完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
十三、Oozie-大数据流程引擎
Oozie框架用来解决工作流,特别是大数据处理工作流任务的框架。
13.1 工作流的必要性
在大数据处理领域,创建一个端到端的应用,常常会涉及很多步骤,比如获取数据并加载到Hive数据仓库,然后执行数据处理任务,比如Spark任务、Hive处理任务或MapReduce处理任务,以及中间过程中需要处理一些定时、调度脚本,需要有一些shell脚本,这些流程化的节点如何串接在一起。
使用传统的方式如脚本,调java程序用java –jar,Spark用submit脚本等可以做到,但是这种效率低下,而且没有可视化处理,以及相应脚本错误处理通知及监控操作没法自动化及精确化处理,不同的步骤之间逻辑以及精细化调度也很难做精细化处理。
需要一个工作流引擎,特别是大数据领域的引擎支撑这种应用。如果自己做一些相应的脚本,比如说Spark脚本,则需要写Spark相关的一些脚本,通过Spark submit提交任务,这种效率是比较低的,为什么不去模拟一个Spark提价任务的client端,数据处理任务仅仅是写一个处理函数,相关的步骤需要一个框架去处理。
Oozie就满足了这一点,Oozie是大数据工作流引擎引入的一个必须条件,这个调度器和之前做的Java调度器是不一样的,Oozie调度器是针对大数据处理的调度器,适合现有大数据处理框架功能而生的,比如有Spark的、Hive的、Hadoop的等,这是一套大数据处理所特有的框架,而不仅仅是做一个可视化工作流的工作。
13.2 Oozie基本概念
接下来描述Oozie怎么实现大数据工作流引擎的。
13.2.1 架构
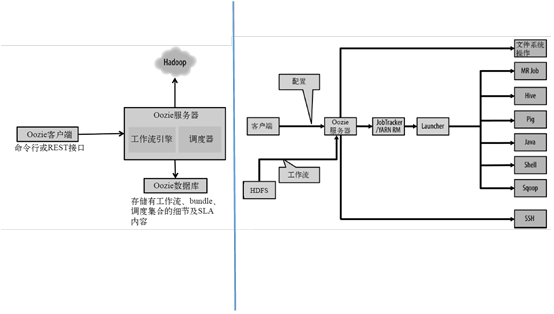
基本架构如图,Oozie的客户端、命令行或者RESET接口提交JOB给Oozie服务器,Oozie服务器上的调度器调度任务在hadoop集群上执行,因此Oozie服务端需要有一个做相应大数据处理的lib库,支撑Oozie客户端提交的任务在集群上执行,此外还有针对工作流引擎的关系型数据库为存储工作流细节做支撑。
右边图为客户端提交任务之后的详细情况,将JOB提交到HDFS后,集群上所有的节点就可以通过HDFS下载JOB的详细配置信息和执行代码,由Oozie的服务器调度执行。然后提交到集群上,由YARN的ResourceManager去Launcher JOB,JOB有MR、Hive、Pig、Java、Shell、Sqoop、SSH以及Spark等等,这些JOB都会是做支撑的Action单元,其中需要和文件系统HDFS做相应的集成。
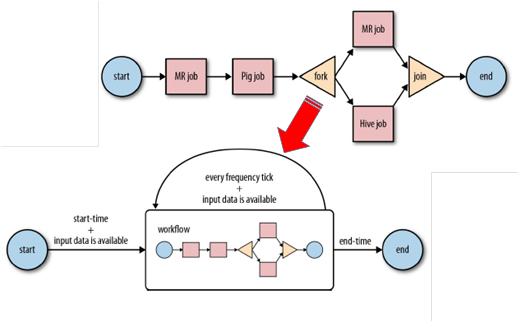
13.2.2 流程
如图为Oozie的流程,开始后,需要做一个MR job,再做一个Pig job,接着fork两个job,一个是MR job,一个是Pig job,将两个Job的结果做一次join后结束。反映的是下面的流程,工作流基本都类似。流程图上每个流程都是一个节点action,做什么动作,这个动作是和什么动作并发的执行,或者说它的输入是什么,输出是什么,输出结果产生什么样的工作,这个就是工作流引擎的基本点。Oozie是专门为大数据处理所定制的,最起码需要集成相应的库,比如MR、Hive、Pig、Spark等相应库,或者说它要支持这些框架的任务在其调度器上执行,关键点就是如何适配这些框架,如何包含这些框架的库,是Spark部署的核心点,也是一个难点。
流程部分就是一个个action,也可以认为是一个个的任务,action包括:Email Action、Action、Shell Action、Hive Action、Hive2 Action、Sqoop Action、Ssh Action、DistCp Action、Sparm Action、new Custom Action Executor 。最核心点就是编写action,针对不同的任务编写不同的action。
13.3 环境搭建
环境搭建之前需要先进行编译。
13.3.1 编译
使用sh连接到app-11,切换到hadoop用户,新建目录:mkdir /tmp/oozie
上传文件到/tmp/oozie
buildOozie.sh可以将整个编译过程自动化
#!/bin/sh
if [ "hadoop" != `whoami` ]; then echo "run in hadoop user" && exit ; fi
export MAVEN_REPO_DIR=/tmp/maven/repo
rm -rf $MAVEN_REPO_DIR
tar -xf repo.tar.gz -C /tmp/maven/
tar -xvf oozie-5.0.0.tar.gz
rm -rf oozie-5.0.0/pom.xml
cp pom.xml oozie-5.0.0/
rm -rf $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-core/1.0-alpha-9.2y
rm -rf $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-module-twiki/1.0-alpha-9.2y
mkdir -p $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-core/1.0-alpha-9.2y
mkdir -p $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-module-twiki/1.0-alpha-9.2y
cp doxia-module-twiki-1.0-alpha-9.2y.jar $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-module-twiki/1.0-alpha-9.2y/
cp doxia-core-1.0-alpha-9.2y.jar $MAVEN_REPO_DIR/org/apache/maven/doxia/doxia-core/1.0-alpha-9.2y/
cd oozie-5.0.0
bin/mkdistro.sh -DskipTests -Dtez.version=0.9.0 -Ptez -P'spark-2' -Puber剩下的为安装过程中需要的Jar包。
还将编译完成后的整个maven本地库也备份下来了,可以直接将maven库进行复原,更快的进行编译。
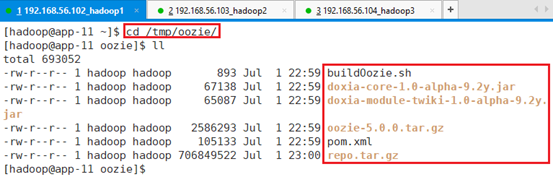
给安装脚本赋予执行权限:chmod a+x buildOozie.sh
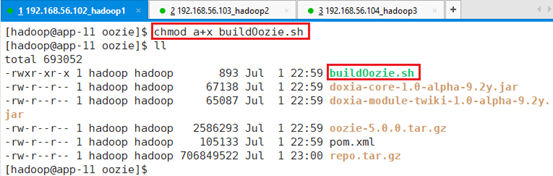
修改maven的配置文件
vi /hadoop/tools/apache-maven-3.6.0/conf/settings.xml因为安装文件buildOozie.sh会把repo.tar.gz解压缩到/tmp/maven/repo中

