完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
十二、Spark数据统计与可视化
RDD数据类型只有数据,不定义字段名及其数据类型,所以只能使用索引位置指定每一个字段,RDD代码开发需要开发人员具有Map/Reduce概念。
DataFrame创建时,需要定义每一个字段名和数据类型,可以基于字段名进行统计,另外DataFrame API已经定义了如select()、groupby()、count()等类似SQL的方法便于统计。
Spark SQL由DataFrame派生,使用Spark SQL前必须先创建DataFrame,SparkSQL使用简单,只需要懂SQL语句即可。
12.1 准备
12.1.1 启动集群
使用ssh连接到节点app-11,切换到hadoop用户,启动集群。

12.1.2 数据准备
12.1.2.1 u.user
被部分用到的数据为《Spark推荐引擎构建》章节中已经上传的数据。
确认:hdfs dfs -ls -R /user/movieslens/data
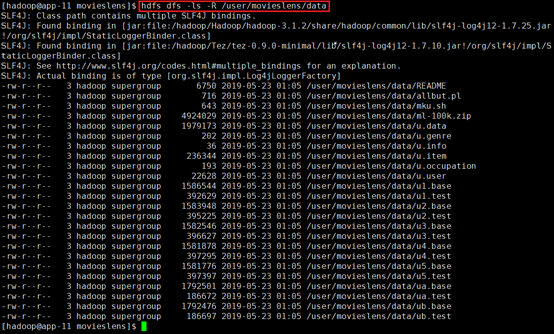
12.1.2.2 zipcode
下载文件free-zipcode-database-Primary.csv
http://federalgovernmentzipcodes.us/free-zipcode-database-Primary.csv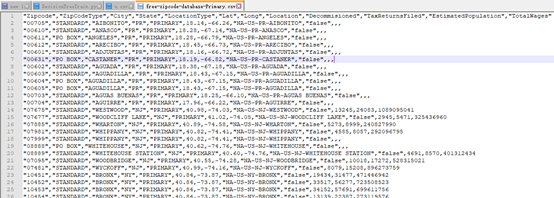
将文件上传到HDFS目录/user/movieslens/data/
hadoop dfs -copyFromLocal -f /tmp/mls/free-zipcode-database-Primary.csv /user/movieslens/data/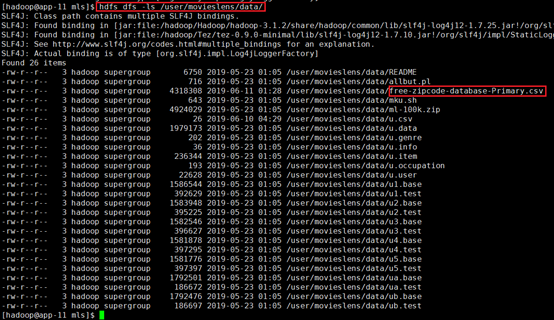
12.2 新建项目
在web页面输入http://app-11:8888,并输入密码,进入jupyter。
新建python3项目:SparkDataType

重命名为SparkDataType
创建成功后

12.3 创建SparkSession
引入findspark,支持PySpark
import findspark
findspark.init()引入SparkContext、SparkConf、SparkSession,其中SparkSession内部封装了SparkConf、SparkContext、SQLContext、HiveContext。可以使用sparkSession.sparkContext获取SparkContext,
from pyspark import SparkContext
from pyspark import SparkConf
from pyspark.sql import SparkSession创建SparkSession
sparkSession = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.master("spark://app-11:7077") \
.enableHiveSupport() \
.getOrCreate()如果仅仅创建SparkContext:
sc = SparkContext("spark://app-11:7077","movieslens")也可以用如下方法创建SparkSession,这个可以直接操作已经建好的Hive表
warehouse_location = abspath('/user/hive/warehouse')
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.config("spark.sql.warehouse.dir", warehouse_location) \
