完整目录、平台简介、安装环境及版本:参考《Hive从入门到精通-概览》
三、基础操作
由于Hive和MySQL都是安装在app-12节点,后续所有相关Hive和MySQL操作都是在app-12节点操作。
3.1 Hive进入方式
在app-11启动集群后,用ssh连接到app-12节点,切换到hadoop用户后,可以三种方式进入CLI命令模式。
3.1.1 ./hive
在bin目录下执行:
命令:cd /hadoop/Hive/apache-hive-3.1.1-bin/bin
命令:. /hive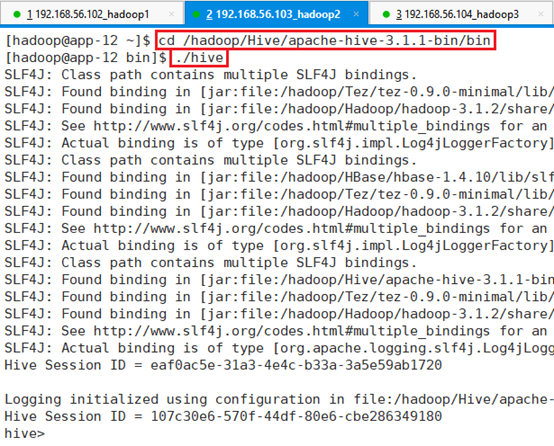
退出命令行:
使用命令:quit;
3.1.2 hive
由于设置了环境变量,无需在bin目录下,直接用命令:hive
退出命令行使用命令:quit;

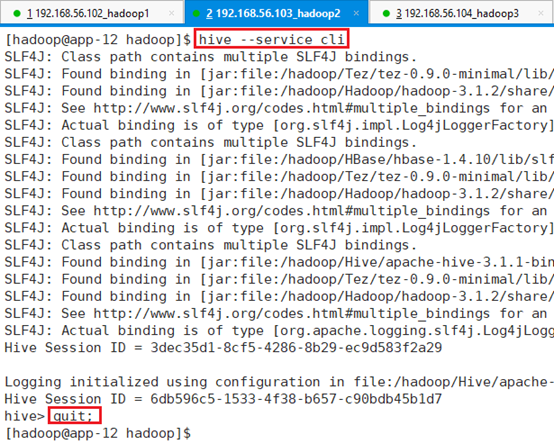
3.1.3 hive –service cli
无需在bin目录下,直接用命令:hive –service cli
退出命令行使用命令:quit;
3.2 常用命令
3.2.1 清屏
命令:CTRL+L或者!clear;
3.2.2 Hive中一次使用命令
功能:不进入CLI模式,直接在Linux环境下执行Hive命令。
格式:hive -e 'hive命令';
命令:hive -e 'show databases';
3.2.3 数据库操作
3.2.3.1 创建数据库
创建数据库hivedb:
命令:create database if not exists hivedb
3.2.3.2 查看数据库
查看数据库:
命令:show databases;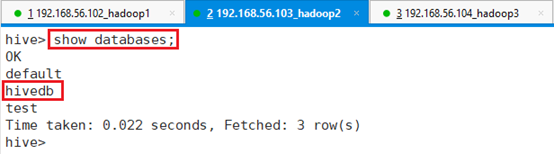
模糊查询,比如以h开头,以其他字符结尾的数据:
命令:show databases like 'h.*';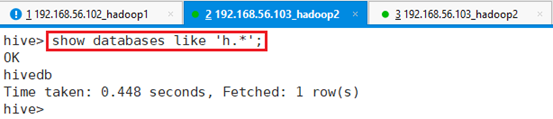
3.2.3.3 修改数据库
功能:只可以修改数据库的DBPROPERTIES属性,数据库的其他元数据信息不可以更改,包括数据库名和数据库所在的目录位置等属性。
格式:alter dtabase 数据库名 set dbproperties(key=value)3.2.3.4 删除数据库
格式:drop database 数据库名:
命令:drop database hivedb;注意,Hive不允许用户删除一个包含有表的数据库,如下:
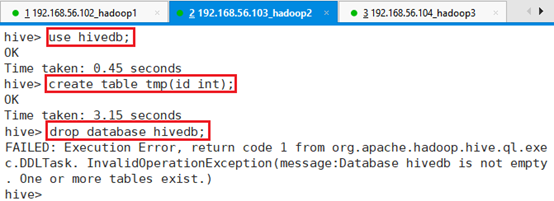
强行删除数据库,需要在最后加上关键字CASCADE:
命令:drop database hivedb CASCADE;执行命令后,再次查询数据库,发现该数据库已经被删除了。
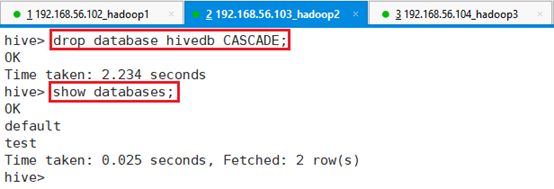
便于后续试验,重新创建该数据库:create database if not exists hivedb;
3.2.4 表操作
3.2.4.1 查看表
进入数据库hivedb:
命令:use hivedb;
查看该库下是表情况:
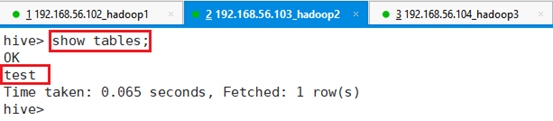
命令:show tables;
3.2.4.2 创建表
在hivedb数据库下创建表test,包含id,学号,姓名,年龄字段,字段间用行用`,`符号隔开,因为后续这个表需要导入csv文件数据。命令:
hive> create table if not exists test(
> id int,
> no string,
> name string,
> age int)
> row format delimited fields terminated by ',';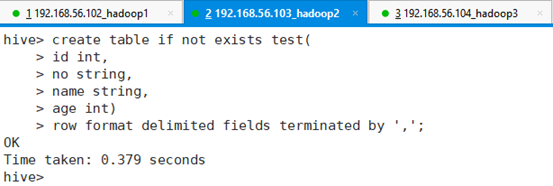
再查看表是否存在:show tables;
3.2.4.2.1 查看表结构
格式:desc 表名;
命令:desc test;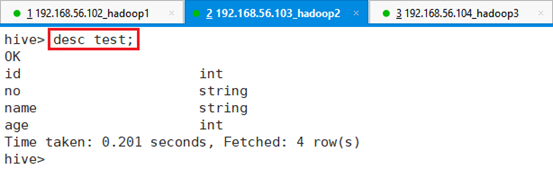
3.2.4.2.2 导入数据
在app-12节点的/tmp目录下创建hive目录
命令:mkdir /tmp/hive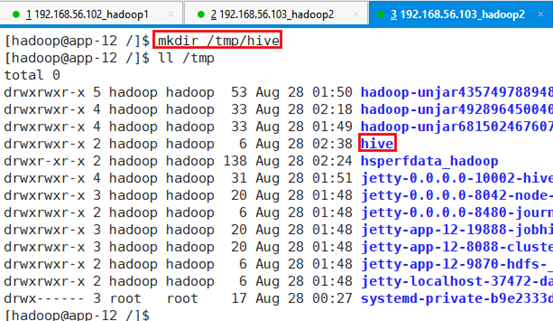
在/tmp/hive目录下新建文件test.csv,并输入一下内容。也可以通过FTP方式从外面导入。
命令:vi test.csv| /tmp/hive/test.csv |
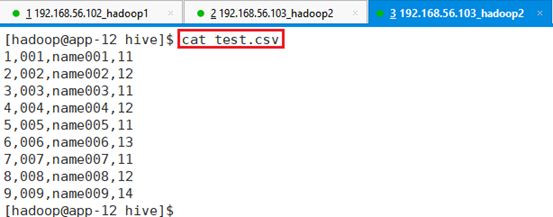