确认环境变量已经加maven
export MVN_HOME=/hadoop/tools/apache-maven-3.6.0
export PATH=$PATH:${MVN_HOME}/bin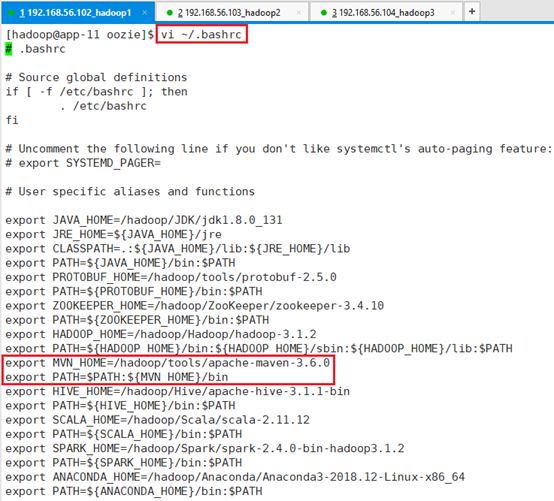
环境变量生效:source ~/.bashrc
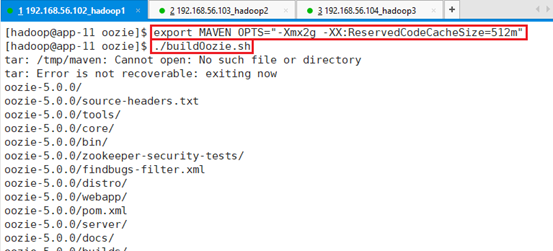
设置:export MAVEN_OPTS=”-Xmx2g -XX:ReservedCodeCacheSize=512m”
运行自动安装脚本:./buildOozie.sh
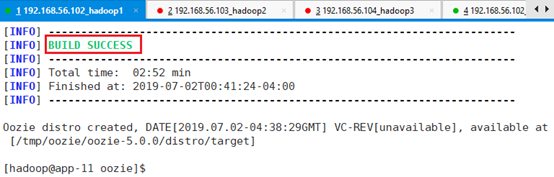
生成两个安装包
/tmp/oozie/oozie-5.0.0/distro/target/oozie-5.0.0-distro.tar.gz
/tmp/oozie/oozie-5.0.0/sharelib/target/oozie-sharelib-5.0.0.tar.gz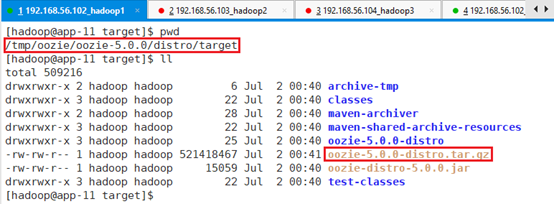

13.3.2 安装
安装环节分为两步,第一步只做共享库,第二部安装client和server。
13.3.2.1 启动集群
用ssh登录app-11,切换到hadoop用户,启动集群:./startAll.sh
确认是否成功启动:jps

13.3.2.2 准备
清空/tmp/oozie目录:rm -rf /tmp/oozie/*.*

上传编译后的文件oozie-5.0.0-distro.tar.gz、oozie-sharelib-5.0.0.tar.gz到/tmp/oozie目录。
- oozie-5.0.0-distro.tar.gz为server和client的发布版本。
- oozie-sharelib-5.0.0.tar.gz为sharelib。


13.3.2.3 make sharelib
由于Oozie使用的方法是要集成各个框架,如要执行Hive的action、执行Spark的action,需要集成Spark的jar包、Hive的jar包,通过jar包调度相应的程序去执行,可以认为是库函数,需要把这些库函数集成在一起,上传到HDFS上,这样提交的任务只需要提交自己编写的程序即可,Oozie去sharelib取相应的库函数,完成整个任务的调度。Oozie不是依赖于装在本地的机器库,而是依赖于HDFS上的共享库,有自己共享库的管理标准。
为什么在编译的时候不把这些共享库按照集群版本生成出来,是因为编译的时候无法生成对应版本的sharelib包,并不支持所有框架的所有版本的编译,所以需要用过另一个手段,将集群上其他版本的提供的jar包集成到sharelib中,自己制作一个针对集群的sharelib包。
接下来重新制作sharelib。
解压缩:tar -xf oozie-sharelib-5.0.0.tar.gz
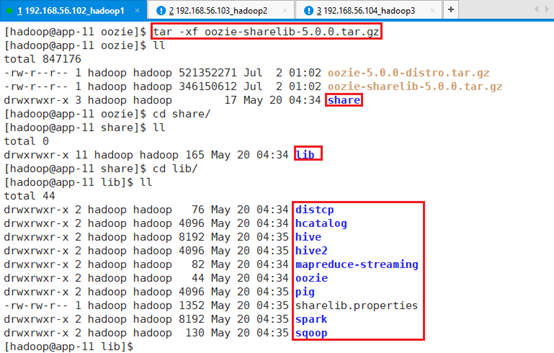
13.3.2.3.1 hive2
删除hive目录,有hive2目录就行
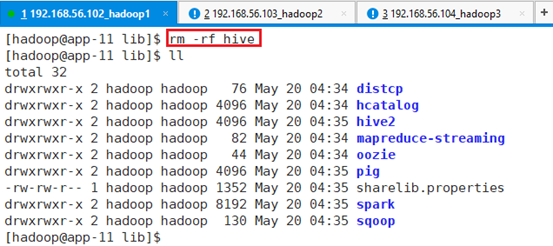
备份hive2目录下的oozie jar包oozie-sharelib-hive2-5.0.0.jar:
mv hive2/oozie-sharelib-hive2-5.0.0.jar .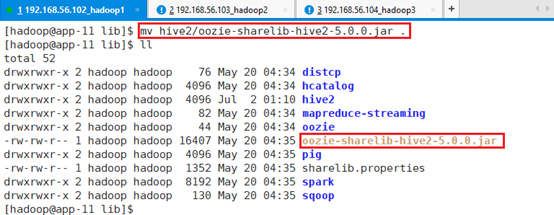
删除hive2目录下所有包:rm -rf hive2/*

将备份的文件移回hive2目录:mv oozie-sharelib-hive2-5.0.0.jar hive2/

需要将Hive master上节点的包拷贝到该位置
由于Hive安装在app-12节点上,用ssh连接到app-12,并切换到hadoop用户。
将app-12节点中/hadoop/Hive/apache-hive-3.1.1-bin/lib目录下的所有文件都拷贝到app-11节点的/tmp/oozie/share/lib/hive2目录
在app-11节点:
scp -r -q app-12:/hadoop/Hive/apache-hive-3.1.1-bin/lib/* ./
至此,hive库创建完毕。
13.3.2.3.2 spark2
创建spark2目录:mkdir spark2
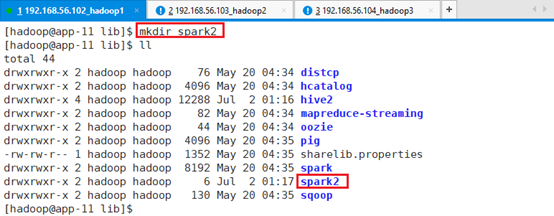
复制spark下的jar包oozie-sharelib-spark-5.0.0.jar到spark2
cp spark/oozie-sharelib-spark-5.0.0.jar spark2/
将spark的jar包拷贝到spark2:
cp /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/jars/* ./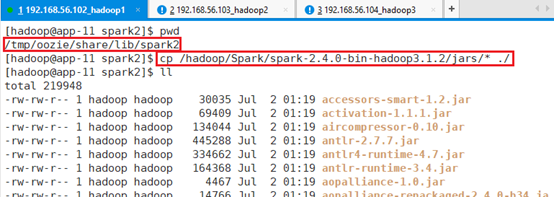
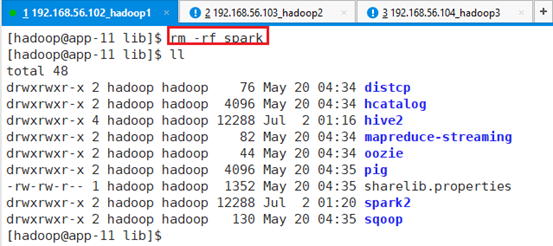
删除spark目录,保留spark2目录就行:rm -rf spark
解压缩安装包:tar -xf oozie-5.0.0-distro.tar.gz
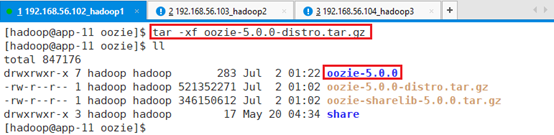
删除/tmp/oozie/oozie-5.0.0目录下的oozie-sharelib-5.0.0.tar.gz
rm -rf oozie-sharelib-5.0.0.tar.gz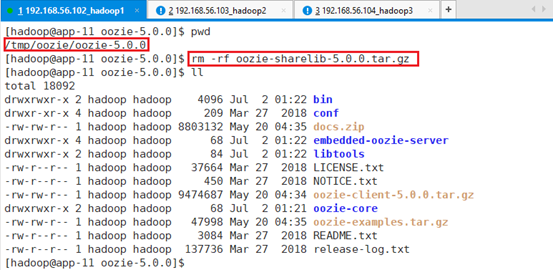
将/tmp/oozie/oozie-5.0.0/embedded-oozie-server/webapp/WEB-INF/lib目录下的api-util-1.0.0-M20.jar拷贝到/tmp/oozie/share/lib/spark2/:
cp api-util-1.0.0-M20.jar /tmp/oozie/share/lib/spark2/api-util-1.0.0-M20.jar有助于调度spark2 的action,否则会报错。
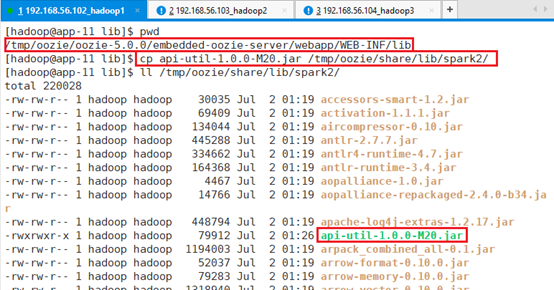
此外为了支持pyspark,需要将pyspark相关的代码库拷贝到spark2目录下
cp /hadoop/Spark/spark-2.4.0-bin-hadoop3.1.2/python/lib/*.zip /tmp/oozie/share/lib/spark2/
至此sharelib创建完成。
13.3.2.3.3 打包
为了方便,接着将文件夹oozie-5.0.0、share打包:
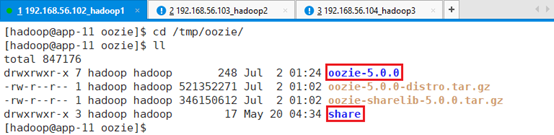
删除原有gz文件:rm -rf *.gz
打包
tar -czf oozie-sharelib-5.0.0.tar.gz share
tar -czf oozie-5.0.0-distro.tar.gz oozie-5.0.0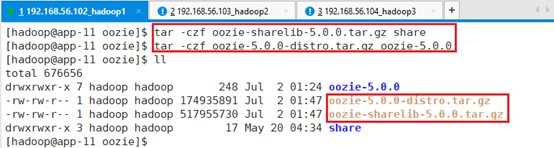
资源文件上有已经打包好的文件