.master("spark://app-11:7077") \
.enableHiveSupport() \
.getOrCreate()设置路径,前面上传到hdfs的路径位置
global Path
Path="hdfs://dmcluster/user/movieslens/"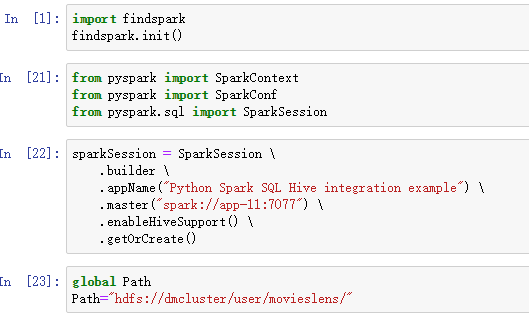
12.4 创建类型
读取文件u.user数据。注意可以使用sparkSession.sparkContext获取SparkContext,使用
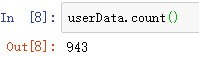
userData=sparkSession.sparkContext.textFile(Path+"data/u.user")查看数据数量:userData.count()
查看数据前5项:userData.take(5)
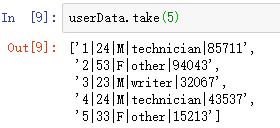
12.4.1 RDD
userData数据每行用“|”符号分隔,可以使用map处理每一行数据,针对每一行使用split(“|”)分隔每一行数据的所有字段。
userRDD=userData.map(lambda line:line.split("|"))查看前5项:userRDD.take(5)
可以看出将每行分成了5个字段,其中第三个字段表示性别。

12.4.2 DataFrame
12.4.2.1 基于RDD
12.4.2.1.1 无字段名和类型
toDF
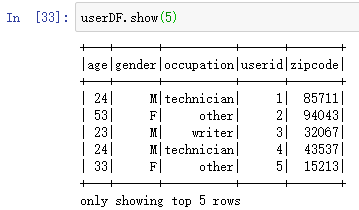
转换为DataFrame:userDF=userRDD.toDF()
显示前5行:userDF.show(5)
由于没有设置字段名和类型,所以使用默认_1_2_3_4_5

createDataFrame
转换为DataFrame:userDF=sparkSession.createDataFrame(userRows)
显示前5行:userDF.show(5)
由于没有设置字段名和类型,所以使用默认_1_2_3_4_5
12.4.2.1.2 有字段名和类型
此处基于RRD创建DataFrame。
引入Row:from pyspark.sql import Row
使用map定义每一行的字段与数据类型
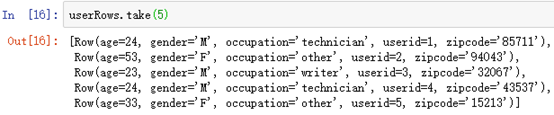
userRows=userRDD.map(lambda p:Row(userid=int(p[0]), age=int(p[1]), gender=p[2], occupation=p[3], zipcode=p[4]))显示前5行:userRows.take(5)
toDF
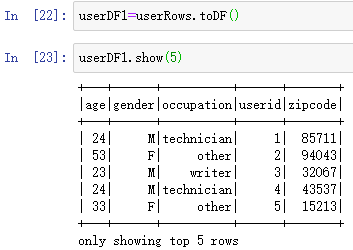
转换为DataFrame:userDF1=userRows.toDF()
查看前5项:userDF1.show(5)
createDataFrame
创建DataFrame:userDF=sparkSession.createDataFrame(userRows)
显示前5行:userDF.show(5)
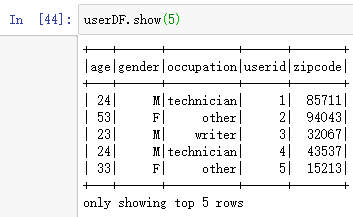
显示类型:userDF.printSchema()

12.4.2.2 直接读取文件CSV/JSON
SparkSession内置了CSV和JSON的解析器,可以直接读取,格式为:
sparkSession.read
.option("header", "true") // 文件路径 ,默认为false,没有表头
.csv("u.csv")对于非CSV文件,
sparkSession.read
.format("csv")//指定为csv格式
.option("header", "true") // 文件路径 ,默认为false,没有表头
