完整目录、平台简介、安装环境及版本:参考《Spark平台(高级版)概览》
十一、集群环境对称处理
之前安装Anaconda和Jupyter环境时,只在app-11环境上安装,而且在app-11上去提交standalone集群处理,且所有的处理都是用spark.sql,并没有使用到Python相关的处理函数,目前这种调用是没有问题的。
但是如果我们的处理程序,特别是Pyspark涉及到一些用Python语言编写的处理程序的话,那么我们在集群上提交应用程序的时候会出现一些问题。典型的问题就是版本不一致,因为Anaconda的版本是3.7,但是本地Python版本是2.7,当我们提交应用程序到集群时,在驱动节点会发现版本不一致,运行会产生异常。如果程序比较简单的情况下,能兼容Python2和Python3,这个程序是可以正常运行的,如果不能兼容的话,程序会出现错误。
为此需要在app-12和app-13安装一套和app-11一致的环境,但是这个安装可以省略一些东西,有一个最小的安装步骤:
- 安装Anaconda并设置环境变量;
- 如果涉及到画图以及将Spark对象转换到Pandas对象,还需要安装Pyarrow;
- 如果需要画漏洞这种图,需要安装Pyecharts包。
安装过程参考前面部分,如果不想重新做,可以直接下载资源Spark虚拟机镜像“9Spark.7z”。
11.1 安装Anaconda
由于后续执行action需要用到python,所以此处在app-12和app-13节点上安装Anaconda。
11.1.1 app-12
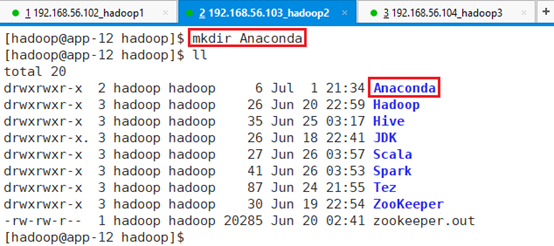
在/hadoop目录下创建目录:mkdir Anaconda
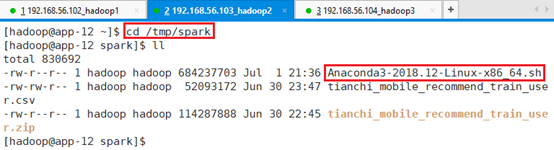
在/tmp目录下创建spark目录,存放安装包:mkdir spark,如果spark已经存在则不需要创建。
上传文件Anaconda3-2018.12-Linux-x86_64.sh到/tmp/spark目录
赋予程序可执行权限:
chmod a+x Anaconda3-2018.12-Linux-x86_64.sh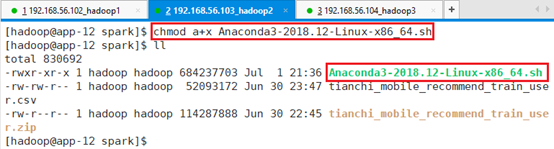
使用静默方式安装程序:
./Anaconda3-2018.12-Linux-x86_64.sh -b -p /hadoop/Anaconda/Anaconda3-2018.12-Linux-x86_64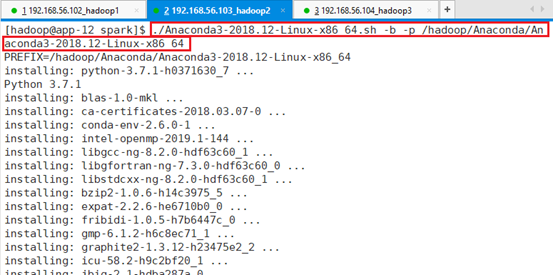
安装位置为:/hadoop/Anaconda/Anaconda3-2018.12-Linux-x86_64,安装过程比较长,安装了很多个软件包。
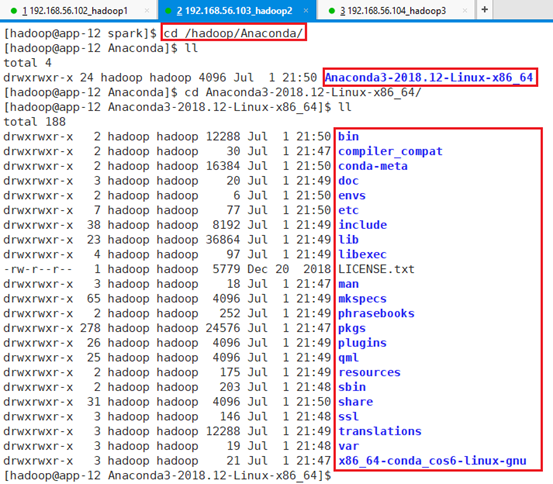
11.1.2 app-13
在/hadoop目录下创建目录:mkdir Anaconda
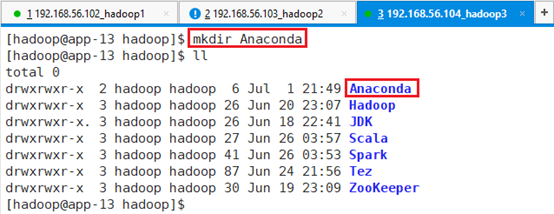
在/tmp目录下创建spark目录,存放安装包:mkdir spark,如果spark已经存在则不需要创建。

上传文件Anaconda3-2018.12-Linux-x86_64.sh到/tmp/spark目录

赋予程序可执行权限:
chmod a+x Anaconda3-2018.12-Linux-x86_64.sh
使用静默方式安装程序:
./Anaconda3-2018.12-Linux-x86_64.sh -b -p /hadoop/Anaconda/Anaconda3-2018.12-Linux-x86_64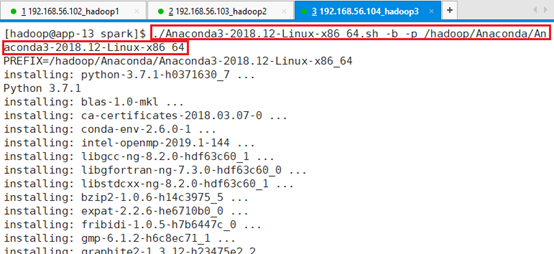
安装位置为:/hadoop/Anaconda/Anaconda3-2018.12-Linux-x86_64,安装过程比较长,安装了很多个软件包。
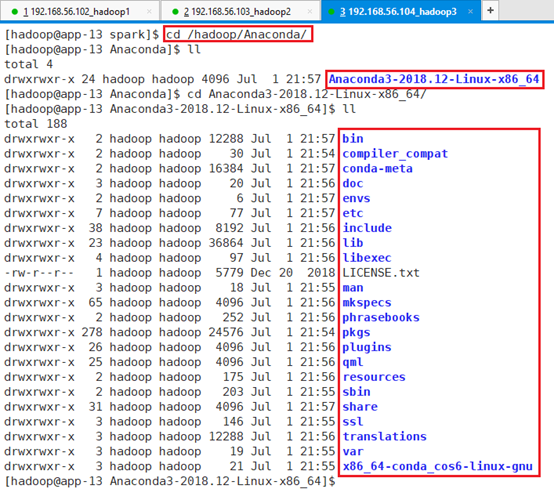
11.1.3 环境变量
此处,为了一致性,将环境变量拷贝到app-12和app-13
scp ~/.bashrc app-12:/home/hadoop/
scp ~/.bashrc app-13:/home/hadoop/
并启用:source ~/.bashrc


11.1.4 确认
查看python版本:python –version