13.3.2.4 安装client和server
client包含在server中,仅仅安装server即可,当然可以安装多个client,可以在app-12、app-13上安装client。
13.3.2.4.1 准备
在app-11上安装server,该server包含了client。
删除文件夹:oozie-5.0.0和share:rm -rf oozie-5.0.0 share

创建Oozie文件夹:mkdir /hadoop/Oozie
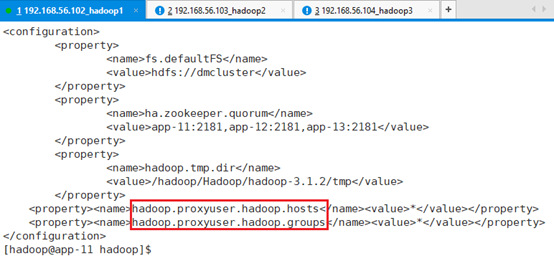
确保hadoop的配置文件/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/core-site.xml有这两项。
<property><name>hadoop.proxyuser.hadoop.hosts</name><value>*</value></property>
<property><name>hadoop.proxyuser.hadoop.groups</name><value>*</value></property>注意:如果没有,添加完成后,需要重启整个集群。
将文件/tmp/oozie/oozie-5.0.0-distro.tar.gz解压缩到/hadoop/Oozie目录
tar -xf /tmp/oozie/oozie-5.0.0-distro.tar.gz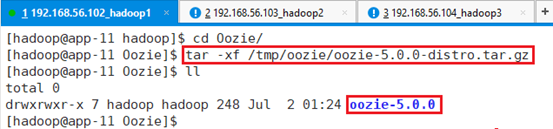
在目录/hadoop/Oozie/oozie-5.0.0下创建libext目录:mkdir libext
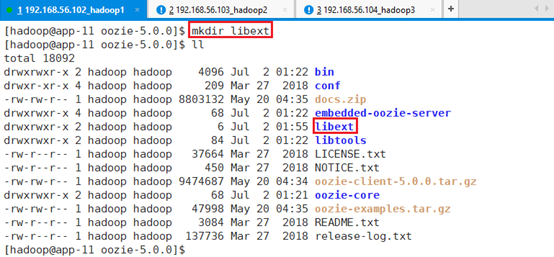
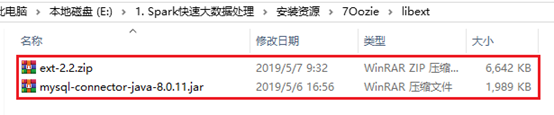
将资源文件中的两个文件拷贝到libext目录
由于oozie需要界面,需要javascript库。
oozie的server需要连接Mysql,所有流程放在关系型数据里面进行持久化,任务信息才能够随时查阅。

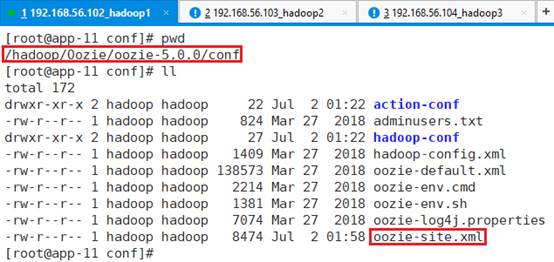
13.3.2.4.2 配置
替换配置文件/hadoop/Oozie/oozie-5.0.0/conf/oozie-site.xml

<?xml version="1.0"?>
<configuration>
<property>//配置oozie节点
<name>oozie.http.hostname</name>
<value>app-11</value>
</property>
<property>//mysql数据库
<name>oozie.service.JPAService.jdbc.driver</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>//mysql数据库URL,安装在APP-12节点
<name>oozie.service.JPAService.jdbc.url</name>
<value>jdbc:mysql://app-12:3306/oozie?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT</value>
</property>
<property>//数据库用户名,后续建
<name>oozie.service.JPAService.jdbc.username</name>
<value>oozie</value>
</property>
<property>//密码
<name>oozie.service.JPAService.jdbc.password</name>
<value>Yhf_1018</value>
</property>
<property>
<name>oozie.service.HadoopAccessorService.hadoop.configurations</name>
<value>*=/hadoop/Hadoop/hadoop-3.1.2/etc/hadoop</value>
</property>
</configuration>Oozie需要和hadoop集成,需要知道Hadoop的情况
删除目录/hadoop/Oozie/oozie-5.0.0/conf/hadoop-conf下的所有文件:rm -rf *.*
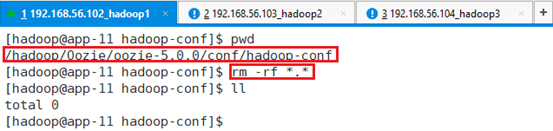
拷贝hadoop相关的配置文件到该目录下:
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/core-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/hdfs-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/mapred-site.xml ./
cp /hadoop/Hadoop/hadoop-3.1.2/etc/hadoop/yarn-site.xml ./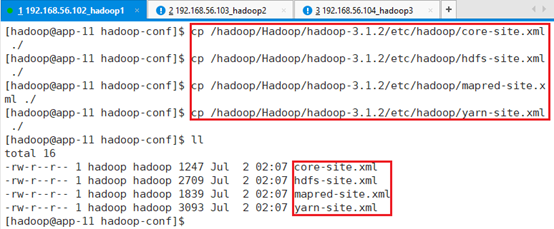
如果想在其他节点安装client,只需要将oozie-client-5.0.0.tar.gz拷贝到其他节点,并解压缩赋予执行权限即可。
13.3.2.4.3 配置mysql
ssh连接到app-12,登录mysql,不需要切换到hadoop用户:mysql -uroot -p

创建数据库oozie:create database oozie;

创建用户’oozie’,不限制IP登录,并设置密码:
create user 'oozie'@'%' identified by 'Yhf_1018';赋予oozie用户操作oozie数据库的权限:
grant all privileges on oozie.* to 'oozie'@'%' with grant option;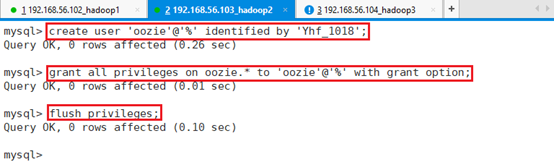
查看用户
SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user;
quit退出

13.3.2.4.4 sharelib
将sharelib上传到HDFS系统
bin/oozie-setup.sh sharelib create -fs hdfs://dmcluster -locallib /tmp/oozie/oozie-sharelib-5.0.0.tar.gz显示路径及对应的版本信息,供后续使用。