.option("header", "\t")//不是CSV文件,但是格式类型,仅仅只是用\t而非逗号分割
.load("u.txt")直接读取CSV文件,由于CSV文件第一行为字段名,所以设置为true
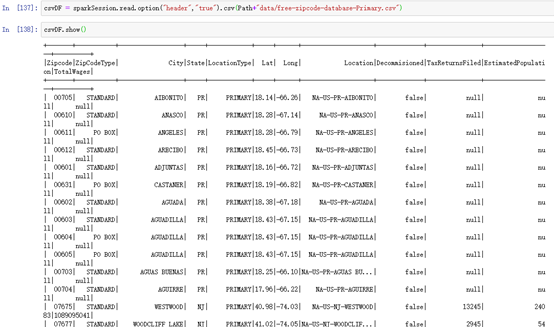
csvDF = sparkSession.read.option("header","true").csv(Path+"data/free-zipcode-database-Primary.csv")显示:csvDF.show()
12.4.3 SparkSQL
12.4.3.1 基于DataFrame
创建临时表user_table:
userDF.registerTempTable("user_table")使用sparksql操作表:
sparkSession.sql("select count(*) counts from user_table").show()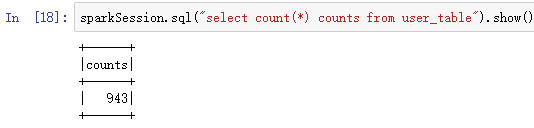
显示表数据:
sparkSession.sql("select * from user_table").show()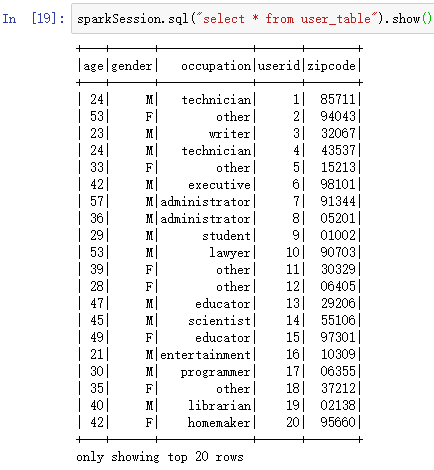
显示表前5行数据,都取出,但是只显示前5行“
sparkSession.sql("select * from user_table").show(5)
显示表前5行数据,只取前5行:
sparkSession.sql("select * from user_table limit 5").show()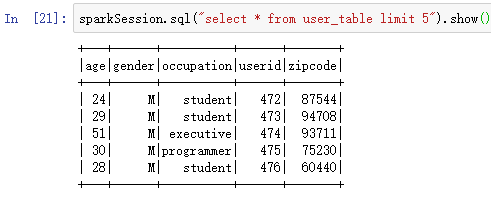
12.4.3.2 基于Hive表
参考章节《Spark推荐引擎构建案例》,主要步骤如下
按之前Hive章节的方式创建数据库和表
默认数据库位置位于:warehouse_location = abspath(‘/user/hive/warehouse’)
创建SparkSession,写入数据库位置
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.config("spark.sql.warehouse.dir", warehouse_location) \
.master("spark://app-11:7077") \
.enableHiveSupport() \
.getOrCreate()直接用spark.sql操作表
rawData=spark.sql("select userid, movieid, score from movies.data")
rawData.show()12.5 获取指定字段
以获取u.user文件中第0,3,2个字段为例。
12.5.1 RDD
由于RDD没有字段名和字段类型,只能通过字段索引位置来获取,通过map处理每一项数据,且使用lambda创建匿名函数,传入x作为参数,获取指定列,从而产生一个新的RDD。
userRDDSelect=userRDD.map(lambda x:(x[0],x[3],x[2]))显示前5行:userRDDSelect.take(5)

12.5.2 DataFrame
由于DataFrame定义了字段类型和字段名,那么获取DataFrame指定字段时,可以通过多种方式。
通过字段名获取:
userDF.select("userid","occupation","gender").show(5)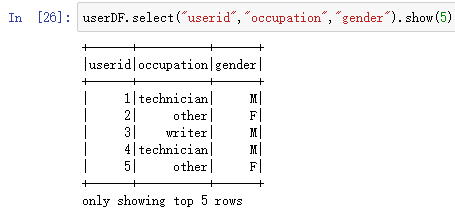
还可以通过DataFrame.字段名获取:
userDF.select(userDF.userid,userDF.occupation,userDF.gender).show(5)
使用[]进行查询:
userDF[userDF["userid"],userDF["occupation"],userDF["gender"]].show(5)
还可以通过索引位置[]查询,注意这个位置和RDD的位置可能不一样,需要查看userDF对应的位置:
userDF[userDF[3],userDF[2],userDF[1]].show(5)
12.5.3 SparkSQL
直接使用SQL语句查看即可:
sparkSession.sql("select userid,occupation,gender from user_table").show(5)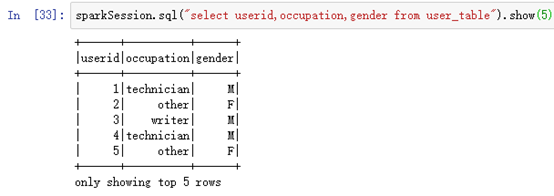
12.6 计算
有些字段需要通过计算显示,比如出生年份,通过年龄可以计算出出生年份。
12.6.1 RDD
通过索引获取值,然后进行计算:
userRDDCal=userRDD.map(lambda x:(x[0],x[3],x[2],x[1],2019-int(x[1])))显示前5行:userRDDCal.take(5)

12.6.2 DataFrame
基于字段名,直接进行计算:
userDF.select("userid","occupation","gender","age",2019-userDF.age).show(5)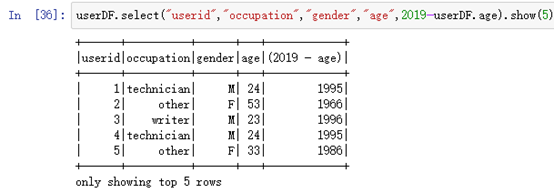
还可以给列字段直接取名,使用alias:
userDF.select("userid","occupation","gender","age",(2019-userDF.age).alias("birthyear")).show(5)
12.6.3 SparkSQL
使用SQL语句别名:
sparkSession.sql("select userid,occupation,gender,age,2019-age birthyear from user_table").show(5)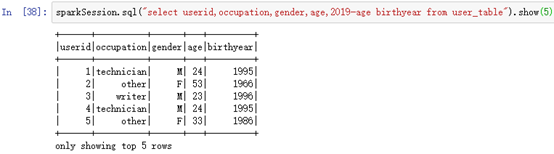
12.7 条件查询
筛选符合条件的行
12.7.1 RDD
使用filter进行过滤:
userRDDFilter = userRDD.filter(lambda x:x[3]=='technician' and x[2]=='M')显示前5行:userRDDFilter.take(5)

12.7.2 DataFrame
多个filter进行筛选,类型and操作:
userDF.filter("occupation='technician'").filter("gender='M'").show(5)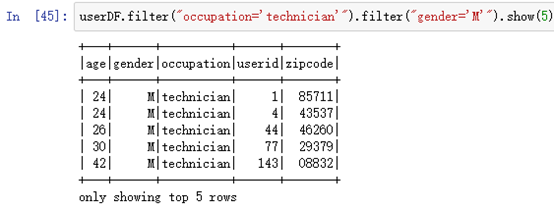
使用and操作:
userDF.filter((userDF.occupation=='technician')&(userDF.gender=='M')).show(5)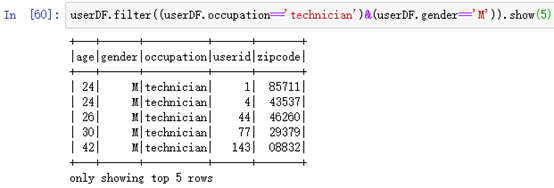
使用or操作:
userDF.filter((userDF.occupation=='technician')|(userDF.gender=='M')).show(5)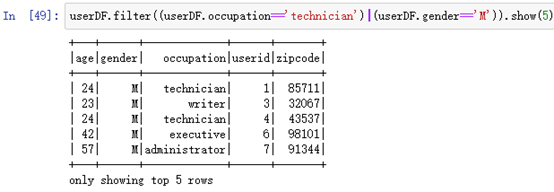
使用not操作:
userDF.filter((userDF.occupation=='technician')&(userDF.gender.isin(['F']))).show(5)
还可以使用[]指定条件:
userDF.filter((userDF['occupation']=='technician')|(userDF['gender']=='M')).show(5)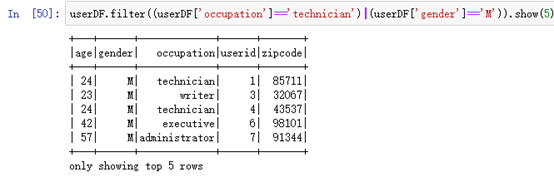
12.7.3 SparkSQL
