一、Linux文件系统组成
superblock:记录此filesystem 的整体信息,包括inode/block的总量、使用量、剩余量, 以及档案系统的格式与相关信息等;
inode:记录档案的属性,一个档案占用一个inode,同时记录此档案的资料所在的block 号码;
block:实际记录档案的内容,若档案太大时,会占用多个block 。
inode和block在文件系统格式化时就已经建好了。除非重新格式化,否则后续不会改变。
二、读文件
2.1 Linux文件系统
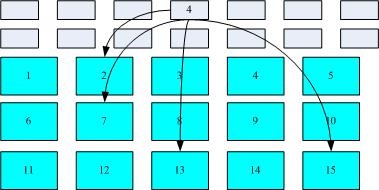
假设某一个档案的属性与权限资料是放置到inode 4 号(下图较小方格内),而这个inode 记录了档案资料的实际放置点为2, 7, 13, 15 这四个block 号码,此时我们的作业系统就能够据此来排列磁盘的读取顺序,可以一口气将四个block 内容读出来!那么资料的读取就如同下图中的箭头所指定的模样了。
2.2 FAT文件系统
U盘(快闪记忆体),U盘使用的档案系统一般为FAT格式。FAT这种格式的档案系统并没有inode存在,所以FAT没有办法将这个档案的所有block在一开始就读取出来。每个block号码都记录在前一个block当中,他的读取方式有点像底下这样:
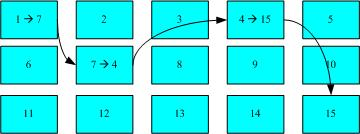
没有办法一口气就知道四个block 的号码,他得要一个一个的将block 读出后,才会知道下一个block 在何处。如果同一个档案资料写入的block 分散的太过厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的资料, 因此磁盘就会多转好几圈才能完整的读取到这个档案的内容!
碎片整理:就是档案写入的block太过于离散了,此时档案读取的效能将会变的很差所致。 这个时候可以透过碎片整理将同一个档案所属的blocks汇整在一起,这样资料的读取会比较容易啊!
三、Ext2
当文件大小高达数百GB时,那么将所有的inode与block通通放置在一起将是很不智的决定,因为inode与block的数量太庞大,不容易管理。
因此Ext2 文件系统在格式化的时候基本上是区分为多个区块群组(block group) 的,每个区块群组都有独立的 inode/block/superblock 系统。即每个分区第一个扇区有自己的bootsector,记录每个区块。
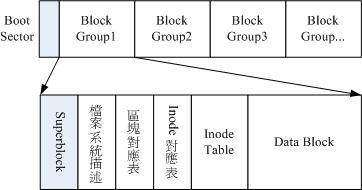
3.1 data block (资料区块)
在Ext2档案系统中所支持的block大小有1K, 2K及4K三种。每个block都有编号,方便inode的记录。block大小而产生的Ext2档案系统限制如下:block大小,文件大小,文件系统大小
1KB->16GB->2TB
2KB->256GB->8TB
4KB->2TB->16TB- block 的大小与数量在格式化完就不能够再改变了(除非重新格式化);
- 每个block 内最多只能够放置一个文件的资料;
- 若文件大于block 的大小,则一个文件会占用多个block 数量;
- 若文件小于block ,则该block 的剩余容量就不能够再被使用了(磁盘空间会浪费)。
3.2 inode table (inode 表格)
inode 的数量与大小也是在格式化时就已经固定了:
- 每个inode 大小均固定为128 bytes (新的ext4 与xfs 可设定到256 bytes);
- 每个文件都仅会占用一个inode 而已;
- 文件系统能够建立的文件数量与inode 的数量有关;
- 系统读取文件时需要先找到inode,并分析inode 所记录的权限与使用者是否符合,若符合才能够开始实际读取 block 的内容。
inode 要记录的资料非常多,但偏偏又只有128bytes 而已, 而inode 记录一个block 号码要花掉4byte ,假设我一个档案有400MB 且每个block 为4K 时, 那么至少也要十万笔block 号码的记录呢!inode 哪有这么多可记录的信息?