查看库文件:
hdfs dfs -ls /user/hadoop/share/lib/lib_20190520233444看出对库文件进行解压并上传到相应的位置。
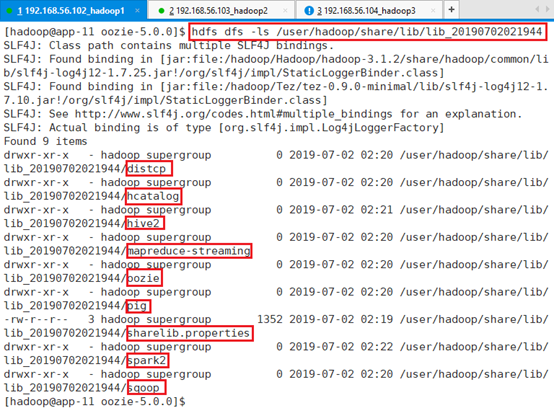
拷贝文件mysql-connector-java-8.0.11.jar到lib目录:
cp libext/mysql-connector-java-8.0.11.jar lib/
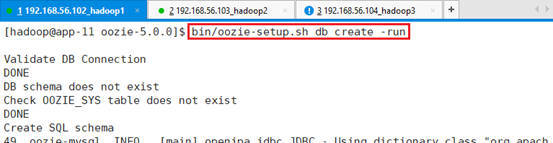
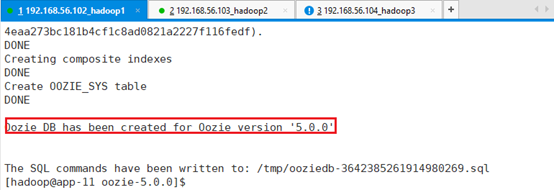
初始化数据库:bin/oozie-setup.sh db create -run
进行序列验证并创建
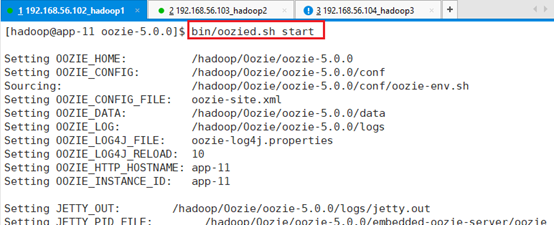
启动oozie server脚本:bin/oozied.sh start
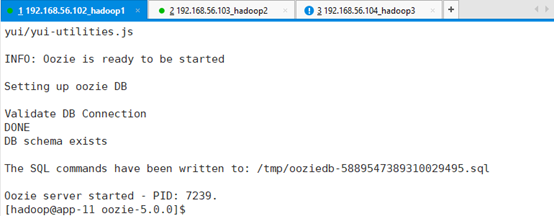
还可以检验,现在系统里面用的是哪个,包括了什么内容?
bin/oozie admin -shareliblist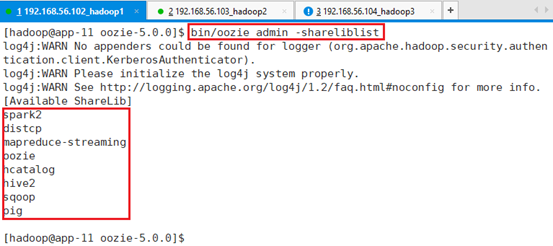
可以看到和当时制作sharelib是一致的。
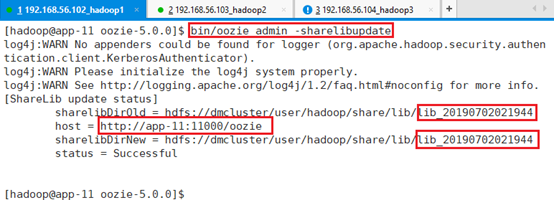
如果需要增加目录,或者在目录下增加某个jar文件,则需要
bin/oozie admin -sharelibupdate注意:位置不会发生变化
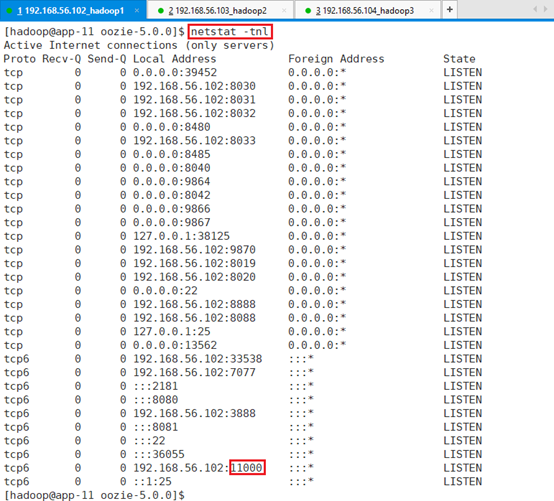
13.3.2.4.5 验证
通过端口监控查11000端口:netstat –tnl
Oozie对外访问的web端口为11000
Web页面登录:http://app-11:11000/
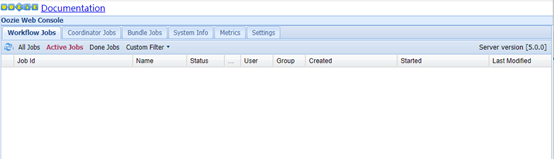
说明oozie server正常启动了。
13.3.3 自动启停
13.3.3.1 配置
在/hadoop/config.conf文件中添加:export OOZIE_IS_INSTALL=True
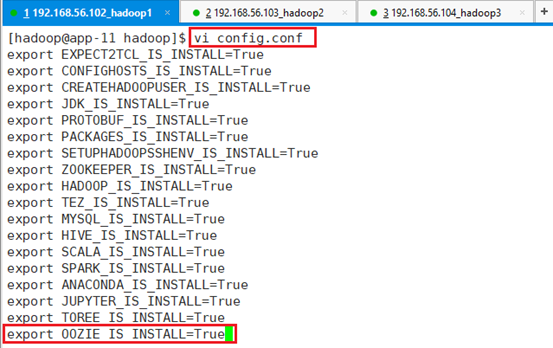
确认/hadoop/startAll.sh中包含了oozie的启动

确认/hadoop/stopAll.sh中包含了oozie的关闭

13.3.3.2 启停脚本
上传脚本文件到/Hadoop/tools目录:
#!/bin/sh
nodeArray="app-11"
for node in $nodeArray
do
ssh $node "cd /hadoop/Oozie/oozie-5.0.0 && bin/oozied.sh start "
sleep 1m
ssh $node "cd /hadoop/Oozie/oozie-5.0.0 && bin/oozie admin -oozie http://$node:11000/oozie -status "
done#!/bin/sh
nodeArray="app-11"
for node in $nodeArray
do
ssh $node "cd /hadoop/Oozie/oozie-5.0.0 && bin/oozied.sh stop "
done
赋予脚本执行权限:chmod a+x *zie.sh
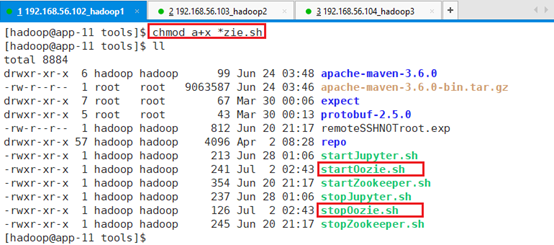
13.3.3.3 环境变量
增加环境变量:vi ~/.bashrc
export OOZIE_HOME=/hadoop/Oozie/oozie-5.0.0
export OOZIE_CONFIG=$OOZIE_HOME/conf
export PATH=$PATH:${OOZIE_HOME}/bin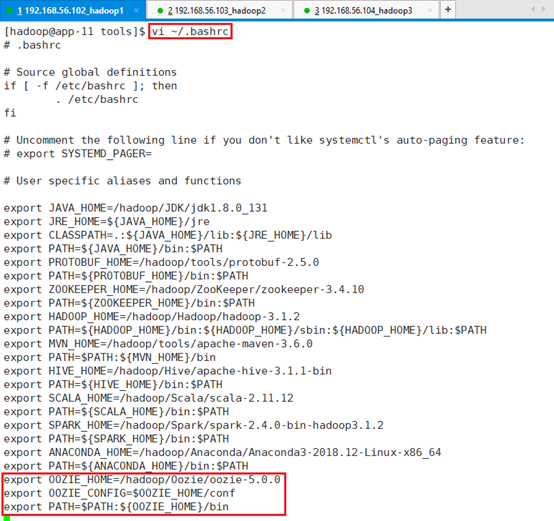
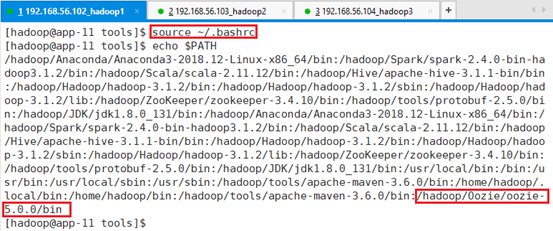
启动环境变量:source ~/.bashrc
13.4 编程实战
本质就是编写对应的action,比如spark的,基于这个观点,分成以下部分:
- 定时action:cron action;
- 执行shell脚本action:shell action;
- MapReduce action:MR action;
- 基于spark2编写spark action,用java程序编写的jar包,在集群上运行;
- 用python编写的spark处理程序,将程序提交给集群执行;
- 基于Hive2的action,通过连接server,让hive的master处理请求。
13.4.1 启动集群
用ssh连接app-11,切换到hadoop用户,启动集群./startAll.sh
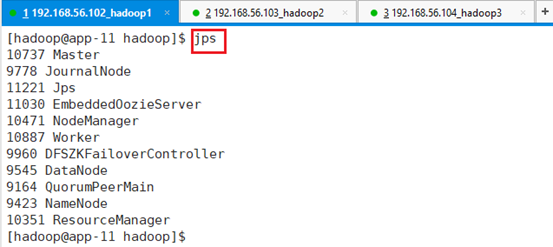
确认:jps
13.4.2 准备
将六个案例源文件