直接使用SQL语句操作:
sparkSession.sql("select * from user_table where occupation='technician' and gender='M'").show(5)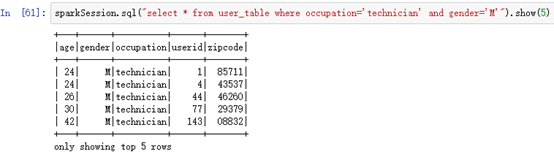
sparkSession.sql("select * from user_table where occupation='technician' and gender='F'").show(5)
12.8 单个字段排序
比如按年龄字段进行排序。
12.8.1 RDD
使用RDD.takeOrdered(需要显示的项数,key=lambda语句设置排序的字段)
对年龄按升序排序:
userRDD.takeOrdered(5,key=lambda x:int(x[1]))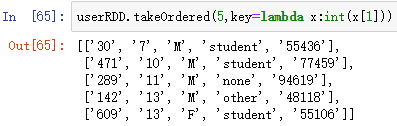
对年龄按降序排序:
userRDD.takeOrdered(5,key=lambda x:-1*int(x[1]))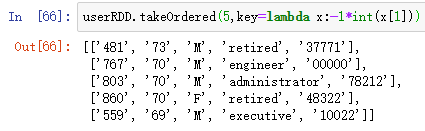
12.8.2 DataFrame
使用DataFrame.orderBy进行排序
按年龄升序排序:
userDF.select("userid","occupation","gender","age").orderBy("age").show(5)
userDF.select("userid","occupation","gender","age").orderBy(userDF.age).show(5)
userDF.select("userid","occupation","gender","age").orderBy(userDF["age"]).show(5)
按年龄降序排序:
userDF.select("userid","occupation","gender","age").orderBy("age",ascending=0).show(5)
userDF.select("userid","occupation","gender","age").orderBy(userDF.age.desc()).show(5)
userDF.select("userid","occupation","gender","age").orderBy(userDF["age"].desc()).show(5)
12.8.3 SparkSQL
按年龄升序排序order by age asc:
sparkSession.sql("select * from user_table order by age asc").show(5)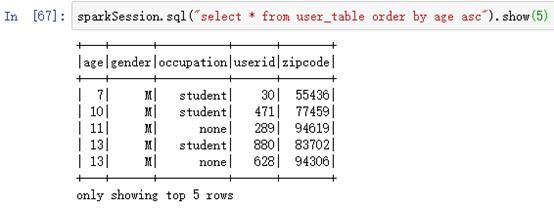
按年龄降序排序order by age desc:
sparkSession.sql("select * from user_table order by age desc").show(5)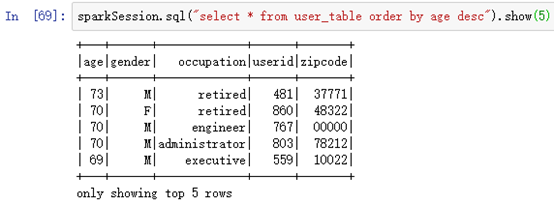
12.9 多个字段排序
12.9.1 RDD
如按age降序、occupation升序排序:
userRDD.takeOrdered(10,key=lambda x:(-int(x[1]), x[3]))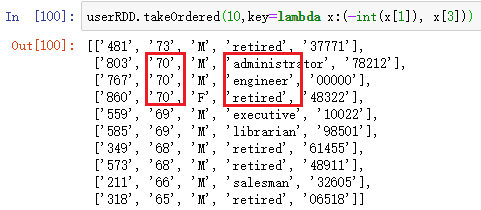
12.9.2 DataFrame
orderBy,第一个参数为要排序的字段,第二个参数为排序顺序,0表示降序,1表示升序
userDF.select("userid","occupation","gender","age").orderBy(["age","occupation"],ascending=[0,1]).show(10)
orderBy,使用DataFrame.字段名:
userDF.select("userid","occupation","gender","age").orderBy(userDF.age.desc(), userDF.occupation.asc()).show(10)
orderBy,使用DataFrame[“字段名”]:
userDF.select("userid","occupation","gender","age").orderBy(userDF["age"].desc(), userDF["occupation"].asc()).show(10)
12.9.3 SparkSQL
对应SQL语句即可:
sparkSession.sql("select * from user_table order by age desc,occupation asc").show(10)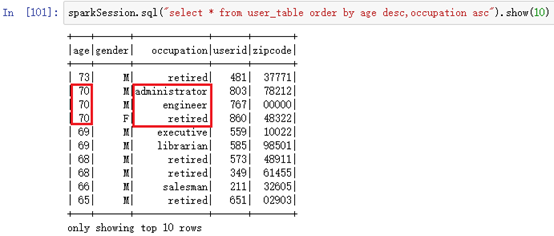
12.10 去除重复数据
12.10.1 RDD
筛选出不重复的数据,然后转换为List:
userRDD.map(lambda x:x[3]).distinct().collect()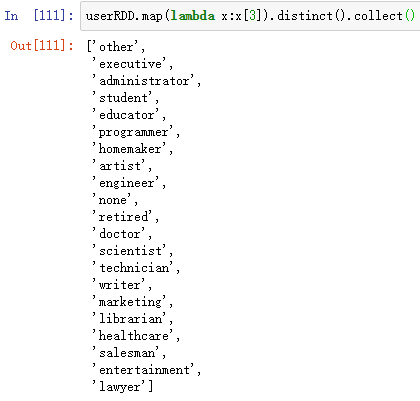
userRDD.map(lambda x:x[3]).distinct().take(5)
组合数据不重复,比如年龄和职业:
userRDD.map(lambda x:(x[1],x[3])).distinct().take(20)
12.10.2 DataFrame
职业不重复:
userDF.select("occupation").distinct().show()
还可以:
userDF.select(userDF.occupation).distinct().show()
userDF.select(userDF["occupation"]).distinct().show()年龄和职业组合不重复:
userDF.select("age","occupation").distinct().show()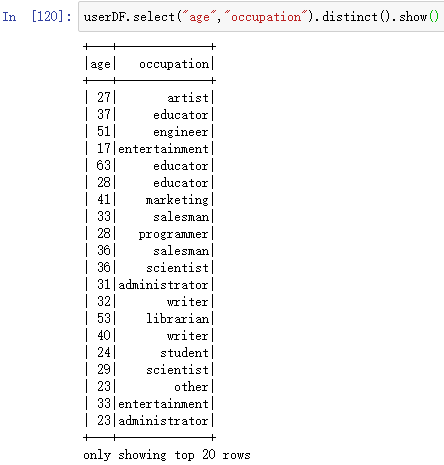
还可以:
userDF.select(userDF.age,userDF.occupation).distinct().show()
userDF.select(userDF["age"],userDF["occupation"]).distinct().show()12.10.3 SparkSQL
职业不重复:
sparkSession.sql("select distinct occupation from user_table").show()
年龄和职业组合的不重复:
sparkSession.sql("select distinct age,occupation from user_table").show()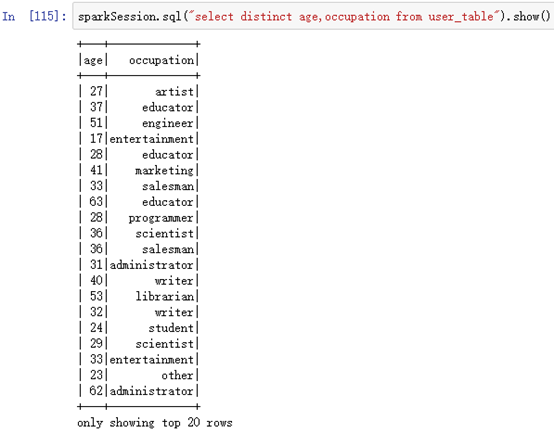
12.11 分组统计
对一个或多个字段进行分组统计。
12.11.1 RDD
RDD中分组统计需要借助map/reduce操作。
统计每一个职业有多少人,先通过Map函数,经每处理的一个职业标记为1,然后通过reduce函数计算总和并统计
userRDD.map(lambda x:(x[3],1)).reduceByKey(lambda x,y:x+y).collect()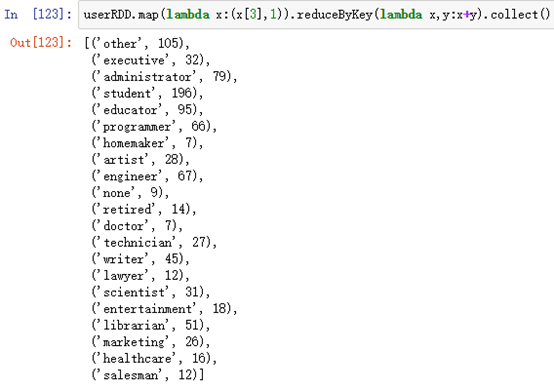
进一步统计每个职业,对应各个性别人数:
userRDD.map(lambda x:((x[2],x[3]),1)).reduceByKey(lambda x,y:x+y).collect()
12.11.2 DataFrame
按职业进行统计:
userDF.select("occupation").groupby("occupation").count().show()