| 1,001,name001,11 2,002,name002,12 3,003,name003,11 4,004,name004,12 5,005,name005,11 6,006,name006,13 7,007,name007,11 8,008,name008,12 9,009,name009,14 |
查看创建结果:cat test.csv
进入Hive命令行,并进入数据库hivedb,导入数据:
命令:load data local inpath '/tmp/hive/test.csv' overwrite into table test;该命令后续会详细讲,此处只需要知道有这个功能。

查看数据导入情况:
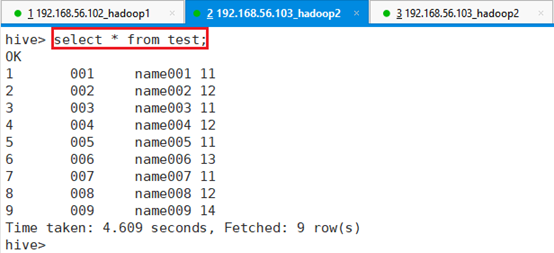
命令:select * from test;可以看出,已经成功将源数据test.csv导入到了表test中。
3.2.4.3 删除表
格式:drop table 表名;
命令:drop table test;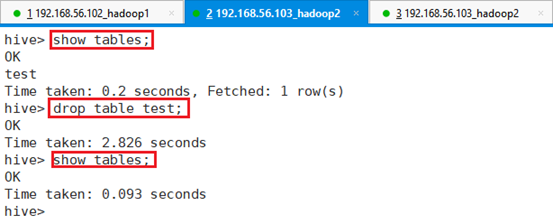
为了便于后续试验,按之前步骤重新创建表test。
3.2.5 HQL语句
3.2.5.1 HQL语句
在SELECT查询不涉及计算的话,一会触及MapReduce操作。
比如简单的表数据查询
命令:select * from test;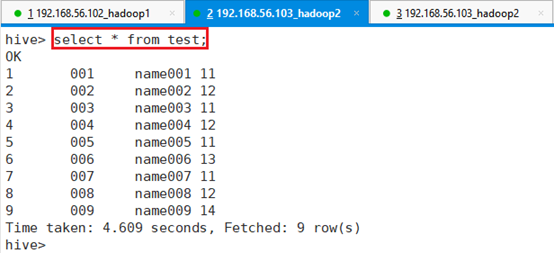
涉及到计算的,比如统计表条目数,则会转换为MapReduce的查询语句
命令:select count(*) from test;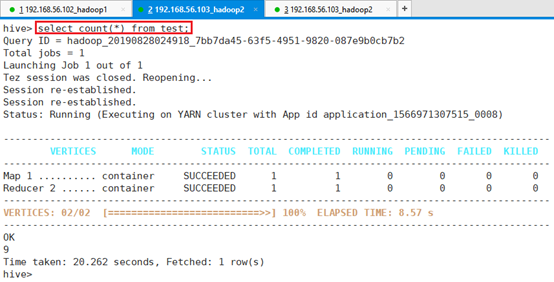
执行过程可以看出来,转换成了相应的MapReduce操作。
3.2.5.2 静默模式
静默模式,即不输出中间调试信息,直接输出结果。
退出命令行模式,重新进入命令行模式:
命令:hive -S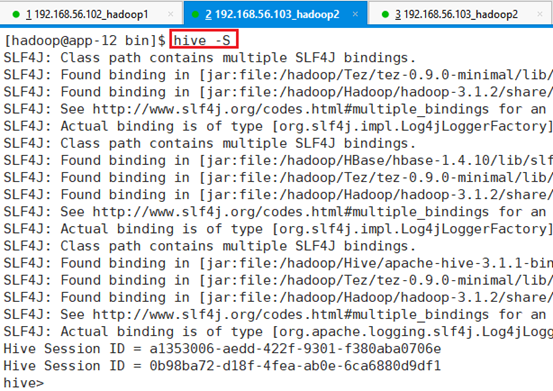
再次执行命令:select count(*) from test;

在这种情况下,就没有输出MapReduce信息,以及执行状态,执行时间等调试信息。不建议用该模式,看不到执行结果和状态,不利于学习。
3.2.5.3 执行脚本
- 在app-12节点/tmp/hive目录下创建脚本test.sql
命令:vi test.sql| /tmp/hive/test.sql |