为此我们的系统很聪明的将inode 记录block 号码的区域定义为12个直接,一个间接, 一个双间接与一个三间接记录区。

以block大小为1KB为例计算最大文件16GB的由来:
- 12个直接指向:12*1K=12K 由于是直接指向,所以总共可记录12笔记录,因此总额大小为如上所示;
- 间接:256*1K=256K,每笔block号码的记录会花去4bytes,因此1K的大小能够记录256笔记录,因此一个间接可以记录的档案大小如上;
- 双间接:256*256*1K=65526K,第一层block会指定256个第二层,每个第二层可以指定256个号码,因此总额大小如上;
- 三间接:256*256*256*1K=16777216K,第一层block会指定256个第二层,每个第二层可以指定256个第三层,每个第三层可以指定256个号码,因此总额大小如上;
- 总额:将直接、间接、双间接、三间接加总,得到:12 + 256 + 65526 + 16777216K = 16GB
3.3 superblock (超级区块)
一般来说,superblock的大小为1024bytes,记录的信息主要有:
- block 与inode 的总量;
- 未使用与已使用的inode / block 数量;
- block 与inode 的大小(block 为1, 2, 4K,inode 为128bytes 或256bytes);
- filesystem 的挂载时间、最近一次写入资料的时间、最近一次检验磁盘(fsck) 的时间等档案系统的相关信息;
- ……
从图中看,每个block group 内都会含有superblock,但是一般一个文件系统仅有一个superblock,事实上除了第一个block group 内会含有superblock 之外,后续的block group 不一定含有superblock , 而若含有superblock 则该superblock 主要是做为第一个block group 内superblock 的备份,这样可以进行superblock的救援呢!
3.4 filesystem Description (文件系统描述说明)
这个区段可以描述每个block group的开始与结束的block号码,以及说明每个区段(superblock, bitmap, inodemap, data block)分别介于哪一个block号码之间。这部份也能够用dumpe2fs来观察的。
3.5 block bitmap (区块对照表)
从block bitmap 当中可以知道哪些block 是空的,因此我们的系统就能够很快速的找到可使用的空间来存放文件。
同样,删除某些文件时,那么那些文件原本占用的block 号码就得要释放出来, 此时在block bitmap 当中相对应到该block 号码的标志就得要修改成为『未使用中』。
3.6 inode bitmap (inode 对照表)
与block bitmap 是类似的功能,只是block bitmap 记录的是使用与未使用的block 号码, 至于inode bitmap 则是记录使用与未使用的inode 号码
3.7 dumpe2fs: 查询Ext 家族superblock 信息的指令
[root@ai_bk pyrk]# dumpe2fs /dev/vda1
dumpe2fs 1.42.9 (28-Dec-2013)
Filesystem volume name: <none>
Last mounted on: /
Filesystem UUID: 21dbe030-aa71-4b3a-8610-3b942dd447fa
Filesystem magic number: 0xEF53
Filesystem revision #: 1 (dynamic)
Filesystem features: has_journal ext_attr resize_inode dir_index filetype needs_recovery extent 64bit flex_bg sparse_super large_file huge_file uninit_bg dir_nlink extra_isize
Filesystem flags: signed_directory_hash
Default mount options: user_xattr acl
Filesystem state: clean
Errors behavior: Continue
Filesystem OS type: Linux
Inode count: 3276800
Block count: 13106944
Reserved block count: 655341
Free blocks: 10878654
Free inodes: 3210489
First block: 0
Block size: 4096
Fragment size: 4096
Group descriptor size: 64
Reserved GDT blocks: 1017
Blocks per group: 32768
Fragments per group: 32768
Inodes per group: 8192
Inode blocks per group: 512
RAID stride: 32411
Flex block group size: 16
Filesystem created: Wed Aug 8 11:08:44 2018
Last mount time: Wed Jun 17 16:01:21 2020
Last write time: Wed Jun 17 16:01:20 2020
Mount count: 41
Maximum mount count: -1
Last checked: Wed Aug 8 11:08:44 2018
Check interval: 0 (<none>)
Lifetime writes: 568 GB
Reserved blocks uid: 0 (user root)
Reserved blocks gid: 0 (group root)
First inode: 11
Inode size: 256
Required extra isize: 28
Desired extra isize: 28
Journal inode: 8
First orphan inode: 532200
Default directory hash: half_md4
Directory Hash Seed: e14af616-be46-451b-96b5-09d01fea6882
Journal backup: inode blocks
Journal features: journal_incompat_revoke journal_64bit
Journal size: 128M
Journal length: 32768
Journal sequence: 0x0044a998
Journal start: 25681
Group 0: (Blocks 0-32767) [ITABLE_ZEROED]
Checksum 0x8833, unused inodes 0
Primary superblock at 0, Group descriptors at 1-7
Reserved GDT blocks at 8-1024
Block bitmap at 1025 (+1025), Inode bitmap at 1041 (+1041)
Inode table at 1057-1568 (+1057)
20514 free blocks, 15 free inodes, 1275 directories
Free blocks: 9702, 9871, 10597, 10793, 12190, 12192, 12208, 12250, 12262-32767
Free inodes: 434, 951, 955, 1821-1827, 2253, 5460, 7913, 7916-7917
Group 1: (Blocks 32768-65535) [ITABLE_ZEROED]
................
