完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
十五、Spark MLlib二元决策树
决策树是一种常见的机器学习算法,类似于我们平时利用选择做决策的过程。
15.1 介绍
决策树又称为判定树,其中的每个内部节点代表对某一属性的一次测试,每条边代表一个测试结果,叶节点代表某个类或类的分布。
决策树的决策过程需要从决策树的根节点开始,待测数据与决策树中的特征节点进行比较,并按照比较结果选择选择下一比较分支,直到叶子节点作为最终的决策结果。
根节点:包含数据集中的所有数据的集合。
内部节点:每个内部节点为一个判断条件,并且包含数据集中满足从根节点到该节点所有条件的数据的集合。根据内部结点的判断条件测试结果,内部节点对应的数据的集合别分到两个或多个子节点中。
叶节点:叶节点为最终的类别,被包含在该叶节点的数据属于该类别。
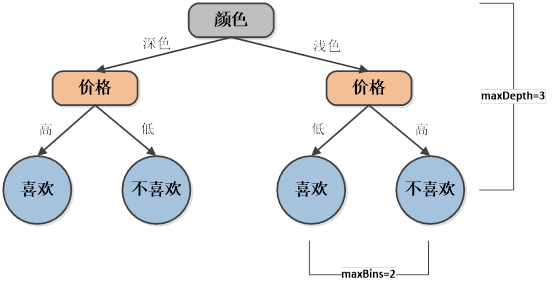
如图所示,在建立决策树时不可能无限制的分裂,需要限制最大分支数和深度,如下:
- maxBins:决策树中每一个节点的最大分支数,避免横向无限制。
- maxDepth:决策树的最大深度,避免纵向无限制。
- Impurity:决策树在分裂节点时的方法,包场Gini和Entropy两种。
15.2 节点划分
15.2.1 基尼指数(Gini)
Gini指数最早应用在经济学中,用来衡量收入分配公平程度的指标。
决策树算法中对每种特征字段分割点计算估值,选择分裂后最小的gini方式,比如假设有K个类,样本点属于第k类的概率为,则概率分布的gini指数定义为:
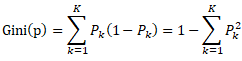
这是,如果样本集合D根据某个特征A被分割为D1和D2两部分,则在特征A的条件下,集合D的gini指数定义为:

Gini实数Gini(D,A)表示特征A不同分组的数据集D的不确定性,gini指数越大,样本集合的不确定性也就越大。
基于此,可以通过gini指数来确定某个特征的最优切分点(也即只需要确保切分后某点的gini指数值最小),这就是决策树算法中类别变量切分的关键所在。
15.2.2 熵(Entropy)
熵代表一个系统的杂乱程度,熵越大,系统越杂乱。
对一个数据集进行分类,就是使得该数据集熵减小的过程,即将无序的数据变得更加有序。对应的数学公式如下:
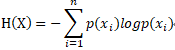
如果看不明白什么是熵,不要着急——它们自诞生的那一天起,就注定会令世人十分费解。克劳德香农写信息论之后,约翰冯诺依曼建议使用“熵”这个术语,因为大家都不知道它是什么意思。
此处指需要知道在决策树选择分裂点时,是基于最小熵方式。
15.3 案例
利用kaggle提供的真是数据测试网站是用户一直感兴趣的网站还是暂时感兴趣的网站。
15.3.1 介绍
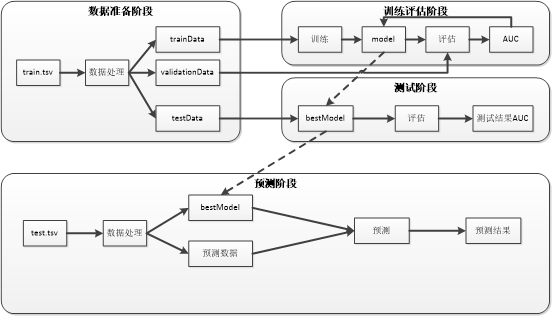
处理过程如图:
- 将测试数据train.tsv经过数据处理后,按8:1:1比例分成训练数据、校验数据和测试数据;
- 利用训练数据训练模型;
- 利用校验数据对模型进行评估,计算AUC;
- 试验多个参数,循环2,3步骤,找到最大AUC情况下的参数,设置为bestModel;
- 将测试数据test.tsv经过数据处理后,利用bestModel对数据进行预测。
15.3.2 数据源
15.3.2.1 下载
从网站https://www.kaggle.com/c/stumbleupon/data下载:test.tsv和train.tsv数据。