| use hivedb; select * from test; |
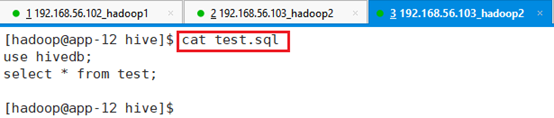
创建结果如下:cat test.sql
执行脚本test.sql:
命令:source /tmp/hive/test.sql;
可以看出顺序执行脚本两条命令。
3.2.6 变量和属性set
功能:打印出命名空间hivevar,hiveconf,system,env所有的变量
查看所有环境变量:
hive> set -v;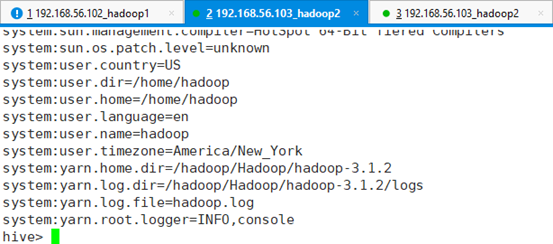
只显示与hadoop不同的配置:
hive> set;
3.2.6.1 显示当前数据库
之前的命令中,当进入某个数据库候,命令不会显示当前在哪个数据库,不利于操作,可以通过set命令让其显示出来。
命令:set hive.cli.print.current.db=true;开启后,就可以显示当前数据库名了。
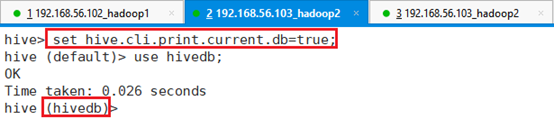
3.2.6.2 显示列名称
之前的命令中,当查询表数据时,也不会显示表字段名,可以通过set命令让其显示出来。
命令:set hive.cli.print.header=true;设置后,查询表信息时,显示了列表的字段名称

注意:这些设置只在当前cli模式下启用,退出再进入就失效了。
3.2.7 查看内置函数
命令:show functions;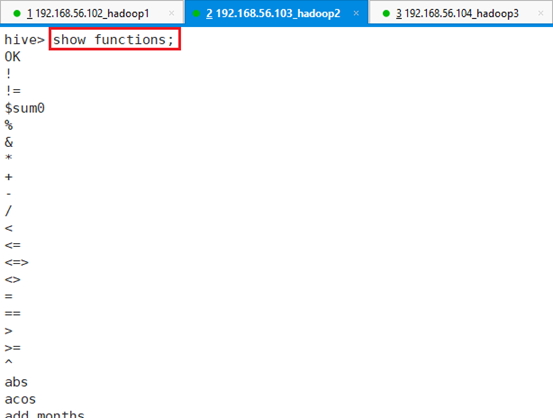
3.2.8 使用Hadoop的dfs命令
在Linux命令行中,访问HDFS目录,需要使用hdfs dfs –命令,比如查询根目录情况。
命令:hdfs dfs -ls /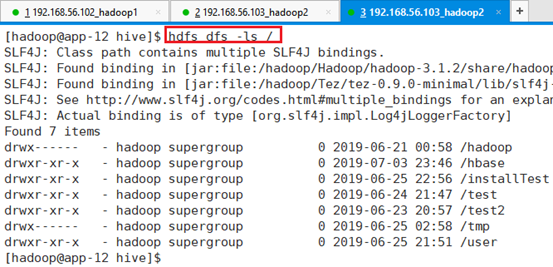
还可以直接在Hive的CLI命令行下执行HDFS命令,比如查询根目录情况。
命令:dfs -ls /;
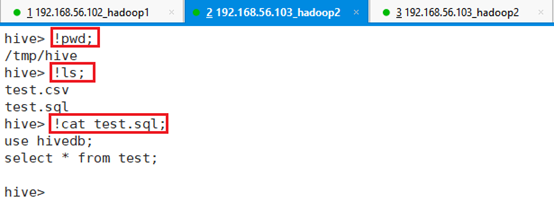
3.2.9 Hive下执行Linux命令
有时候我们需要在Hive的CLI命令行下执行Linux命令,比如查看本地文件之类的,可以通过如下方式执行
格式:!Linux命令;
- 比如查看当前目录命令:!pwd;
- 比如查看当前目录下文件命令:!ls;
- 比如查看文件内容命令:!cat 文件名;