职业和性别结合统计:
userDF.select("gender","occupation").groupby("gender","occupation").count().show()
对于两个组合的统计,DataFrame提供了更简单的办法,crosstab计算给定列的成对频率表
userDF.stat.crosstab("gender","occupation").show()
行列换一下,这样看起来就清楚了:
userDF.stat.crosstab("occupation","gender").show()
12.11.3 SparkSQL
按职业进行统计:
sparkSession.sql("select occupation,count(*) counts from user_table group by occupation").show()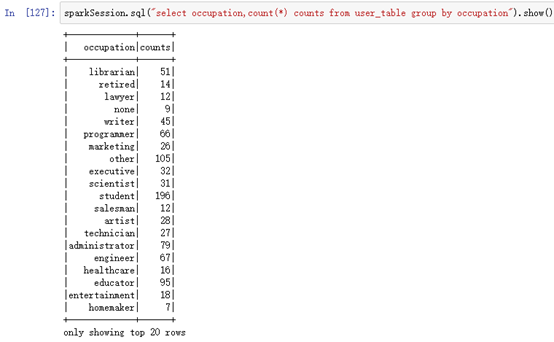
按职业和性别进行统计:
sparkSession.sql("select gender,occupation,count(*) counts from user_table group by gender,occupation").show()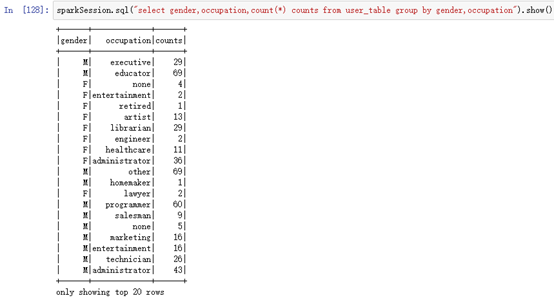
12.12 连接join
12.12.1 读取zipcode并整理
读取文件,注可以直接将csv读取到DataFrame,但是此处由于需要测试RDD,所以不直接读取到DataFrame。
zipcodeData=sparkSession.sparkContext.textFile(Path+"data/free-zipcode-database-Primary.csv")查看前5行:zipcodeData.take(5)

查看第一行:
zipcodeHeader=zipcodeData.first()
zipcodeHeader
去除第一行:
zipcodeData=zipcodeData.filter(lambda x:x!=zipcodeHeader)
zipcodeData.first()
去除双引号:
zipcodeData=zipcodeData.map(lambda x:x.replace("\"",""))
zipcodeData.first()
将行按,切分:
zipcodeRDD=zipcodeData.map(lambda x:x.split(","))
zipcodeRDD.first()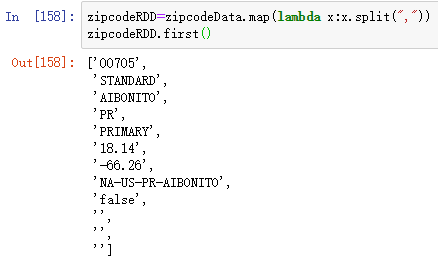
设定字段名和类型:
zipcodeRow=zipcodeRDD.map(lambda x:Row(zipcode=int(x[0]), zipCodeType=x[1],city=x[2],state=x[3]))
zipcodeRow.take(5)
转换为DataFrame:
zipcodeDF=sparkSession.createDataFrame(zipcodeRow)
zipcodeDF.show(5)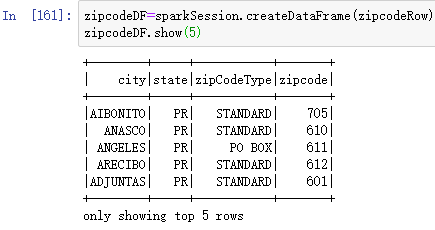
创建临时表:
zipcodeDF.registerTempTable("zipcode_table")
zipcodeDF.show(5)
12.12.2 DataFrame
将两个DataFrame联合产生一个新的DataFrame
joinDF=userDF.join(zipcodeDF,userDF.zipcode==zipcodeDF.zipcode,"left_outer")
joinDF.printSchema()
类型包括:”left_outer” “right_outer” “full_outer” “inner”四种
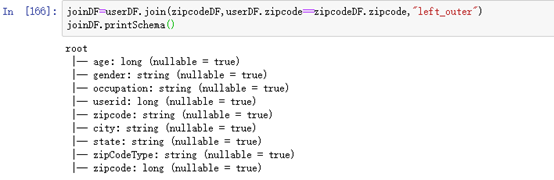