15.3.2.2 分析
打开train.tsv文件,第一行为列名,用\t分割开:

test.tsv文件和train.tsv相比,没有label字段,这个文件适用于预测的,最后计算label值。
15.3.3 上传数据
用ssh登录app-11节点,切换到hadoop用户并启动集群。
将train.tsv和test.tsv上传到app-11节点目录:/tmp/stumble
创建目录/tmp/stumble:mkdir -p /tmp/stumble

15.3.3.1 HDFS
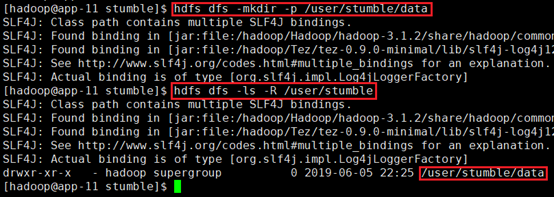
在HDFS上创建目录:hdfs dfs -mkdir -p /user/stumble/data
确认成功:hdfs dfs -ls -R /user/stumble
上传数据到/user/stumble/data:
hadoop dfs -copyFromLocal -f /tmp/stumble/* /user/stumble/data/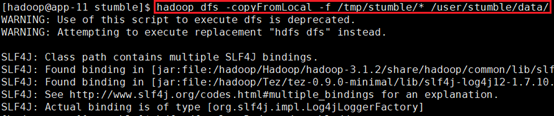
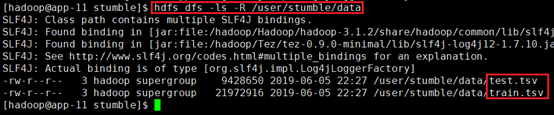
确认:hdfs dfs -ls -R /user/stumble/data
15.3.4 测试-jupyter
15.3.4.1 新建项目
登录web页面:http://app-11:8888/,新建python3项目。

重命名为stumble

15.3.4.2 引入库
引入后续测试需要用到的库,包括LabeledPoint、DecisionTree、BinaryClassificationMetrics等。
import findspark
findspark.init()
from pyspark import SparkContext
from pyspark import SparkConf
from os.path import expanduser, join, abspath
from pyspark.sql import SparkSession
from pyspark.sql import Row
from pyspark.sql.types import *
import matplotlib.pyplot as plt
from pyspark.sql.types import StructField
import numpy as np
import pandas as pd
import matplotlib.dates as mdate
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree
from pyspark.mllib.evaluation import BinaryClassificationMetrics
from time import time
15.3.4.3 创建SparkContext
以master节点创建SparkContext:
sc = SparkContext("spark://app-11:7077","stumble")15.3.4.4 载入数据
设置路径:
global Path
Path="hdfs://dmcluster/user/stumble/"读取数据,并统计数量:
trainDataWithHeader=sc.textFile(Path+"data/train.tsv")
trainDataWithHeader.count()通过统计可以看出共有7396行,包括列名:

查看前两行:
trainDataWithHeader.take(2)其中第一行为列名,第二行为数据值

15.3.4.5 数据治理
去除数据第一行:
header=trainDataWithHeader.first()
trainData=trainDataWithHeader.filter(lambda x:x!=header)
trainData.take(2)从打印看出已经没有第一行的列名了。

去除数据中的双引号,便于后续处理
trainData=trainData.map(lambda x:x.replace("\"",""))
trainData.take(2)
将数据按行用\t进行分割开,并从第三个字段开始显示第一行的数据
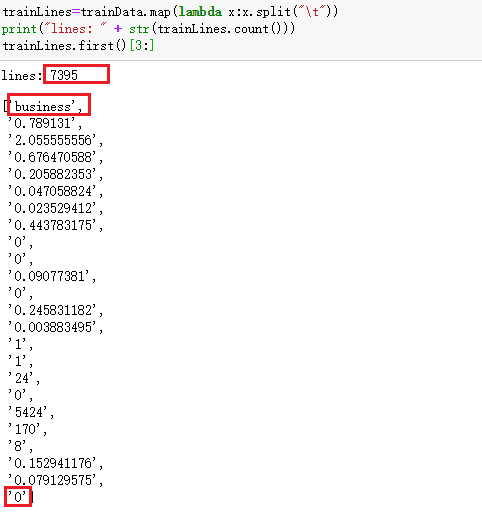
trainLines=trainData.map(lambda x:x.split("\t"))
print("lines: " + str(trainLines.count()))
trainLines.first()[3:]去除掉列名后,数量较之前少一行为7395行。
每行的第四列为网页类型,最后一个字段为标记是否长期感兴趣页。
15.3.4.6 类型编号
统计网页类型,并编号,其中网页类型字段为[3]
categoryMap=trainLines.map(lambda fields:fields[3]).distinct().zipWithIndex().collectAsMap()
print(categoryMap)
print("len = " + str(len(categoryMap)))
print("type = " + str(type(categoryMap)))可以看出有14中网页类型

15.3.4.7 创建LabelPoint
定义函数获取label值,即最后一个字段
def extract_label(field):
label=field[-1]
return float(label)定义转换为float类型的函数
def convert_float(x):
return (0 if x=="?" else float(x))计算特征,为LabelPoint做准备,因为决策树需要LabelPoint格式数据
def extract_features(line, categoryMap, featureEnd):
categoryIdx=categoryMap[line[3]]
categoryFeatures=np.zeros(len(categoryMap))
categoryFeatures[categoryIdx]=1
numericalFeatures=[convert_float(line) for line in line[4:featureEnd]]
return np.concatenate((categoryFeatures, numericalFeatures))计算LablePoint:
trainLPRDD=trainLines.map(lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoryMap,len(r)-1)))
trainLPRDD.take(1)LablePoint由label和features组成。
其中features字段,前14个字段,由于第一行类型为bussiness,在之前的网页类型编号中为3,所以对三个字段为1,其余13个字段为0。后面跟着的字段为原数据转换为float后的字段。

15.3.4.8 数据分类
将数据按9:1随机分成两大类,分别用户训练和验证,本次由于有专门的测试数据,所以不分测试数据。
(trainData, validationData)=trainLPRDD.randomSplit([9,1])
print("train: " + str(trainData.count()))
print("validate: " + str(validationData.count()))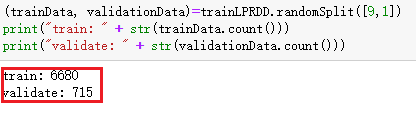
将数据暂存内存,便于后续快速处理。

15.3.4.9 训练模型
利用随机分出的训练数据作为输入数据,分类数为2,所有特征为连续型变量,采用熵的方式计算,最大深度为5,每个节点最大分支数为5。
model=DecisionTree.trainClassifier(trainData, numClasses=2,categoricalFeaturesInfo={},impurity="entropy",maxDepth=5,maxBins=5)
15.3.4.10 载入测试文件
读取数据,并统计数量:
testDataWithHeader=sc.textFile(Path+"data/test.tsv")
testDataWithHeader.count()通过统计可以看出共有3172行,包括列名:

查看前两行:
testDataWithHeader.take(2)其中第一行为列名,第二行为数据值

15.3.4.11 测试数据治理
去除数据第一行:
header=trainDataWithHeader.first()
trainData=trainDataWithHeader.filter(lambda x:x!=header)
trainData.take(2)从打印看出已经没有第一行的列名了。
去除数据中的双引号,便于后续处理
testData=testData.map(lambda x:x.replace("\"",""))
testData.take(2)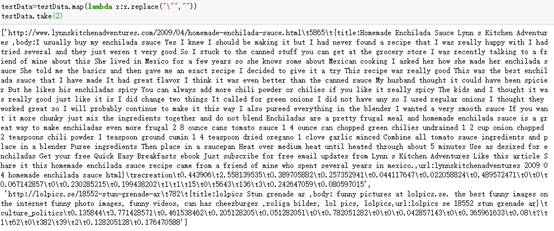
将数据按行用\t进行分割开,并从第三个字段开始显示第一行的数据
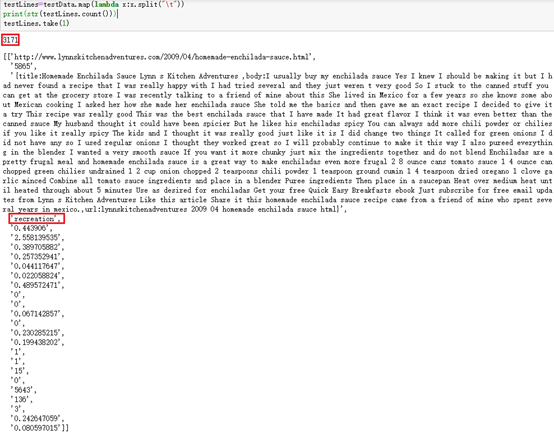
testLines=testData.map(lambda x:x.split("\t"))
print(str(testLines.count()))
testLines.take(1)去除掉列名后,数量较之前少一行为3171行。
每行的第四列为网页类型,测试数据没有label字段。
15.3.4.12 提取features
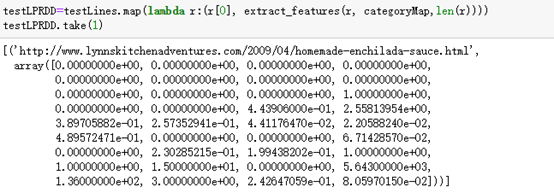
testLPRDD=testLines.map(lambda r:(r[0], extract_features(r, categoriesMap,len(r))))
testLPRDD.take(1)和训练数据的区别在于此处不是LabelPoint,而且测试数据没有label字段,所以此次len(r),不需要再减1。
15.3.4.13 模型预测
创建label字典:
LabelDict={
0:"ephemeral",
1:"evergreen"
}利用训练数据建立的模型预测测试数据的前五个label值:
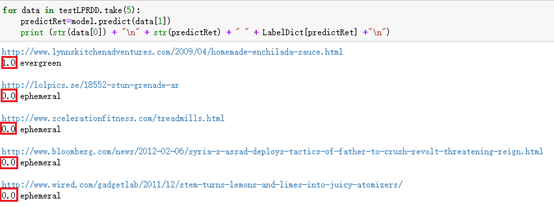
for data in testLPRDD.take(5):
predictRet=model.predict(data[1])
print (str(data[0]) + "\n" + str(predictRet) + " " + LabelDict[predictRet] +"\n")传入特征值即可进行预测
15.3.4.14 计算AUC
在统计和机器学习中,常常用AUC来评估二分类模型的性能。AUC的全称是(Area Under the Curve),即曲线下的面积。
本例中,根据预测的结果和实际的标签可以把样本分为4类:
| Label值 | 1 | 0 |
| 预测为1 | TP(真正例) | FP(假正例) |
| 预测为0 | FN(假负例) | TN(真负例) |
在所有为1的样本中被预测为1的比例为:TPR=TP/(TP+FN),TPR越大越好
在所有为0的样本中被预测为1的比例为:FPR=FP/(FP+TN),FPR越小越好
在二分类(0,1)的模型中,需要一个阈值,超过这个阈值则归类为1,低于这个阈值就归类为0。当阈值从0开始慢慢移动到1的过程,就会形成很多对(FPR, TPR)的值,将它们画在坐标系上,将FPR定义为X轴,TPR定义为Y轴,就是所谓的ROC曲线了,ROC曲线下方的面积就是AUC值了。
- AUC=1这说明完美预测,但是实际不存在
- 0.5<AUC<1预测成功率比随机预测好,具有价值
- AUC=0.5和随机预测一样,相当于乱猜
- AUC<0.5还不如乱猜,没有价值。
定义函数
//利用训练数据中分出来的校验数据中的特征值进行预测
//将预测的数据和实际数据组合,如[(0.0, 1.0), (0.0, 1.0), (1.0, 1.0), (0.0, 1.0), (0.0, 1.0)],第一个为预测数据,第二个为实际数据
//利用BinaryClassificationMetrics建立二元分类
//调用areaUnderROC方法计算AUC
def calAUC(model, evaluateData):
predictLabel=model.predict(evaluateData.map(lambda p:p.features))
predictLabelAndActualLabel=predictLabel.zip(evaluateData.map(lambda p:p.label))
metrics=BinaryClassificationMetrics(predictLabelAndActualLabel)
AUC=metrics.areaUnderROC
return(AUC)15.3.4.15 找出最佳AUC
传入不同参数进行计算,先根据训练数据训练模型,然后利用校验数据计算模型的AUC。
def calModelAndAUC(trainData, validationData, impurityParm, maxDepthParm, maxBinsParm):
startTime=time()
model=DecisionTree.trainClassifier(trainData,
numClasses=2,categoricalFeaturesInfo={},
impurity=impurityParm,
maxDepth=maxDepthParm,
maxBins=maxBinsParm)
AUC=calAUC(model, validationData)
duration=time()-startTime
print("impurity="+str(impurityParm) +
" maxDepth="+str(maxDepthParm) +
" maxBins="+str(maxBinsParm) +
" time="+str(duration)+
" AUC="+str(AUC))
return(AUC,duration,impurityParm,maxDepthParm,maxBinsParm,model)根据不同参数计算AUC,并对AUC进行排序,找出AUC值最大的,返回MODEL
def calBestModel(trainData,validationData,impurityList,maxDepthList,maxBinsList):
metrics=[calModelAndAUC(trainData,validationData,impurity,maxDepth,maxBins)
for impurity in impurityList
for maxDepth in maxDepthList
for maxBins in maxBinsList]
sortMetrics=sorted(metrics,key=lambda k:k[0], reverse=True)
bestAUC=sortMetrics[0]
print("impurity="+str(bestAUC[2])+
",maxDepth="+str(bestAUC[3])+
",maxBins="+str(bestAUC[4])+
",AUC="+str(bestAUC[0]))
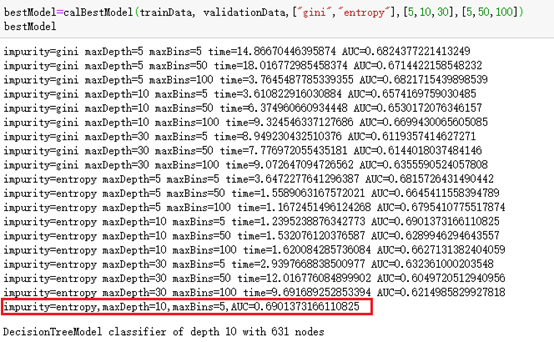