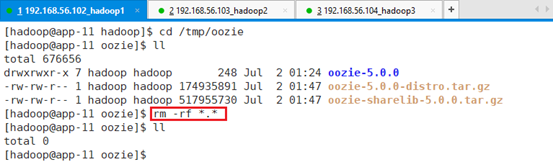
清空/tmp/oozie目录:rm -rf *
上传到/tmp/oozie

13.4.3 配置文件解析
13.4.3.1 job.properties
流程的属性定义文件,定义了流程运行期间使用的外部参数值对。
| 参数 | 含义 |
| nameNode | HDFS NameNode集群地址 |
| jobTracker | MapReduce ResourceManager地址 |
| queueName | 流程任务处理时使用的MapReduce队列名 |
| dataLoadRoot | 流程任务所在目录名 |
| oozie.coord.application.path | Coordinator流程任务在HDFS上的存放路径 |
| Start | 定时流程任务启动时间 |
| End | 定时流程任务终止时间 |
| workflowAppUri | Workflow流程任务在HDFS上的存放路径 |
13.4.3.2 workflow.xml
描述了一个完整业务的流程定义文件。一般由一个start节点、一个end节点和多个实现具体业务的action节点组成。
| 参数 | 含义 |
| name | 流程文件名 |
| start | 流程开始节点 |
| end | 流程结束节点 |
| action | 实现具体业务动作的节点(可以是多个) |
13.4.3.3 coordinator.xml
周期性执行workflow类型任务的流程定义文件。
多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后一个workflow的输入,也可以定义workflow的触发条件,来做定时触发。
| 参数 | 含义 |
| Frequency | 流程定时执行的时间间隔 |
| Start | 定时流程任务启动时间 |
| End | 定时流程任务终止时间 |
| workflowAppUri | Workflow流程任务在HDFS上的存放路径 |
| jobTracker | MapReduce ResourceManager地址 |
| queueName | 任务处理时使用的Mapreduce队列名 |
| nameNode | HDFS NameNode地址 |
13.4.4 Cron Action
做数据处理或者应用系统开发时,经常会遇到crontab,它是一种定时的方法。
按照如图方式产生定时的编码格式,还可以支持传统意义的crontab语法格式,具体查询相关网站,主要格式如下:


13.4.4.1 源文件
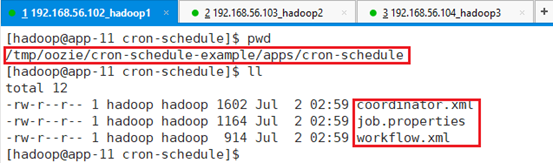
job.properties为提交集群,oozie运行的本地文件,各种参数配置包括路径、Url等。
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=cron-schedule-example
oozie.use.system.libpath=true
oozie.coord.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron-schedule
start=2019-01-01T00:00Z
end=2020-01-01T01:00Z
workflowAppUri=${nameNode}/user/${user.name}/${examplesRoot}/apps/cron-schedule
master=yarn-clusterworkflow.xml为工作流的定义文件,顺序执行流程节点,支持fork(分支多个节点),join(合并多个节点为一个)。
<workflow-app xmlns="uri:oozie:workflow:1.0" name="no-op-wf">
<start to="end"/>
<end name="end"/>
</workflow-app>coordinator.xml为oozie自带的表达式定时文件,定义起点时间、结束时间、多长时间执行一次、时区等,很多参数在job.properties文件里面定义。多个workflow可以组成一个coordinator,可以把前几个workflow的输出作为后一个workflow的输入,也可以定义workflow的触发条件,来做定时触发。
<coordinator-app name="cron-coord" frequency="${coord:minutes(10)}" start="${start}" end="${end}" timezone="UTC"
xmlns="uri:oozie:coordinator:0.2">
<action>
<workflow>
<app-path>${workflowAppUri}</app-path>
<configuration>
<property>
<name>resourceManager</name>
<value>${resourceManager}</value>
</property>
<property>
<name>nameNode</name>
<value>${nameNode}</value>
</property>
<property>
<name>queueName</name>
<value>${queueName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>13.4.4.2 上传HDFS
进入oozie安装目录:cd /hadoop/Oozie/oozie-5.0.0/
将整个程序上传到job.properties指定的路径。
创建HDFS目录
hdfs dfs -mkdir -p /user/hadoop/cron-schedule-example/apps/cron-schedule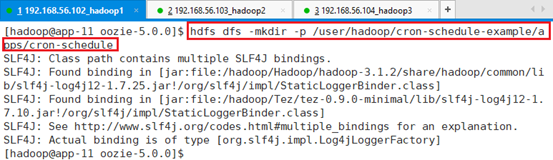
上传代码文件cron-schedule-example到指定目录
hdfs dfs -put /tmp/oozie/cron-schedule-example/apps/cron-schedule/* /user/hadoop/cron-schedule-example/apps/cron-schedule
确认上传成功
hdfs dfs -ls -R /user/hadoop/cron-schedule-example/apps/cron-schedule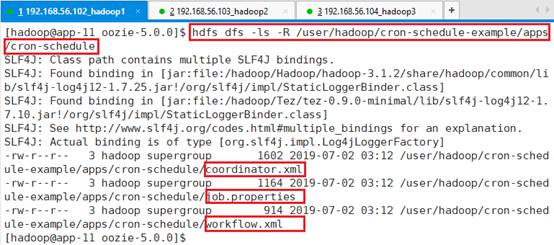
13.4.4.3 测试
文件上传成功,开始提交测试
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/cron-schedule-example/apps/cron-schedule/job.properties -run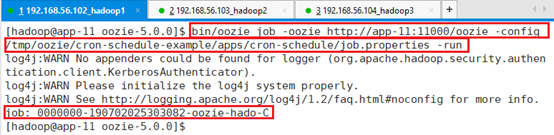
登录web页面查看app-11:11000

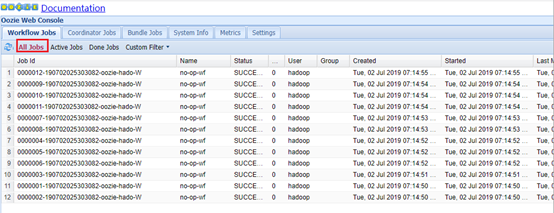
由于这个job是定时任务,会一直执行,需要人为结束。
查看任务0000000-190702025303082-oozie-hado-C信息
bin/oozie job -oozie http://app-11:11000/oozie -info 0000000-190702025303082-oozie-hado-C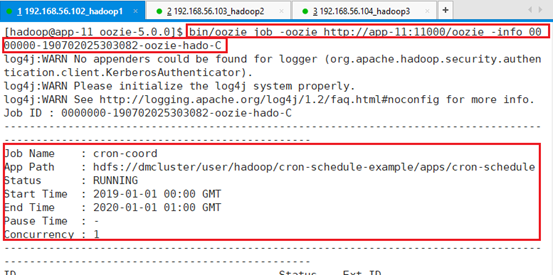
关闭任务0000000-190702025303082-oozie-hado-C
bin/oozie job -oozie http://app-11:11000/oozie -kill 0000000-190702025303082-oozie-hado-C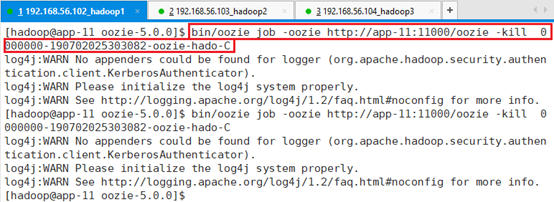
再查看web页面:已经没有了,退出了active状态

13.4.5 Shell Action
13.4.5.1 源文件
如何执行一序列的shell脚本,shell脚本在大数据处理里面是个很重要的角色

job.properties一些配置参数,包括路径、名字等。
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=shell-example
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/shell
EXEC=demo.sh
master=yarn-clusterworkflow.xml定义了哪些元素包含了哪些,具体参考官网。定义shell脚本是什么,位置在哪。基本逻辑为先执行脚本程序,然后将脚本的输出
<workflow-app xmlns="uri:oozie:workflow:1.0" name="shell-wf">
<start to="shell-node"/>
<action name="shell-node">
<shell xmlns="uri:oozie:shell-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<exec>${EXEC}</exec>
<file>${nameNode}/user/${wf:user()}/${examplesRoot}/apps/shell/${EXEC}#${EXEC}</file>
<capture-output/>
</shell>
<ok to="check-output"/>
<error to="fail"/>
</action>
<decision name="check-output">
<switch>
<case to="end">
${wf:actionData('shell-node')['my_output'] eq 'Hello Oozie'}
</case>
<default to="fail-output"/>
</switch>
</decision>
<kill name="fail">
<message>Shell action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<kill name="fail-output">
<message>Incorrect output, expected [Hello Oozie] but was [${wf:actionData('shell-node')['my_output']}]</message>
</kill>
<end name="end"/>
</workflow-app>脚本:demo.sh
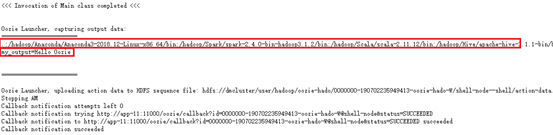
内容是输出Path路径,并打印一段话,测试。
#!/bin/sh
echo $PATH
echo my_output=Hello Oozie13.4.5.2 上传HDFS
创建目录:
hdfs dfs -mkdir -p /user/hadoop/shell-example/apps/shell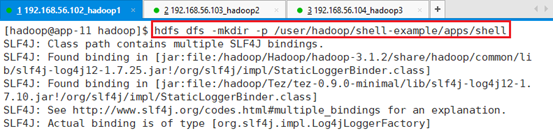
上传文件:
hdfs dfs -put /tmp/oozie/shell-example/apps/shell/* /user/hadoop/shell-example/apps/shell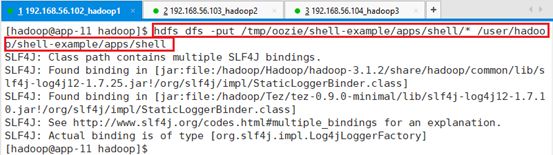
确认上传是否成功:hdfs dfs -ls /user/hadoop/shell-example/apps/shell

13.4.5.3 测试
提交:
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/shell-example/apps/shell/job.properties -run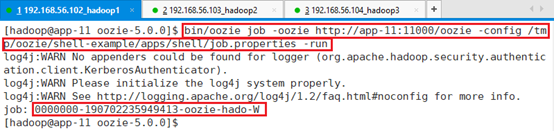
- Web页面确认:
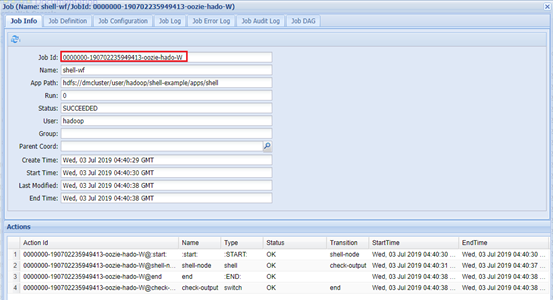
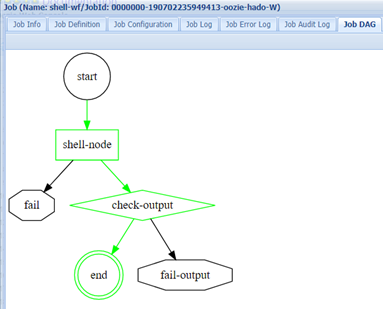
查看job dag:
这个就是整个流程图,绿色代表任务流程。
登录web页面:http://app-11:8088/cluster/apps
查看该任务的stdout日志
13.4.6 MR Action
13.4.6.1 源文件
代码文件对对应的库,做workcount。

测试数据

job.properties设置路径,输出目录等信息。
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=mapreduce-example
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/map-reduce/workflow.xml
outputDir=map-reduceworkflow.xml为ACTION的整个流程,包括如何配置属性,输入数据目录,输出数据目录,将farmwork指定为yarn和tez队列。
<workflow-app xmlns="uri:oozie:workflow:1.0" name="map-reduce-wf">
<start to="mr-node"/>
<action name="mr-node">
<map-reduce>
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<prepare>
<delete path="${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}"/>
</prepare>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
<property>
<name>mapred.mapper.class</name>
<value>org.apache.oozie.example.SampleMapper</value>
</property>
<property>
<name>mapred.reducer.class</name>
<value>org.apache.oozie.example.SampleReducer</value>
</property>
<property>
<name>mapred.map.tasks</name>
<value>1</value>
</property>
<property>
<name>mapred.input.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/input-data/text</value>
</property>
<property>
<name>mapred.output.dir</name>
<value>/user/${wf:user()}/${examplesRoot}/output-data/${outputDir}</value>
</property>
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>tez.queue.name</name><value>${queueName}</value></property></configuration>
</map-reduce>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Map/Reduce failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>13.4.6.2 上传HDFS
拷贝整个目录到HDFS
hdfs dfs -copyFromLocal /tmp/oozie/mapreduce-example/ /user/hadoop/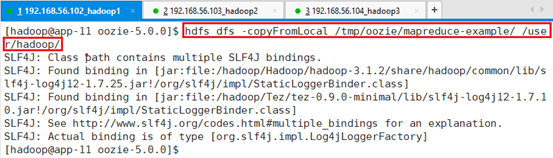
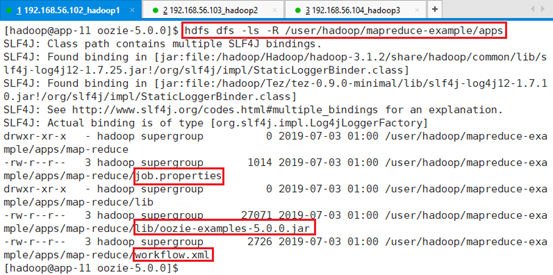
确认数据:hdfs dfs -ls /user/hadoop/mapreduce-example
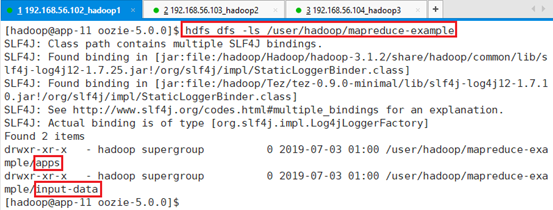
确认源文件:hdfs dfs -ls /user/hadoop/mapreduce-example
创建输出目录:
hdfs dfs -mkdir /user/hadoop/mapreduce-example/output-data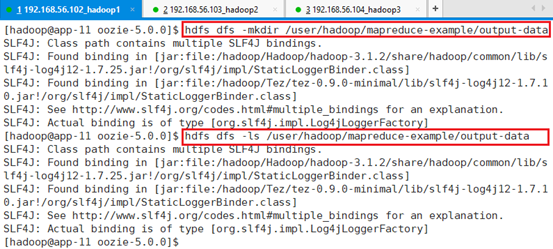
13.4.6.3 测试
提交执行:
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/mapreduce-example/apps/map-reduce/job.properties -run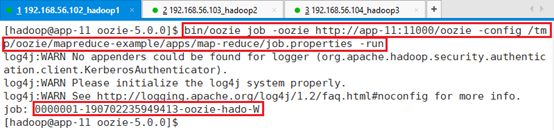
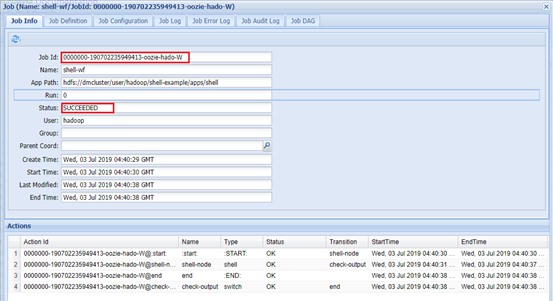
Web查看:
正在执行:

执行完成:
登录app-12:8088,并查看stdout日志
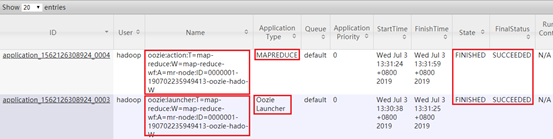

本机查看执行结果
hdfs dfs -ls /user/hadoop/mapreduce-example/output-data/map-reduce
查看日志:
hdfs dfs -cat /user/hadoop/mapreduce-example/output-data/map-reduce/part-00000每行字符个数,后续一次递加。

13.4.7 Spark Action
基于spark2用java编写的action。
13.4.7.1 源文件
资源文件中,提供spark执行程序和库

资源文件程序代码

job.properties提供的内容和之前例子类似,参考前面描述,同时指定运行内容,driver内存。
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=spark-example
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/spark
oozie.action.sharelib.for.spark=spark2
#sparkopts=--executor-memory 128M --total-executor-cores 2 --driver-memory 256M --conf spark.yarn.jar=hdfs://hdp-master:8020/system/spark/lib/spark-assembly-1.4.1-hadoop2.6.0.jar --conf spark.yarn.historyServer.address=http://hdp-master:18088 --conf spark.eventLog.dir=hdfs://hdp-master:8020/user/spark/applicationHistory --conf spark.eventLog.enabled=true
# don't include ""
sparkopts=--executor-memory 1g --total-executor-cores 1 --driver-memory 2g
master=yarn-clusterworkflow.xml执行class文件,在Lib文件夹里。
<workflow-app xmlns='uri:oozie:workflow:1.0' name='SparkFileCopy'>
<start to='spark-node' />
<action name='spark-node'>
<spark xmlns="uri:oozie:spark-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<master>${master}</master>
<name>SparkPi</name>
<class>org.apache.spark.examples.SparkPi</class>
<jar>${nameNode}/user/${wf:user()}/${examplesRoot}/apps/spark/lib/spark-examples_2.11-2.4.0.jar</jar>
<spark-opts>${sparkopts}</spark-opts>
<!--<arg>${nameNode}/user/${wf:user()}/${examplesRoot}/input-data/text/data.txt</arg>-->
<!--<arg>${nameNode}/user/${wf:user()}/${examplesRoot}/output-data/spark</arg>-->
</spark>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Workflow failed, error
message[${wf:errorMessage(wf:lastErrorNode())}]
</message>
</kill>
<end name='end' />
</workflow-app>13.4.7.2 上传HDFS
上传代码spark-example
hdfs dfs -copyFromLocal /tmp/oozie/spark-example /user/hadoop/
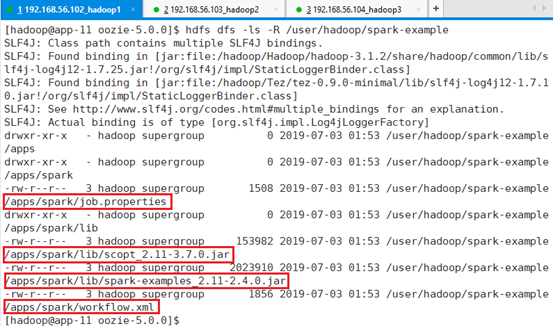
确认:hdfs dfs -ls -R /user/hadoop/spark-example
13.4.7.3 测试
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/spark-example/apps/spark/job.properties -run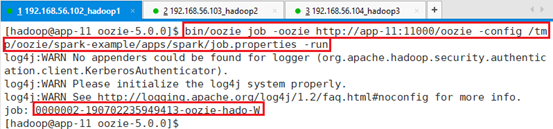
Web页面查看:app-11:11000
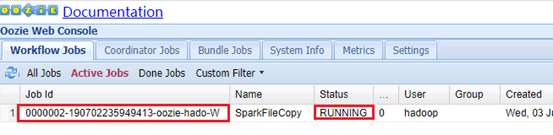
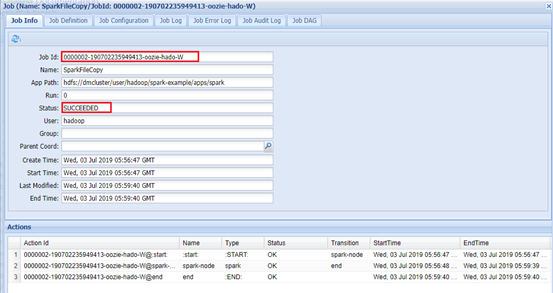
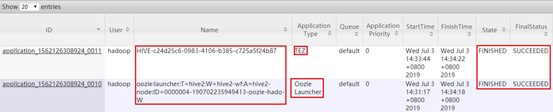
Hadoop集群查看:app-12:8088
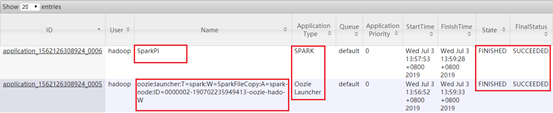
SparkPi中显示具体执行过程,包括启动AM,申请Container,以及运行结果。
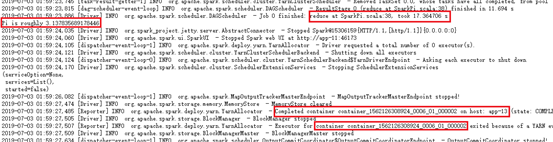
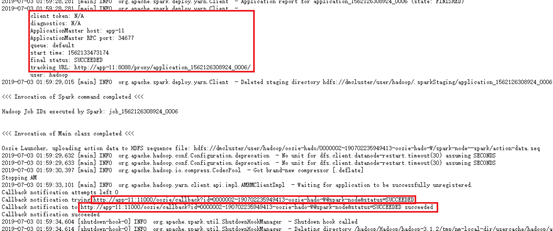
13.4.8 PySpark Action
13.4.8.1 源文件
资源文件中的代码文件pi.py,Python写的计算pi的代码。

import sys
from random import random
from operator import add
from pyspark import SparkContext
if __name__ == "__main__":
"""
Usage: pi [partitions]
"""
sc = SparkContext(appName="Python-Spark-Pi")
partitions = int(sys.argv[1]) if len(sys.argv) > 1 else 2
n = 100000 * partitions
def f(_):
x = random() * 2 - 1
y = random() * 2 - 1
return 1 if x ** 2 + y ** 2 < 1 else 0
count = sc.parallelize(range(1, n + 1), partitions).map(f).reduce(add)
print("Pi is roughly %f" % (4.0 * count / n))
sc.stop()资源文件

job.properties提供的内容和之前例子类似,参考前面描述,同时指定运行内容,driver内存,定义Python执行命令的位置,因为使用了python3,用的是ANACONDA,所以需要制定ANACONDA_HOME路径。
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=spark-example-pi
oozie.use.system.libpath=true
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/pyspark
oozie.action.sharelib.for.spark=spark2
sparkopts=--executor-memory 1g --total-executor-cores 1 --driver-memory 2g
master=yarn-cluster
ANACONDA_HOME=/hadoop/Anaconda/Anaconda3-2018.12-Linux-x86_64workflow.xml执行class文件,在Lib文件夹里。
<workflow-app xmlns='uri:oozie:workflow:1.0' name='SparkPythonPi'>
<start to='spark-node' />
<action name='spark-node'>
<spark xmlns="uri:oozie:spark-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<master>${master}</master>
<name>Python-Spark-Pi</name>
<jar>pi.py</jar>
<spark-opts>${sparkopts} --conf spark.yarn.appMasterEnv.PYSPARK_PYTHON=${ANACONDA_HOME}/bin/python --conf spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON=${ANACONDA_HOME}/bin/python</spark-opts>
</spark>
<ok to="end" />
<error to="fail" />
</action>
<kill name="fail">
<message>Workflow failed, error message [${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name='end' />
</workflow-app>13.4.8.2 上传HDFS
上传代码spark-example-pi:
hdfs dfs -copyFromLocal /tmp/oozie/spark-example-pi /user/hadoop/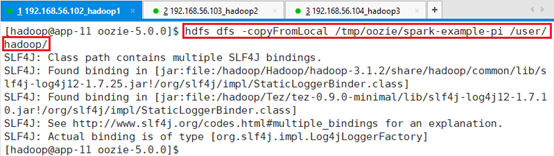
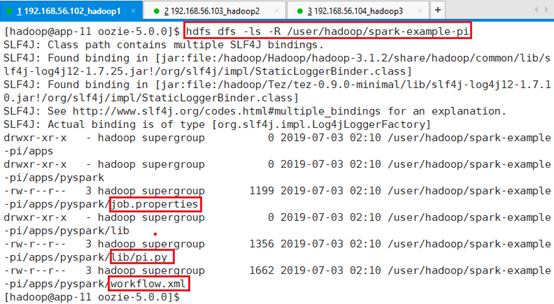
确认:hdfs dfs -ls -R /user/hadoop/spark-example-pi
13.4.8.3 测试
- 运行:
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/spark-example-pi/apps/pyspark/job.properties -run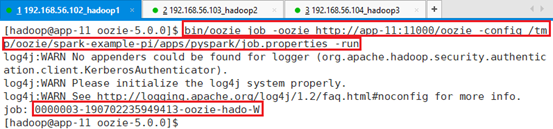
Web页面查看:app-11:11000
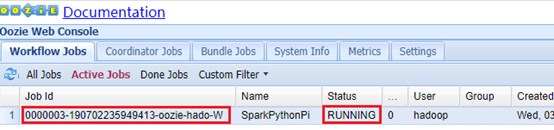
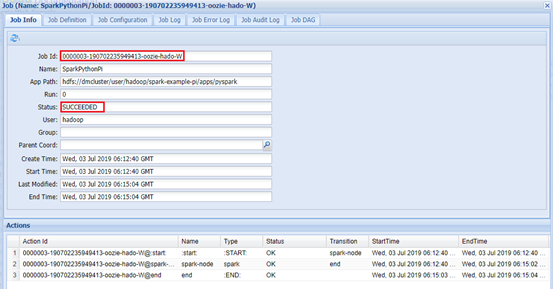
Hadoop集群查看:app-12:8088

Python-Spark-Pi中显示具体执行过程,包括启动AM,申请Container,以及运行结果。


13.4.9 Hive2 Action
Hive分为hive和hive2,这个并不是代表版本。Hive是指通过metastore方式解析提交集群,需要借助hive的Jar包和规范等。Hive2可以让hive master完成工作,而oozie只是负责任务的调度和提交工作。Hive2代表一个主流的方式,可以减少和hive的更多耦合工作,耦合越小,整个架构体系才能够更健壮。
13.4.9.1 源文件
文件代码位于
job.properties,通过jdbc访问server,访问test库
nameNode=hdfs://dmcluster
resourceManager=rm1,rm2
queueName=default
examplesRoot=hive2-example
oozie.use.system.libpath=true
jdbcURL=jdbc:hive2://app-12:10000/test
oozie.wf.application.path=${nameNode}/user/${user.name}/${examplesRoot}/apps/hive2
master=yarn-clusterworkflow.xml定义库位置和执行文件。
<workflow-app xmlns="uri:oozie:workflow:1.0" name="hive2-wf">
<start to="hive2-node"/>
<action name="hive2-node">
<hive2 xmlns="uri:oozie:hive2-action:1.0">
<resource-manager>${resourceManager}</resource-manager>
<name-node>${nameNode}</name-node>
<configuration>
<property>
<name>mapred.job.queue.name</name>
<value>${queueName}</value>
</property>
</configuration>
<jdbc-url>${jdbcURL}</jdbc-url>
<script>script.q</script>
</hive2>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Hive2 (Beeline) action failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
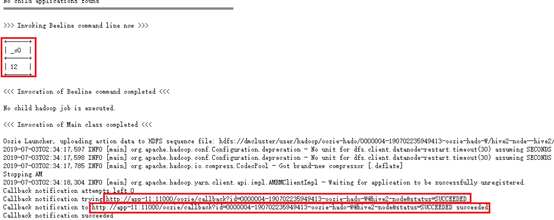
</workflow-app>script.q所需要做的操作
set mapreduce.reduce.memory.mb=2048;
set mapreduce.map.memory.mb=2048;
SELECT count(*) FROM employee;由于Hive安装在app-12,用ssh 登录app-12,切换到hadoop用户。
由于启动集群过程中会启动hive:cat /hadoop/startAll.sh
./hive --service metastore
./hive --service hiveserver2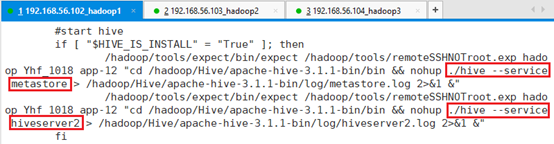
确认端口启动:netstat -tnl
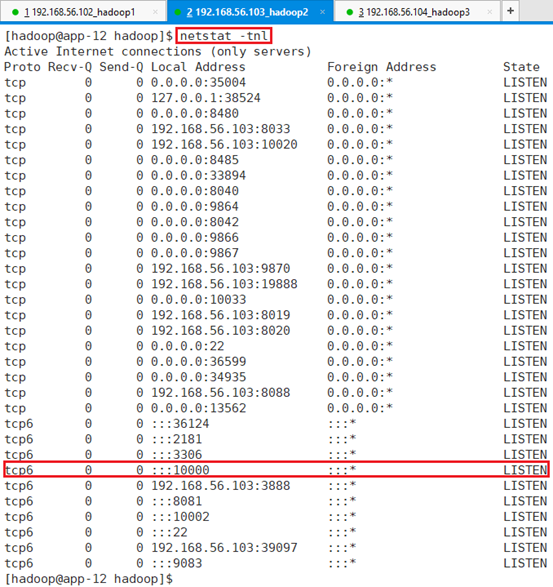
13.4.9.2 上传HDFS
上传代码hive2-example:
hdfs dfs -copyFromLocal /tmp/oozie/hive2-example /user/hadoop/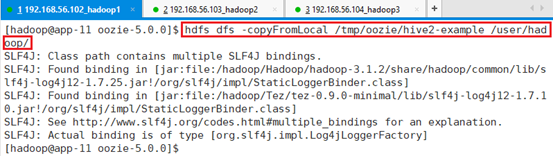
确认:hdfs dfs -ls -R /user/hadoop/hive2-example
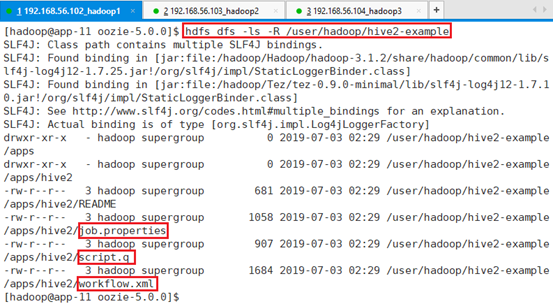
13.4.9.3 测试
运行:
bin/oozie job -oozie http://app-11:11000/oozie -config /tmp/oozie/hive2-example/apps/hive2/job.properties -run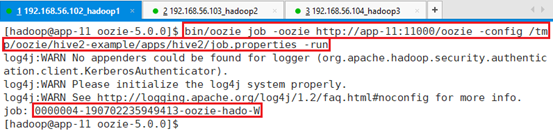
Web页面查看:app-11:11000
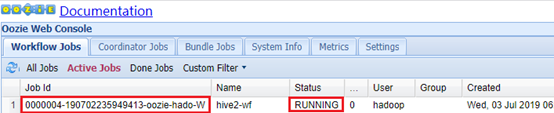
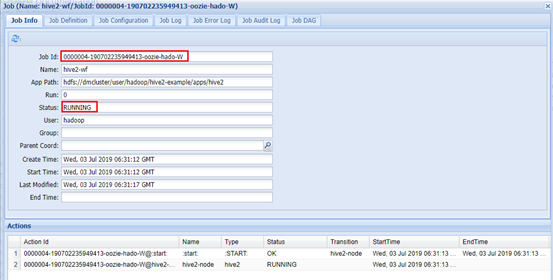
Hadoop集群查看:app-12:8088
13.5 总结
Oozie技术难点:
- Sharelib的创建,很难去通过对应版本号编译出来,需要通过对相关框架的理解自己创建sharelib。
- 每种action的执行机制,参考资源文件提供的案例,自己进行修改试验,action如何调度执行,在执行过程中了解机制。