Group 399: (Blocks 13074432-13106943) [INODE_UNINIT, ITABLE_ZEROED]
Checksum 0xf960, unused inodes 8192
Block bitmap at 12582927 (bg #384 + 15), Inode bitmap at 12582943 (bg #384 + 31)
Inode table at 12590624-12591135 (bg #384 + 7712)
32512 free blocks, 8192 free inodes, 0 directories, 8192 unused inodes
Free blocks: 13074432-13106943
Free inodes: 3268609-3276800从总表中我们可以发现:
- inode数量:Inode count: 3276800
- block数量:Block count: 13106944
- 可用的block数量:Free blocks: 10878654
- 可用的inode数量:Free inodes: 3210489
- 块大小:Block size: 4096
从上Group 0可以发现:
- Group0 所占用的block 号码由0 到32767 号,superblock 则在第0 号的block 区块内!
- 文件系统描述说明在第1 号block 中;
- block bitmap 与inode bitmap 则在129 及145 的block 号码上。
- inode table 分布于161-672 的block 号码中!
- 由于(1)一个inode 占用256 bytes ,(2)总共有672 – 161 + 1(161本身) = 512 个block 花在inode table 上, (3)每个block 的大小为4096 bytes(4K)。由这些数据可以算出inode 的数量共有512 * 4096 / 256 = 8192 个inode ;
- 这个Group0 目前可用的block 有28521 个,可用的inode 有8181 个;
- 剩余的inode 号码为12 号到8192 号。
四、目录及文件的建立、删除、查找
建立一个目录时,会分配一个inode与至少一块block给该目录。其中,inode记录该目录的相关权限与属性,并可记录分配到的那块block号码;而block则是记录在这个目录下的文件名与文件占用的inode号。
建立一个文件时, ext2 会分配一个inode 与相对于该档案大小的block 数量给该文件。例如:建立一个100 KBytes 的文件,那么linux 将分配一个inode 与25 个block 来储存该档案!但同时请注意,由于inode 仅有12 个直接指向,因此还要多一个block 来作为区块号码的记录!
文件的读取顺序:由于目录树是由根目录开始读起,因此系统透过挂载的信息可以找到挂载点的inode 号码,此时就能够得到根目录的inode 内容,并依据该inode 读取根目录的block 内的档名资料,再一层一层的往下读到正确的档名。
比如想要读取/etc/passwd 这个档案时,系统是如何读取的呢?
[root@ai_bk www]# ll -di / /etc /etc/passwd
2 dr-xr-xr-x. 19 root root 4096 Jul 21 09:11 /
262147 drwxr-xr-x. 96 root root 12288 Jun 24 11:15 /etc
266060 -rw-r--r-- 1 root root 1331 Nov 2 2019 /etc/passwd/的inode:透过挂载点的信息找到inode号码为2的根目录inode,且inode的权限属性允许我们可以读取该block的内容(有r与x) ;
/的block:经过上个步骤取得block的号码,并找到该内容有etc/目录的inode号码(262147);
etc/的inode:读取262147号inode得知具有r与x的权限,因此可以读取etc/的block内容;
etc/的block:经过上个步骤取得block号码,并找到该内容有passwd档案的inode号码(266060);
passwd的inode:读取266060号inode得知具有r的权限,因此可以读取passwd的block内容;
passwd的block:最后将该block内容的资料读出来。