return bestAUC[5]传入参数进行计算:
bestModel=calBestModel(trainData, validationData,["gini","entropy"],[5,10,20,30],[5,10,50,100])结果发现最好的是AUC= AUC=0.6901373166110825
15.3.4.16 图形显示Matplotlib
不同节点分裂算法下:
impurityList=["gini","entropy"]
maxDepthList=[5]
maxBinsList=[5]
metrics=[calModelAndAUC(trainData,validationData,impurity,maxDepth,maxBins)
for impurity in impurityList
for maxDepth in maxDepthList
for maxBins in maxBinsList]用pandas显示:
df=pd.DataFrame(metrics,index=impurityList,columns=
['AUC','duration','impurity','maxDepth','maxBins','model'])
df
定义画图函数:
// evalparm,此次评估的参数,
def showchart(df,evalparm,barData,lineData,yMin,yMax):
ax=df[barData].plot(kind='bar',title=evalparm,figsize=(10,6),legend=True,fontsize=12)//方形,figsize为图形的宽和高
ax.set_xlabel(evalparm,fontsize=12)//X轴
ax.set_ylim([yMin,yMax])// Y轴打印区域
ax.set_ylabel(barData,fontsize=12)// Y轴
ax2=ax.twinx()//折线
//样式'-',数值点'o',宽度为2,颜色
ax2.plot(df[lineData].values, linestyle='-',marker='o',linewidth=2.0,color='r')
plt.show()建模,计算AUC值,并画出来:
def draw(trainData,validationData,evalparm,impurityList,maxDepthList,maxBinsList):
metrics=[calModelAndAUC(trainData,validationData,impurity,maxDepth,maxBins)
for impurity in impurityList
for maxDepth in maxDepthList
for maxBins in maxBinsList]
if evalparm=="impurity":
indexList=imipurityList[:]
elif evalparm=="maxDepth":
indexList=maxDepthList[:]
elif evalparm=="maxBins":
indexList=maxBinsList[:]
df=pd.DataFrame(metrics,index=indexList,columns=['AUC','duration','impurity','maxDepth','maxBins','model'])
showchart(df,evalparm,"AUC","duration",0.5,0.7)测试:
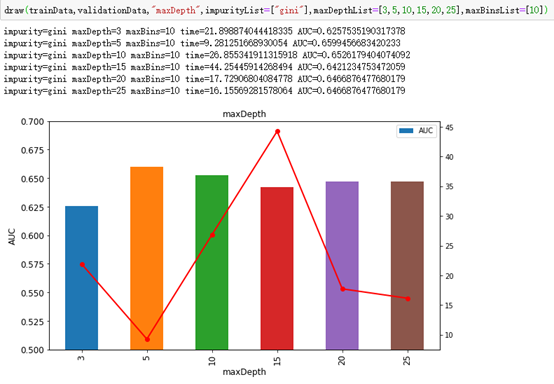
draw(trainData,validationData,"maxDepth",impurityList=["gini"],maxDepthList=[3,5,10,15,20,25],maxBinsList=[10])其中折线表示时间,方形表示AUC。
15.3.4.17 过度训练
过度训练指机器学习所学到的模型过度贴近训练数据,从而导致误差变大:
使用校验数据得出的AUC和测试数据得出的ACU是否接近,如果校验数据得出的AUC很大,而测试数据得出的AUC很低,则很可能过度训练。
由于test文件中没有label字段,所以测试数据需要从训练数据中取,在分数据是,将训练数据按8:1:1分成三份,8分训练数据,1分校验数据,1分测试数据
(trainData, validationData, testData)=trainLPRDD.randomSplit([8,1,1])
AUC=calAUC(model, testData)15.3.5 测试-submit
15.3.5.1 代码文件
文件代码:DecisionTreeTrain.py
# -*-coding: utf-8 -*-
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree
from pyspark.mllib.evaluation import BinaryClassificationMetrics
from time import time
import numpy as np
import sys
def SetPath(sc):
"""定义全局变量Path,配置文件读取"""
global Path
Path="hdfs://dmcluster/user/stumble/"
def CreateSparkContext():
"""创建SparkContext"""
sparkConf = SparkConf() \
.setAppName("DecisionTree") \
.set("spark.ui.showConsoleProgress","false")
sc = SparkContext(conf=sparkConf)
SetPath(sc)
print("master="+sc.master)
return sc
def extract_label(field):
"""提取LABEL字段,并转化为FLOAT"""
label=field[-1]
return float(label)
def convert_float(x):
"""转化为FLOAT,剔除?"""
return (0 if x=="?" else float(x))
def extract_features(line, categoryMap, featureEnd):
"""提取特征值,具体参考前面"""
categoryIdx=categoryMap[line[3]]
categoryFeatures=np.zeros(len(categoryMap))
categoryFeatures[categoryIdx]=1
numericalFeatures=[convert_float(line) for line in line[4:featureEnd]]
return np.concatenate((categoryFeatures, numericalFeatures))
def PrepareData(sc):
"""导入数据,治理数据,将数据分开处理"""
trainDataWithHeader = sc.textFile(Path+"data/train.tsv")
header=trainDataWithHeader.first()
trainData=trainDataWithHeader.filter(lambda x:x!=header)
trainData=trainData.map(lambda x:x.replace("\"",""))
trainLines=trainData.map(lambda x:x.split("\t"))
categoryMap=trainLines.map(lambda fields:fields[3]).distinct().zipWithIndex().collectAsMap()
trainLPRDD=trainLines.map(lambda r:
LabeledPoint(
extract_label(r),
extract_features(r,categoryMap,len(r)-1)))
(trainData, validationData, testData)=trainLPRDD.randomSplit([8,1,1])
return (trainData, validationData, testData, categoryMap)
def calAUC(model, evaluateData):
predictLabel=model.predict(evaluateData.map(lambda p:p.features))
predictLabelAndActualLabel=predictLabel.zip(evaluateData.map(lambda p:p.label))
metrics=BinaryClassificationMetrics(predictLabelAndActualLabel)
AUC=metrics.areaUnderROC
return(AUC)
def calModelAndAUC(trainData, validationData, impurityParm, maxDepthParm, maxBinsParm):
startTime=time()
model=DecisionTree.trainClassifier(trainData,
numClasses=2,categoricalFeaturesInfo={},
impurity=impurityParm,
maxDepth=maxDepthParm,
maxBins=maxBinsParm)
AUC=calAUC(model, validationData)
duration=time()-startTime
print("impurity="+str(impurityParm) +
" maxDepth="+str(maxDepthParm) +
" maxBins="+str(maxBinsParm) +
" time="+str(duration)+
" AUC="+str(AUC))
return(AUC,duration,impurityParm,maxDepthParm,maxBinsParm,model)
def calBestModel(trainData,validationData,impurityList,maxDepthList,maxBinsList):
metrics=[calModelAndAUC(trainData,validationData,impurity,maxDepth,maxBins)
for impurity in impurityList
for maxDepth in maxDepthList
for maxBins in maxBinsList]
sortMetrics=sorted(metrics,key=lambda k:k[0], reverse=True)
bestAUC=sortMetrics[0]
print("impurity="+str(bestAUC[2])+
",maxDepth="+str(bestAUC[3])+
",maxBins="+str(bestAUC[4])+
",AUC="+str(bestAUC[0]))
return bestAUC[5]
def PredictData(sc, bestModel, categoryMap):
"""导入数据,治理数据,将数据分开处理"""
testDataWithHeader = sc.textFile(Path+"data/test.tsv")
header=testDataWithHeader.first()
testData=testDataWithHeader.filter(lambda x:x!=header)
testData=testData.map(lambda x:x.replace("\"",""))
testLines=testData.map(lambda x:x.split("\t"))
testLPRDD=testLines.map(lambda r:(r[0], extract_features(r, categoryMap,len(r))))
LabelDict={
0:"ephemeral",
1:"evergreen"
}
for data in testLPRDD.take(5):
predictRet=bestModel.predict(data[1])
print (str(data[0]) + "\n" + str(predictRet) + " " + LabelDict[predictRet] +"\n")
if __name__ == "__main__":
sc=CreateSparkContext()
print("==========数据准备==========")
(trainData, validationData, testData, categoryMap)= PrepareData(sc)
trainData.persist();
validationData.persist();
testData.persist();
print("==========计算最佳模型==========")
bestModel=calBestModel(trainData, validationData,["gini","entropy"],[5,10,20,30],[5,10,50,100])
print("==========测试阶段==========")
auc = calAUC(bestModel, testData);
print("testData auc:" + str(auc));
print("==========预测阶段==========")
PredictData(sc, bestModel, categoryMap);主要步骤,具体参考jupyter
- 创建SparkContext
- 载入数据train.tsv,按8:1:1划分为训练数据、验证数据和测试数据。从训练数据训练模型,从验证数据计算AUC,找到最佳模型,再用测试数据计算最佳模型的AUC。
- 载入测试数据test.tsv,预测测试数据每条URL的属性。
15.3.5.2 上传
用ssh连接到app-11节点,切换到hadoop用户,并启动集群。
新建目录/tmp/stumble:mkdir /tmp/stumble
将代码文件上传到目录/tmp/stumble