显示前10行:joinDF.show(10)
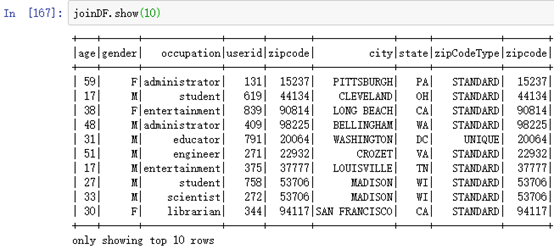
使用filter过滤:joinDF.filter(“state=’NY'”).show(10)
统计州人数:
joinDF.groupBy("state").count().show(100)
12.12.3 SparkSQL
将user_table和zipcode_table表联合查询:
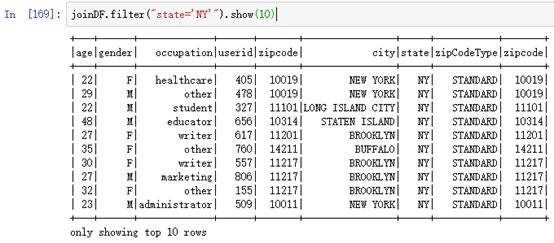
sparkSession.sql("select u.*, z.city, z.state from user_table u left join zipcode_table z on u.zipcode=z.zipcode").show(10)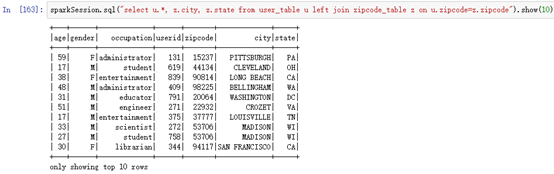
按州统计用户数:
sparkSession.sql("select z.state,count(*) from user_table u left join zipcode_table z on u.zipcode=z.zipcode group by z.state").show(100)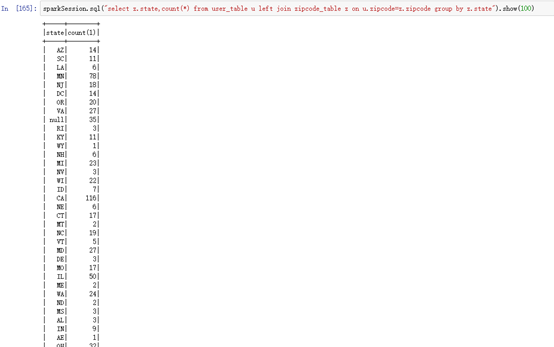
12.13 pandas绘图
12.13.1 DataFrame
按照州人数统计直方图:
stateStatistic=joinDF.groupBy("state").count()
statePandas=stateStatistic.toPandas().set_index("state")
statePandas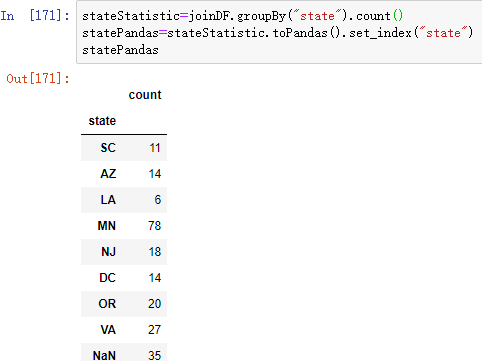
绘制:
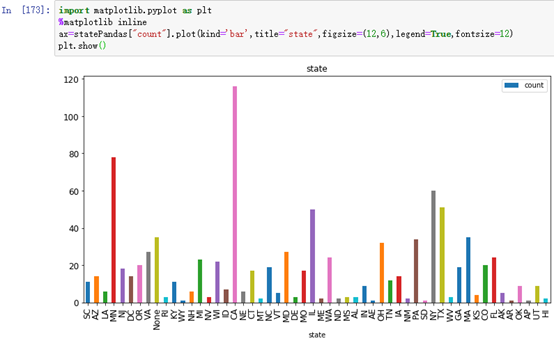
import matplotlib.pyplot as plt
%matplotlib inline
ax=statePandas["count"].plot(kind='bar',title="state",figsize=(12,6),legend=True,fontsize=12)
plt.show()将图形显示在Ipython Notebook中
绘制的是计算总和,直方图,标题为state,大小为(12,6),字号为12
绘图并显示
12.13.2 SparkSQL
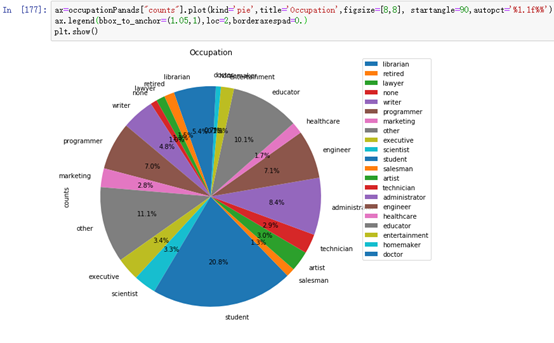
按照每个职业人数统计,并以圆饼图形式展示。
occupationStatistic=sparkSession.sql("select occupation,count(*) counts from user_table group by occupation")
occupationStatistic.show()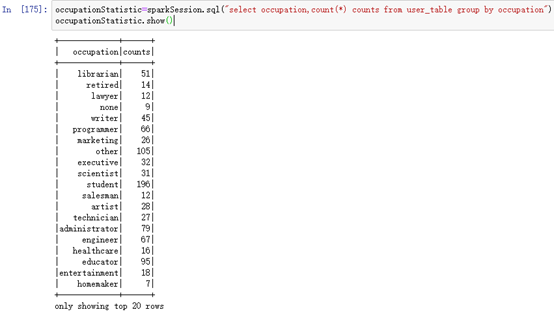
转换为pandas:
occupationPanads=occupationStatistic.toPandas().set_index("occupation")
occupationPanads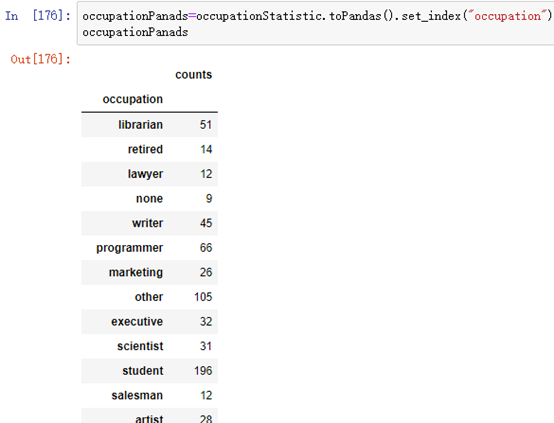
绘制圆饼图:
ax=occupationPanads["counts"].plot(kind='pie',title='Occupation',figsize=[8,8], startangle=90,autopct='%1.1f%%')
ax.legend(bbox_to_anchor=(1.05,1),loc=2,borderaxespad=0.)
plt.show()显示圆饼图的显示autopct=’%1.1f%%’
图例显示在右边: