完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
十、Spark Structured Streaming API
本部分开始流处理,之前介绍过Spark将流处理有Spark Streming迁移到Spark Structured Streaming这种API,因为新的技术、观念引入到流处理之中,响应的Spark做了架构上的重新架构,Structured Streaming就是基于这种背景下产生的。
就像之前说的,不好说是Spark学习了Flink,还是Flink学习了Spark,现在这种流处理的理论或者观念已经发展到了这一步,因此流处理的应用将要做相应的改变,特别是架构层的改变。
10.1 什么是流、动态表
通常将一个没有开始或结束点的数据集称之为数据流stream,它的最基本特点就是没有界限,没有边界产生的最重要问题就是不知道所需的数据什么时候到达,或者说数据可能是乱序的。带来的本质变化和问题,就是如何处理乱序,为了使用SQL语句以及SQL语句所代表的关系型代数去处理我们的Data Stream,需要进行一个理论上的对应和创新。
在前面讲的数据处理是基于做Map或者Reduce,这些数据处理相当于是做一次变化,可以定义相应的变化函数。在关系型代数里面是基于表的,一个DataSet即有限的数据集,对应成表很容易理解,在前面的例子中,淘宝数据集可以体会到,一个完整的数据集定义成表容易理解。但是将这种建立在表上的关系型代数移植到DataStream上则很难理解,因为DatasStream处理的对象是无限延伸的,而且时间轴上动态变化的数据集。
而流式代数理论是建立在数据库的基础上,所以说这两者本质不同,一个执行机制不同,因为根据CAP理论可用性是有限时间要求的,不能一个数据库查询SELECT需要等一个小时、一天甚至都不知道多长时间,无法事先知道查询将要花费多长时间,这种未知的事情是CAP理论所不允许的,或者说是相违背的,所以说关系型数据库必须及时响应我们的查询,而且所有的数据对查询是可见的。流处理就不一样,比如说一个页面的点击流,页面登陆后,怎么知道什么时间点,主页按钮会被点,购买按钮会被点,没法预测用户行为,所以说是没有时间节点的,而且是没有预期的时间节点。并且流处理一直在执行,因为数据源是没有尽头的,数据处理程序是一直在执行的,而我们的批处理程序是有时间结束点的,只要CPU和RAM能达到调度执行要求,那么程序是可以在预期时间内完成的,流处理程序是没有完成时间点的。
所以引申出动态表的概念UnbounderTable,之所以叫动态表,是因为要想和关系型表做对应,同时表和之前的表还不一样,这种表的内容动态变化。如图,因为新的数据进来,表的行时刻变化,而且不知道什么时间增加什么样的行,有可能同一行的数据会产生一些本质上的不同。对此,DataStream做计算有可能会算错,因为结果是可能随时间变化的,如在表里面某个值有可能在10点是一个数,在11点是另一个数。和传统关系数据库理论是不一样的,传统的关系型数据库一个key如果在index约束情况下对应的value即使变化,最终也是一个值,而动态表有可能一条记录会出现多种值的情况。

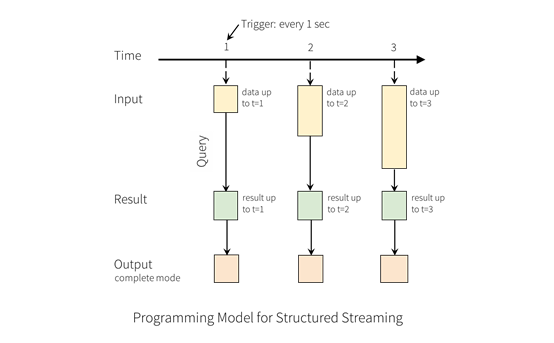
10.2 Streaming WordCount原理
以一个WordCount为例,如图,比如有一个DataStream,是一个个的单词,每秒触发一次,计算每分钟之内WordCount的值。将每分钟内的单词都集合在一起,然后做一次查询,生成一次查询结果,但是由于每分钟做一次查询,两个之间可能会产生重叠,重叠区间总数会出现两次,这个例子只对本窗口有效的结果,每分钟统计一次。
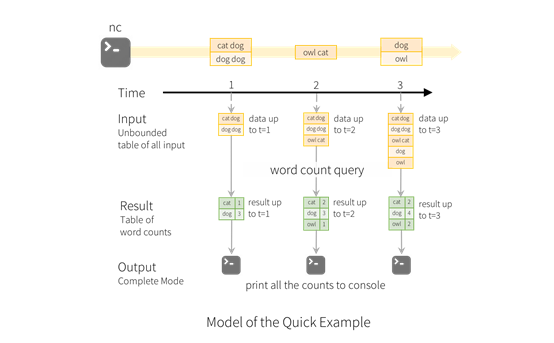
如图是针对前面例子的一个具体的实施,比如一分钟内收到了cat dog、dog dog两行的字符串,将对应的单词统计出来,分别是1和3。由于前一个窗口期内统计了dog值为3,下一个窗口期,仍然将dog统计为3,是因为要继承前一个窗口的结果,这就是流处理做动态查询或者动态表的主要原因,而且在最后一个窗口期,将dog值改为4。
关于动态表的形式有多种形式,第一种形式是append,如之前是3,可以接着增加一条dog为1的数据;第二种形式是将dog的值为3的发一个召回的项,dog先减去3,再赋值为4。
10.3 时间与窗口
时间和窗口是流处理两个最核心的概念,理解起来不是那么容易的。
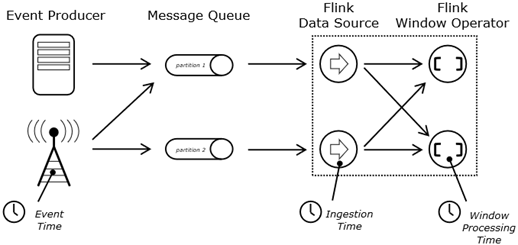
流处理的时间分为三类:一类是事件时间;第二类是观察时间;第三类是窗口处理时间。通常我们只关注事件时间和处理时间。如图,比如我们向微信发送了一个信息,需要经过链路到达微信公司后台,这个是有时间差的,而且和多个人聊天,这些信息的顺序可能保证不了,比如先给A发信息,后给B发信息,但是微信后台服务器有可能先收到发给B的信息,然后再收到发给A的信息。这种乱序的情况下,事件时间是就是发送的时间,处理时间就是微信后台收到信息的时间,显然事件时间和处理时间不一样。而且微信后台为了维护对某一个聊天的Session,维护这个时序需要知道聊天发送信息的时间,需要知道事件时间的推进情况,这样才能够将发送的信息做排序,而不是依靠微信后台服务器的时间,这两个时间本质是不一样的。按照服务器时间有可能无法还原本地和朋友聊天时序的关系,所以说微信从个人角度维护聊天事件时间进度的关系,而这个进度关系和后台服务器处理的时间两个从本质上是不相同的,需要依靠用户的时间判断推进情况,即什么消息在前,什么消息在后,这就是事件时间和处理时间两本质不一样,虽然共享一个时钟,但是这两个时间从本质上是不一样的,在流处理上是需要额外处理的。特别是在系统流处理发生故障的情况下,对这两个时间的处理以及恢复机制也不一样,需要引入一套机制,比如在处理函数、处理事件程序里面,会存储两套时间,一个是事件时间,一个是处理时间, 这个是在其他应用程序里面不可理解的,为什么存两套时间,是因为流处理理论上需要维护这两套时间的各自推进关系。
窗口则是因为处理对象DataStream是没有尽头的,没有尽头的数据处理的结果要及时看到,不能因为没有尽头,就一直等。比如双11,一直等到12号凌晨才发布,这显然和我们做数据处理或数据运营相矛盾,需要及时发现处理的结果,这就需要窗口。需要在什么窗口下计算结果,如每分钟计算一次流量信息和计算一次订单数量,再将所有订单进行累加,就可以及时发现现在的运营情况。窗口有很多的开窗机制,比如常见的根据事件开窗,因为每个用户所做的一序列动作是有开始和结束。
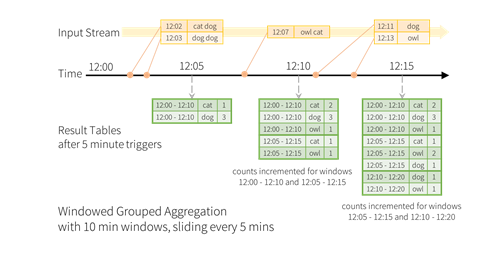
继续看之前的例子,在12:02和12:03分别接收到数据,然后在12:05做处理,处理的结果是在这个窗口区间内收到了两条记录,分别是cat和dog的数量,然后再12:10分又做一次集合操作,由于在12:07收到了一条记录,窗口是滑动窗口,在12:10分左右各五分钟产生了一批窗口数据,12:15也一样。
这个是基于append操作,而且有窗口时间重叠,在做dog集合的情况下,需要处理窗口重叠。而且在这个结果下查询是持续的查询,这个操作是没有结束点的,一直在产生结果信息,而没有最终的结果信息。
10.4 事件迟到
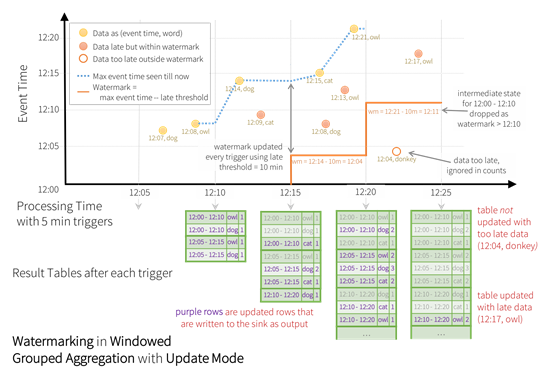
时间的迟到,如图,事件是在12:04时间发生的,但是被观测到却是在12:11,12:11被观测到的数据会产生一个迟到的事件,这个迟到的事件,根据时间事件开窗的话,应该算到12:00-12:10分窗口内,后续需要加到12:00-12:10分这个窗口内,这就是时间迟到对流处理应用程序、引擎带来的架构的难点,需要处理迟到和早到时间。

10.5 水印
上图中为了生成12:00-12:10窗口最终数据,不能因为有迟到时间,就没有最终结论,为了让窗口有一个结束点,同时窗口结束点也是资源释放点,需要将这些数据存起来,为了达到这个目的,需要有一个水印作为事件时间的推进器,反映小于这个时间的事件都已经被观测到。比如在12:14有一个水印,通过水印得知小于12:10的数据都已经观测到了,那么12:00-12:10分的窗口可以关闭了,并计算出最终的结果,这就是水印要达到的目标。
如何设计水印才能达到事件时间推进的作用,需要领域知识,同时也需要对应用系统、业务系统、软件结构、硬件资源做一个综合考量,才能设计出一个比较符合实际的水印。
流处理理论是复杂的,而且流处理正在高速发展,可以说流处理将是大数据处理引擎的下一个革新点,也是快速发展点,将来能够在流处理上做更多事情,或者说流处理能够更多地取代业务系统某些功能点,如果现在不掌握流处理,将来做业务系统某些功能模块将会被流处理取代,因为流处理看见什么做什么集合,而且是简单的。
10.6 进一步学习材料
想进一步学习流处理,可以参考这本书:《深入理解Flink实时大数据处理实践》,这本书从理论和实践层次给出了Flink最新的技术发展,可以说是理解流处理特别是理解Flink框架的核心书籍。同时这本书籍并没有深入绑定API版本,是从思想层面、理论层面、实践层面解决怎么理解流处理,怎么实际操作Flink编写应用程序实践性的一本书籍。
