySQL数据库,数据库test信息已清空

7.4.6.2 外部表
创建外部表,表格数据要占整个目录。
先将数据放在一个空目录下,在HDFS下面创建临时目录hive:
hdfs dfs -mkdir /installTest/hive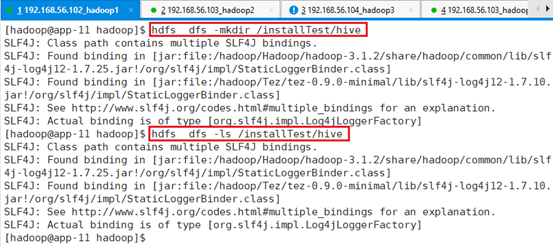
将备份的数据拷贝到该目录下
hdfs dfs -cp /installTest/employee.dat /installTest/hive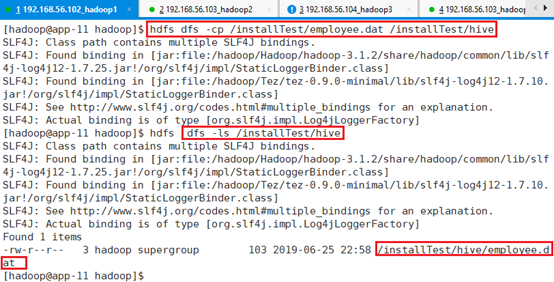
创建数据库:create database if not exists test;
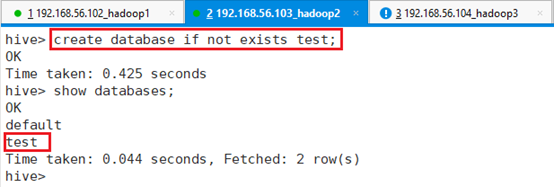
创建外部表:
CREATE EXTERNAL TABLE IF NOT EXISTS `EMPLOYEE`(
`ID` bigint,
`NAME` string,
CONSTRAINT `SYS_PK_BUCKETING_COLS` PRIMARY KEY (`ID`) DISABLE
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\|'
LOCATION '/installTest/hive';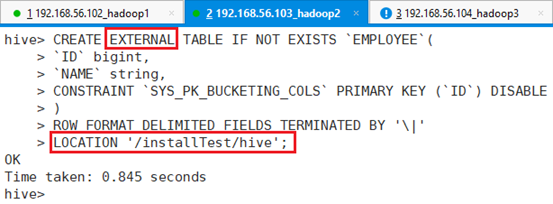
查询:select * from employee;
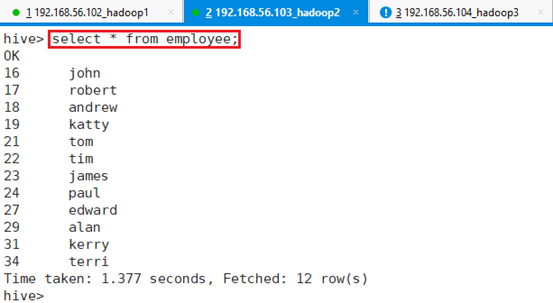
查看HDFS目录/user/hive/warehouse/,并没有employee
查看MySQL表DBS,有对应数据库信息

查看MySQL表TBLS,有对应表信息

外部表的数据不受hive的管控。
删除数据库表:drop table employee;
对应MySQL的TBLS表信息清空

查看数据文件是否还存在:hdfs dfs -ls /installTest/hive
数据还存在,数据并没有删除。

7.5 HiveQL查询
本部分不打算详细展开,因为HiveQL语言和传统的关系数据库查询语言基本类似。SQL语言的门槛低以及理解SQL操作的工程师队伍庞大,这也是Hive流行的一个原因。
本部分主要讲其背后的执行机制,比如说安装了Tez、MapReduce后,之前select查询不需要MR操作,因为没有涉及到计算操作。
7.5.1 hive –f运行脚本
清空/tmp/hive目录:rm -rf hive
上传脚本文件到/tmp/hive:

脚本用来创建内部表,并加载数据:employee.sql
CREATE DATABASE IF NOT EXISTS test;
USE test;
DROP TABLE IF EXISTS `EMPLOYEE`;
CREATE TABLE IF NOT EXISTS `EMPLOYEE` (
`ID` bigint,
`NAME` string,
CONSTRAINT `SYS_PK_BUCKETING_COLS` PRIMARY KEY (`ID`) DISABLE
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\|' ;
--STORED BY 'org.apache.hive.storage.jdbc.JdbcStorageHandler'
LOAD DATA LOCAL INPATH '/tmp/hive/employee.dat'
OVERWRITE INTO TABLE EMPLOYEE;
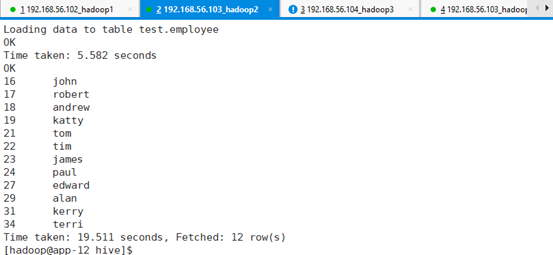
select * from EMPLOYEE;加载脚本:hive -f /tmp/hive/employee.sql
包括:创建库、创建表、导入数据、查询数据。
7.5.2 tez引擎
切换到命令行环境:hive –service cli
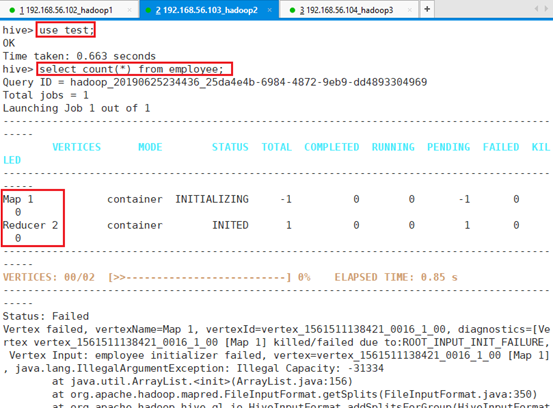
查询表数据:select count(*) from employee;
打印错误信息,由于MapReduce的Map和Reduce内存设置没有设置
设置内存:
set mapreduce.map.memory.mb=1024;
set mapreduce.reduce.memory.mb=1024;select count(*) from employee;共耗时:11.72秒。
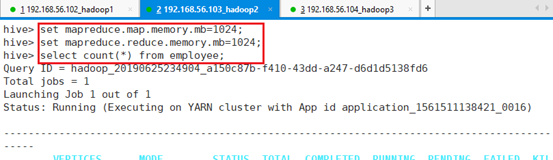
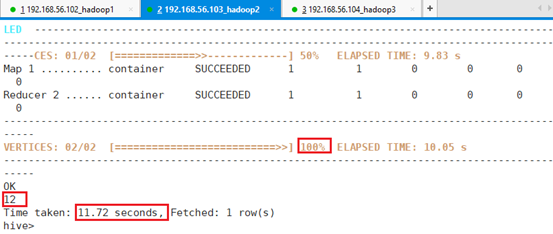
时间花了这么长是因为进入了大数据集环境,虽然测试的数据量小,花的时间大部分花在整个调度上。
7.5.3 mr引擎
查询执行引擎:set hive.execution.engine;
显示为:hive.execution.engine=tez

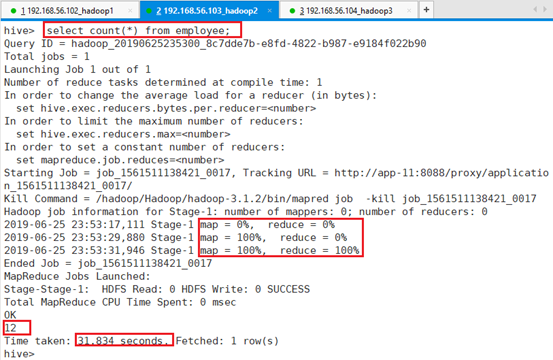
将执行引擎修改为mr:set hive.execution.engine=mr;

再执行操作: select count(*) from employee;
共耗时:31.834秒。
7.6 Hive锁
在表上加排他锁,防止其他用户对表执行相关操作,Hive提供该功能。
7.6.1 加锁
ssh连接到app-12,切换到hadoop用户
切换到命令行环境:hive –service cli
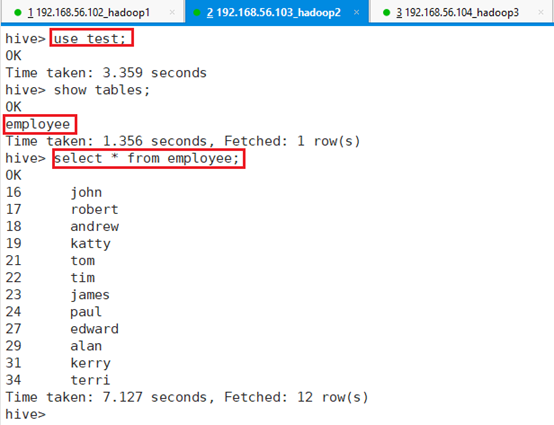
进入到test数据库:use test;
查看表employee信息:select * from employee;
给表加上排它锁:lock table employee exclusive;

进入zookeeper客户端:zkCli.sh

查看zookeeper变化
多了个hive_zookeeper_namespace节点。

进入节点:ls /hive_zookeeper_namespace

进入库节点test:ls /hive_zookeeper_namespace/test

进入表:ls /hive_zookeeper_namespace/test/employee
可以看到,生成了一个排它锁

7.6.2 解锁
再在hive下解锁:unlock table employee;

再查看zookeeper目录下文件:
发现锁文件已经不存在了。

通过进一步查看,发现数据库还是存在,只是表上的锁不存在了。

7.6.3 实验
接下来,继续将表employee锁上:lock table employee exclusive;

用另一个ssh登录app-12,切换到hadoop目录。
进入hive客户端:hive –service cli
进入数据库test:use test;
查询表:select * from employee;
光标一直停住不动,显示不了结果,因为被锁住了。
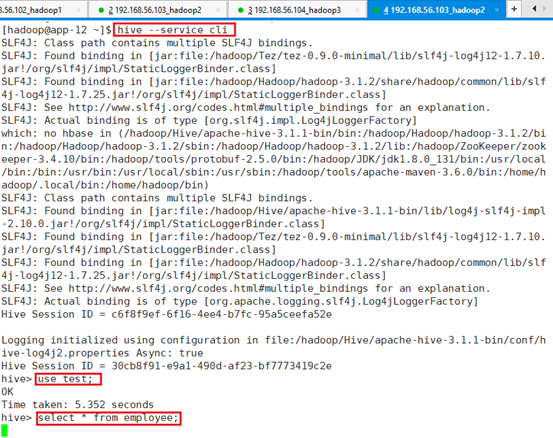
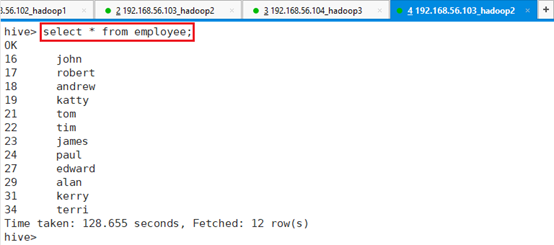
接下来在另一个ssh终端unlock表:unlock table employee;

通过查看发现查询出结果了,时间长是因为之前被锁住了。
注意:如果一直出不来结果,可以通过ctrl+c中断,重新查询:
hive -e "use test; select * from employee"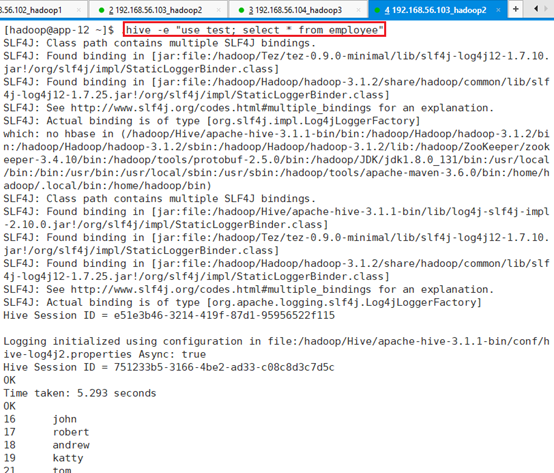
接下来模拟一次异常操作,比如lock之后,并没有unlock,直接quit了。

此时lock依旧会存在,不会消失,导致整个动作卡死,锁并没有释放。
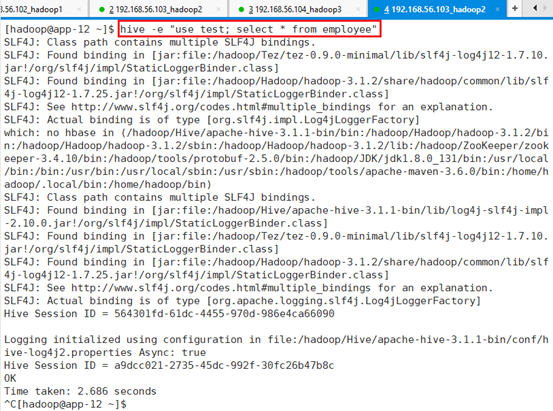
通过ctrl+c退出,
登录zookeeper客户端:zkCli.sh
删除锁:
delete /hive_zookeeper_namespace/test/employee/LOCK-EXCLUSIVE-0000000000
再做表查询操作:hive -e “use test; select * from employee”
可以正常操作了。
7.7 Hive调优
通过简单的举例子说明:执行计划和分区两方面说明。
7.7.1 执行计划
ssh连接到app-12,切换到hadoop用户。
切换到hive命令行:hive –service cli
查看引擎:set hive.execution.engine;

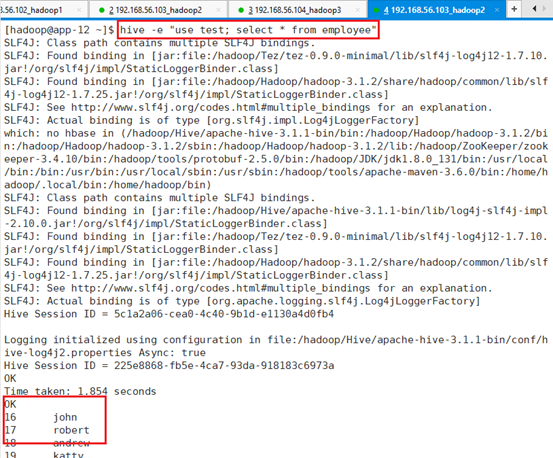
利用explain关键字解释执行过程,打印执行计划:
explain select count(*) from test.employee;通过结果看处将Map和Reduce进行连接。
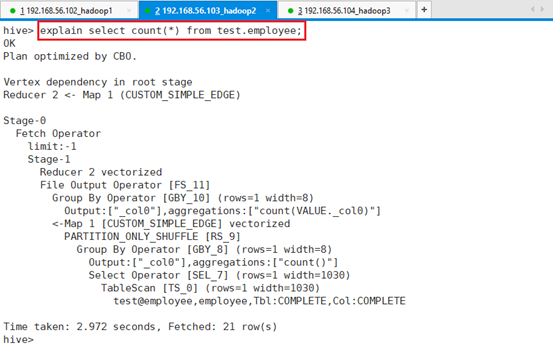
进一步查看更详细的信息
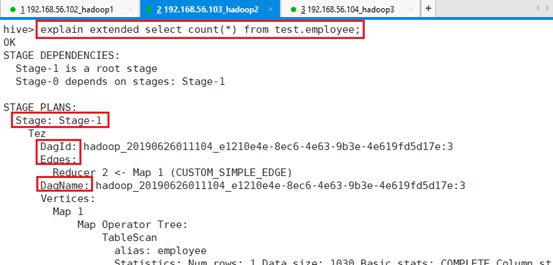
explain extended select count(*) from test.employee;分为两个阶段,Hive的所有执行时分阶段执行的。
第一个阶段:DagId和Edges以及顶点Map、Reduce信息,已经相关顶点的描述。
第二个阶段:由于没有做Limit,所以该阶段没有做任何工作。

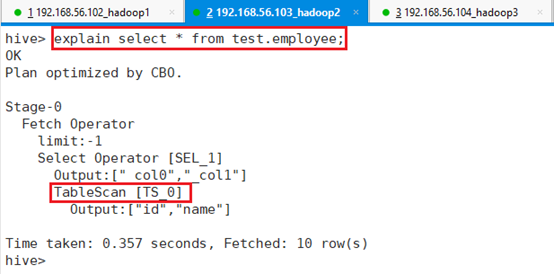
检查select *是否会做MapReduce
explain select * from test.employee;没有MapReduce信息,其中最关键的就是TableScan扫描输入文件。
详细过程也一样:
explain extended select * from test.employee;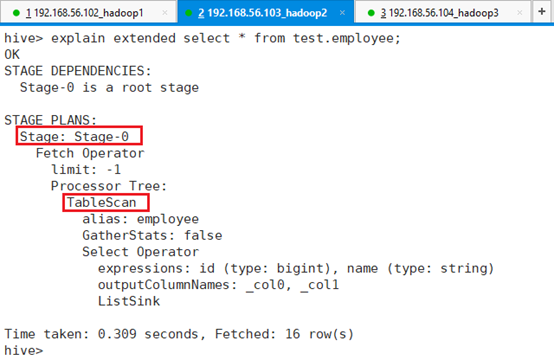
7.7.1.1 并行
由于Hive会将一个查询转换为多个阶段,一个阶段可以是Map、也可以是Reduce、合并阶段、limit阶段或者需要的其他阶段,默认情况下,Hive会一次执行一个阶段。
在Hive里面由这个参数set hive.exec.parallel定义是否进行并行执行,但是有一些特定的Job可能包含众多阶段,这些阶段不一定是完全依赖的,对于完全依赖的,类似MR,Map输出了Reduce才能工作,这种情况下,可以并行部分,但是不能完全并行。很多情况下,两个阶段之间耦合度比较大,并行是没法执行的。

如果阶段键关联度不大,则可以将并行度设置为打开:
set hive.exec.parallel=true;则可以将相互不关联的阶段并行执行。

7.7.2 分区表
此外,还可以通过创建分区表的形式进行优化,数据分区有多种形式,使用分区来水平分散压力,可以将查询限制在某一个分区上,则查询的数据总体减小,比如只关注最近几天的数据,则可以将最近一个月的做一次分区,这样的话只查询一个月的。