15.3.5.3 运行
切换到目录/hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2:
cd /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2
运行代码文件:
./bin/spark-submit /tmp/stumble/DecisionTreeTrain.py --master yarn --deploy-mode cluster --driver-memory 2g --executor-memory 1g --executor-cores 1 --queue default15.3.5.4 结果
载入数据

训练计算多个模型,利用校验数据找到最佳AUC。
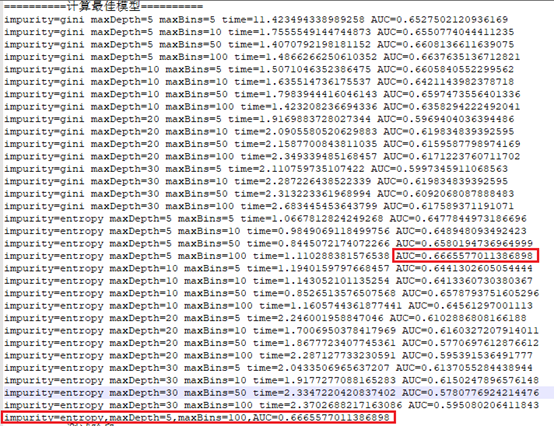
根据最佳模型,计算测试数据的AUC

载入测试文件,利用最佳模型进行预测
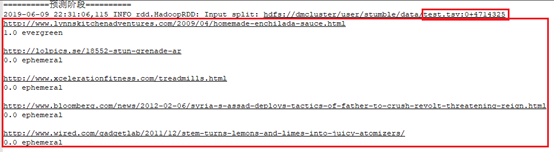
15.3.5.5 过度训练
根据最佳模型,使用校验数据计算的AUC和使用测试数据计算的AUC如下:
| AUC | |
| 校验数据validationData | 0.6665577011386898 |
| 测试数据testData | 0.663091202582728 |
从表中可以看出使用校验数据得出的AUC和测试数据得出的ACU相近,说明并没有出现过度训练现象。。